ノイズの多いラベル学習のためのノイズ補償型シャープネス考慮最小化 NCSAM
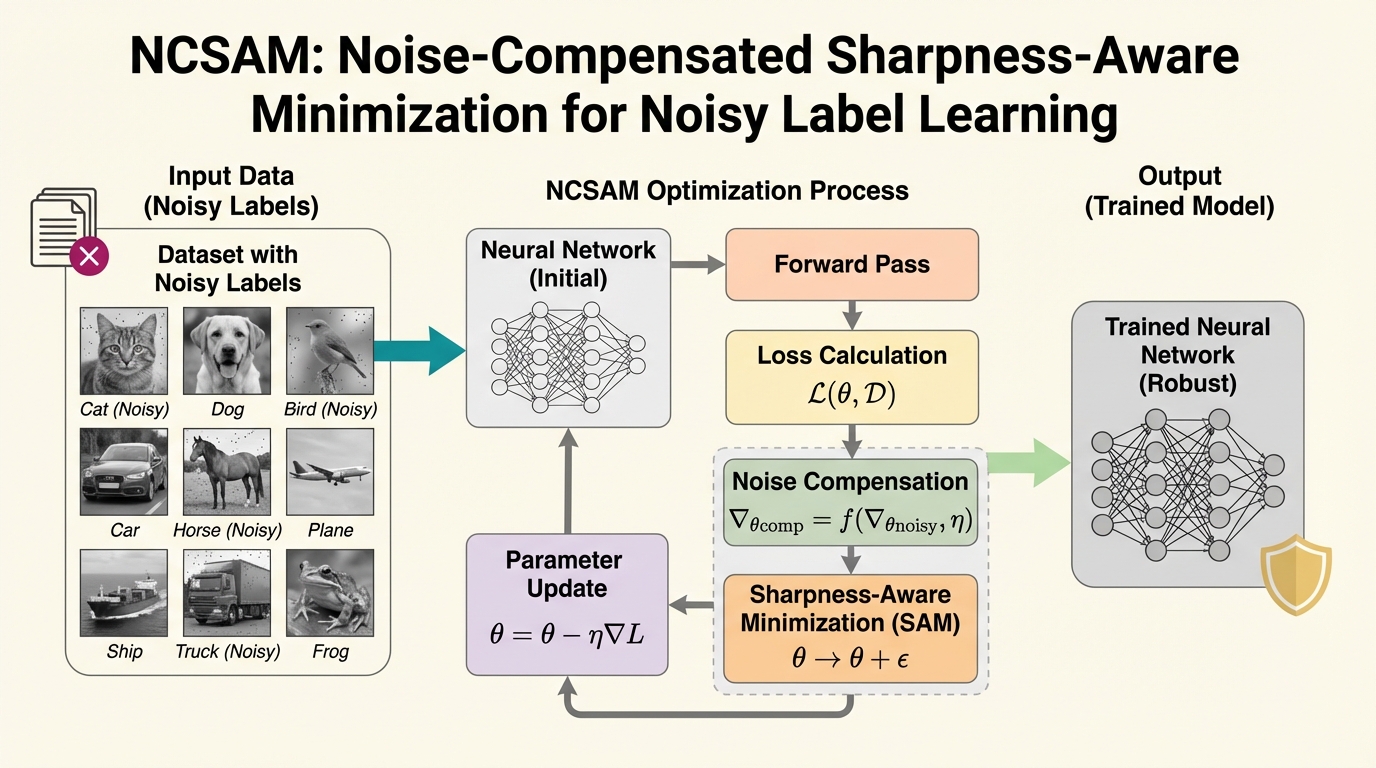
ウェブから収集されたデータ等に含まれる誤ったラベル(ノイズ)は、深層学習モデルに偏った勾配を導入し、汎化性能を著しく低下させるという深刻な課題があります。 本研究は、損失関数の平坦性とラベルノイズの関係を理論的に解析し、ノイズによる勾配の歪みが従来の平坦化手法(SAM)の摂動を狂わせることを解明した上で、その歪みを明示的に補正する新手法NCSAMを提案しました。 NCSAMは、モデルの予測自信度に基づきノイズをシミュレートしてパラメータの偏差を相殺することで、複雑なラベル修正なしに、クリーンなデータセットでの学習に近い高い堅牢性と汎化性能を達成しました。
TL;DR(結論)
ウェブから収集されたデータ等に含まれる誤ったラベル(ノイズ)は、深層学習モデルに偏った勾配を導入し、汎化性能を著しく低下させるという深刻な課題があります。 本研究は、損失関数の平坦性とラベルノイズの関係を理論的に解析し、ノイズによる勾配の歪みが従来の平坦化手法(SAM)の摂動を狂わせることを解明した上で、その歪みを明示的に補正する新手法NCSAMを提案しました。 NCSAMは、モデルの予測自信度に基づきノイズをシミュレートしてパラメータの偏差を相殺することで、複雑なラベル修正なしに、クリーンなデータセットでの学習に近い高い堅牢性と汎化性能を達成しました。
なぜこの問題か
現代の深層学習において、大規模なデータセットの構築は不可欠な要素となっていますが、現実世界のデータはウェブサイトからの自動収集やクラウドソーシングを通じて得られるため、必然的に誤った注釈や汚染されたラベルが含まれてしまいます。このようなノイズの多いラベルを用いて学習を行うと、訓練中に偏った勾配が導入され、モデルが誤った教師信号を記憶してしまうことで、未知のデータに対する汎化性能が著しく低下するという深刻な課題が生じます。既存の研究ではこの問題に対し、主に三つのアプローチが取られてきました。第一に、初期段階の学習損失や予測の確信度を利用して信頼できるサンプルを特定するサンプル選択手法、第二に、誤った注釈を明示的に修正したり疑似ラベルを生成したりするラベル修正手法、そして第三に、堅牢な損失関数の設計やデータ拡張を用いる正則化手法です。しかし、これらの手法の多くは「ニューラルネットワークはノイズよりも先にクリーンなサンプルを記憶する」という経験的な初期学習効果に依存しており、どの段階を初期と見なすかという判断は理論的な根拠に乏しいヒューリスティックなものに留まっていました。…
核心:何を提案したのか
本論文では、ノイズラベル学習の課題に対して、最適化の観点から新しい理論的アプローチを提案しています。具体的には、PAC-Bayes学習フレームワークを用いて、ラベルノイズと損失関数の平坦性の間の根本的な関係を理論的に解析しました。この解析を通じて、適切にシミュレートされたラベルノイズが、実は汎化性能とノイズに対する堅牢性の両方を相乗的に高める可能性があることを示しました。この理論的洞察に基づき提案されたのが、NCSAM(Noise-Compensated Sharpness-Aware Minimization)です。NCSAMの核心は、従来のSAMが持つパラメータ摂動の仕組みを利用しつつ、ノイズによって生じる勾配の歪みを明示的に補償することにあります。従来の平坦化手法がノイズ環境下で最適ではない理由として、ノイズに起因する勾配のバイアスとパラメータ摂動の方向が不一致を起こしていることを突き止めました。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related