UniGRec: ソフト識別子を用いたエンドツーエンド最適化による統一生成型推薦
生成型推薦において、従来のトークナイザーと推薦モデルを個別に最適化する手法に対し、微分可能な「ソフト識別子」を導入することで、両者を単一の推薦目的関数でエンドツーエンドに同時最適化する新フレームワーク「UniGRec」が提案された。
TL;DR(結論)
生成型推薦において、従来のトークナイザーと推薦モデルを個別に最適化する手法に対し、微分可能な「ソフト識別子」を導入することで、両者を単一の推薦目的関数でエンドツーエンドに同時最適化する新フレームワーク「UniGRec」が提案された。 この手法は、学習時のソフトな表現と推論時のハードな決定の乖離を埋める「アニール推論アライメント」、特定のコードワードへの偏りを防ぎ識別子の崩壊を抑制する「コードワード均一化正則化」、そして軽量な教師モデルから協調フィルタリングの知識を継承する「二重協調蒸留」の3技術で構成される。 実世界のデータセットを用いた広範な実験の結果、UniGRecは既存の段階的学習や交互最適化を用いる最先端手法を一貫して上回る性能を示し、トークナイザーを推薦タスクに直接適合させることの有効性と、情報の損失を最小限に抑える設計の妥当性が実証された。
なぜこの問題か
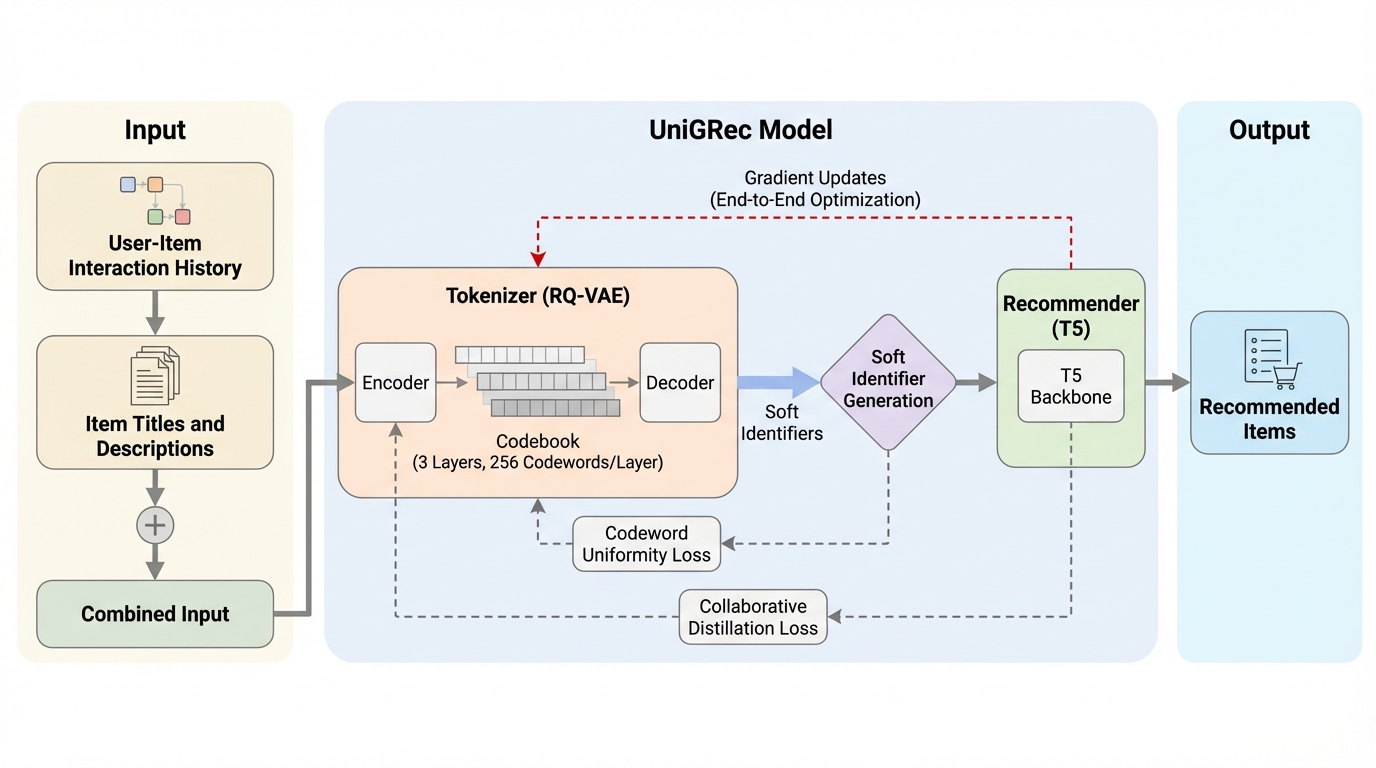
従来の生成型推薦システムは、アイテムをトークン列(識別子)に変換するトークナイザーと、その識別子を用いて次アイテムを予測する推薦モデルの2つのコンポーネントで構成されている。しかし、初期の研究ではこれら2つの要素が切り離されており、まずトークナイザーを事前に学習して固定し、その後に推薦モデルを学習するという「段階的学習」のパイプラインが一般的であった。この手法では、トークナイザーが下流の推薦タスクの目的を考慮せずに構築されるため、推薦の文脈に適応できない硬直した識別子が生成されるという根本的な課題がある。推薦モデルがどれほど高性能であっても、入力となる識別子が推薦に適していなければ、全体の性能は制限されてしまう。 この制限を解決するために、トークナイザーと推薦モデルを交互に更新する「交互最適化」の手法も提案されているが、これらはエポックごとに非同期的な更新を行うに留まっており、真の意味でのエンドツーエンドな統合には至っていない。また、従来の「ハードな識別子」、すなわち離散的なトークン割り当ては微分不可能であるため、推薦の損失関数からトークナイザーへ直接勾配を伝播させることが困難であった。…
核心:何を提案したのか
本論文では、ソフト識別子を活用することでトークナイザーと推薦モデルをエンドツーエンドで最適化する統一フレームワーク「UniGRec(Unified Generative Recommendation)」を提案している。このアプローチの核心は、アイテムを単一の離散的なトークンとして扱うのではなく、コードブック内の全コードワードに対する割り当て確率の分布として表現する「ソフト識別子」の導入にある。これにより、量子化プロセスが微分可能となり、最終的な推薦損失をトークナイザーの学習に直接利用できるパスが形成される。つまり、推薦精度を最大化するように、アイテムの表現(トークン割り当て)そのものを動的に洗練させることが可能になった。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related