表形式マルチエージェントQ学習における身体性に起因する協調レジーム
マルチエージェント強化学習において、中央集中型の学習は協調性と安定性を向上させる標準的な手法とされてきましたが、本研究は表形式の捕食者・被食者環境を用いた厳密な検証により、この定説が物理的制約下では必ずしも成立しないことを明らかにしました。
TL;DR(結論)
マルチエージェント強化学習において、中央集中型の学習は協調性と安定性を向上させる標準的な手法とされてきましたが、本研究は表形式の捕食者・被食者環境を用いた厳密な検証により、この定説が物理的制約下では必ずしも成立しないことを明らかにしました。 エージェントの移動速度やスタミナといった具体的な身体的制約を導入した実験の結果、中央集中型学習は独立型学習に対して一貫した優位性を示せず、特定の条件下ではむしろ独立型の方が高いパフォーマンスを発揮し、過度な協調が戦略的な柔軟性を損なうことが示されました。 この知見は、協調メカニズムの有効性がエージェントの役割や物理的な運動レジームに強く依存していることを示唆しており、身体的制約が存在する実用的なシステム設計において、中央集中型の手法を無批判に採用することのリスクを警鐘する重要な成果となっています。
なぜこの問題か
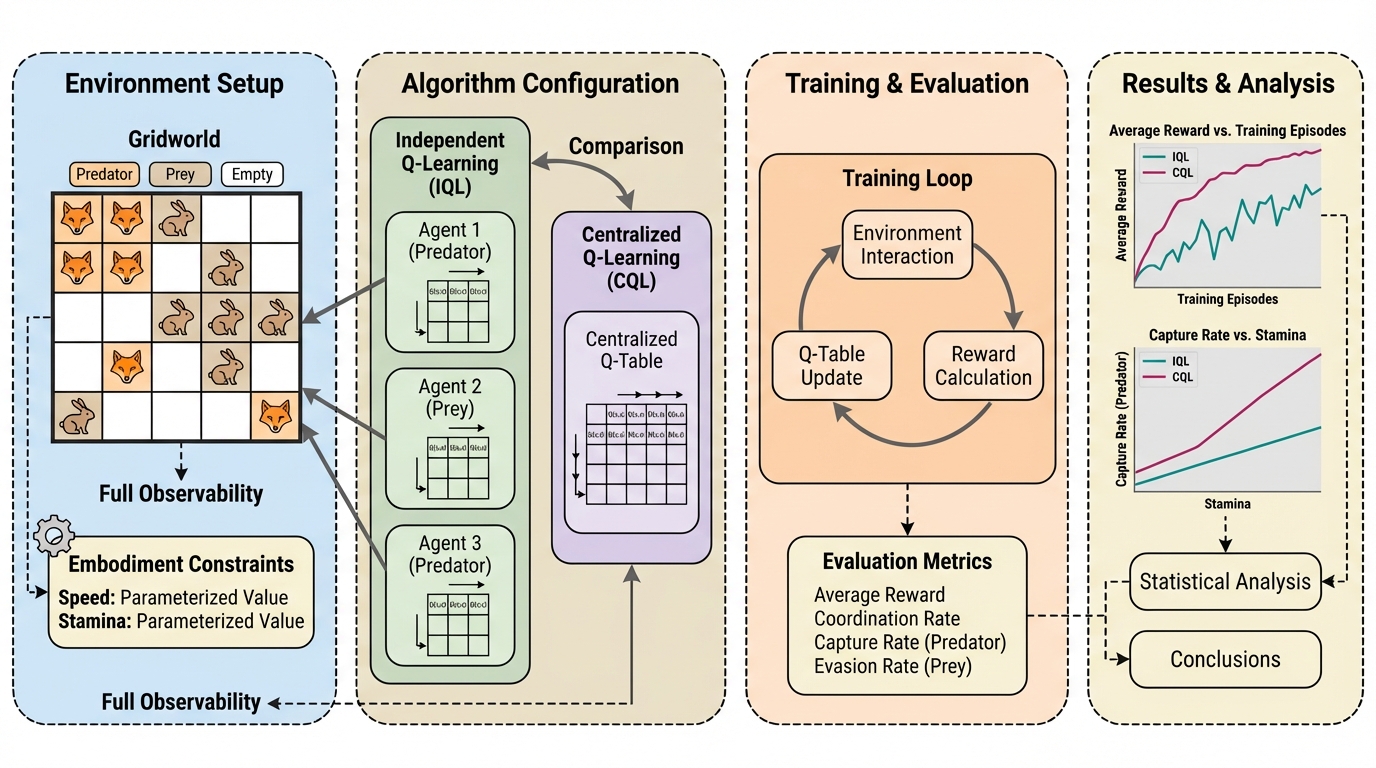
マルチエージェント強化学習(MARL)の分野において、中央集中型のトレーニングは、エージェント間の協調を促進し、学習の非定常性を解消して安定性を向上させるための標準的な設計選択として広く受け入れられてきました。 多くの既存研究では、中央集中型の方が独立型よりも優れているという仮定に基づいてアルゴリズムが設計されていますが、この前提が制御された条件下で厳密に検証されることはほとんどありませんでした。 特に、エージェントが物理的な身体を持ち、移動速度やスタミナといった具体的な制約(身体的制約)の下で行動する場合、協調の強化が必ずしも全体のパフォーマンス向上に直結するとは限りません。 現実世界のタスクにおいては、エージェントの行動タイミングやリソースの配分が密接に関連し合っており、過度な協調構造が逆に戦略的な柔軟性を奪い、小さなエラーを増幅させる「負債」となる可能性があります。 また、従来のベンチマークの多くは対称的な協力関係に焦点を当てており、捕食者と被食者のような非対称な役割を持つ環境において、協調メカニズムがどのように機能するかについては十分に理解されていませんでした。…
核心:何を提案したのか
本研究では、エージェントの速度やスタミナに関する明示的な身体的制約の下で、独立型Q学習(IQL)と中央集中型Q学習(CQL)を直接比較する枠組みを提案しました。 分析の舞台として、完全な観測可能性を持つ表形式(タブラ)の捕食者・被食者グリッドワールドを採用し、関数近似や表現学習による交絡効果を完全に排除した状態で協調の質を評価しました。 これにより、学習のパフォーマンス差がアルゴリズムの表現能力や最適化の不備ではなく、純粋に「協調の構造」と「身体的制約」の相互作用から生じていることを特定できるようにしました。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related