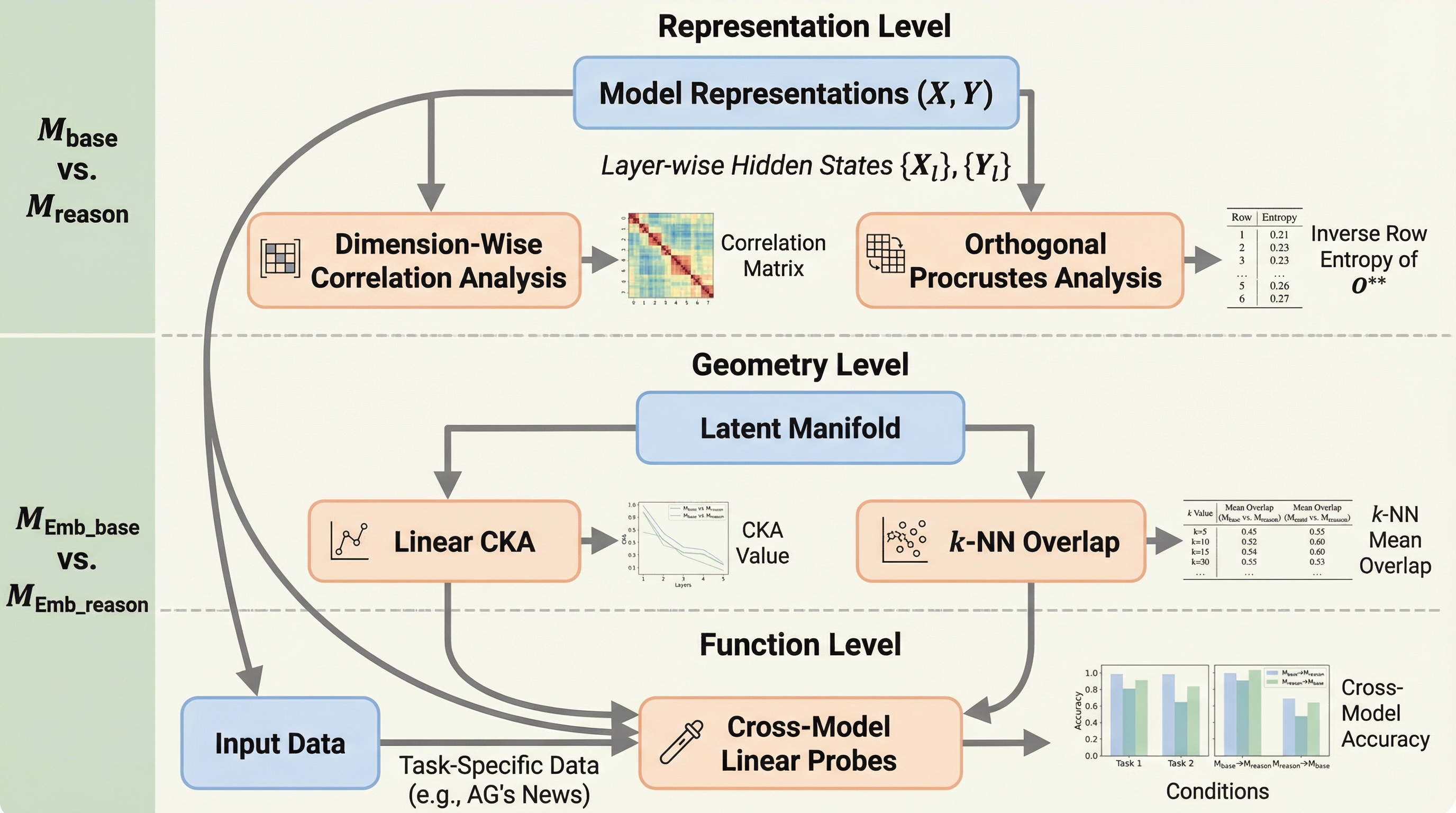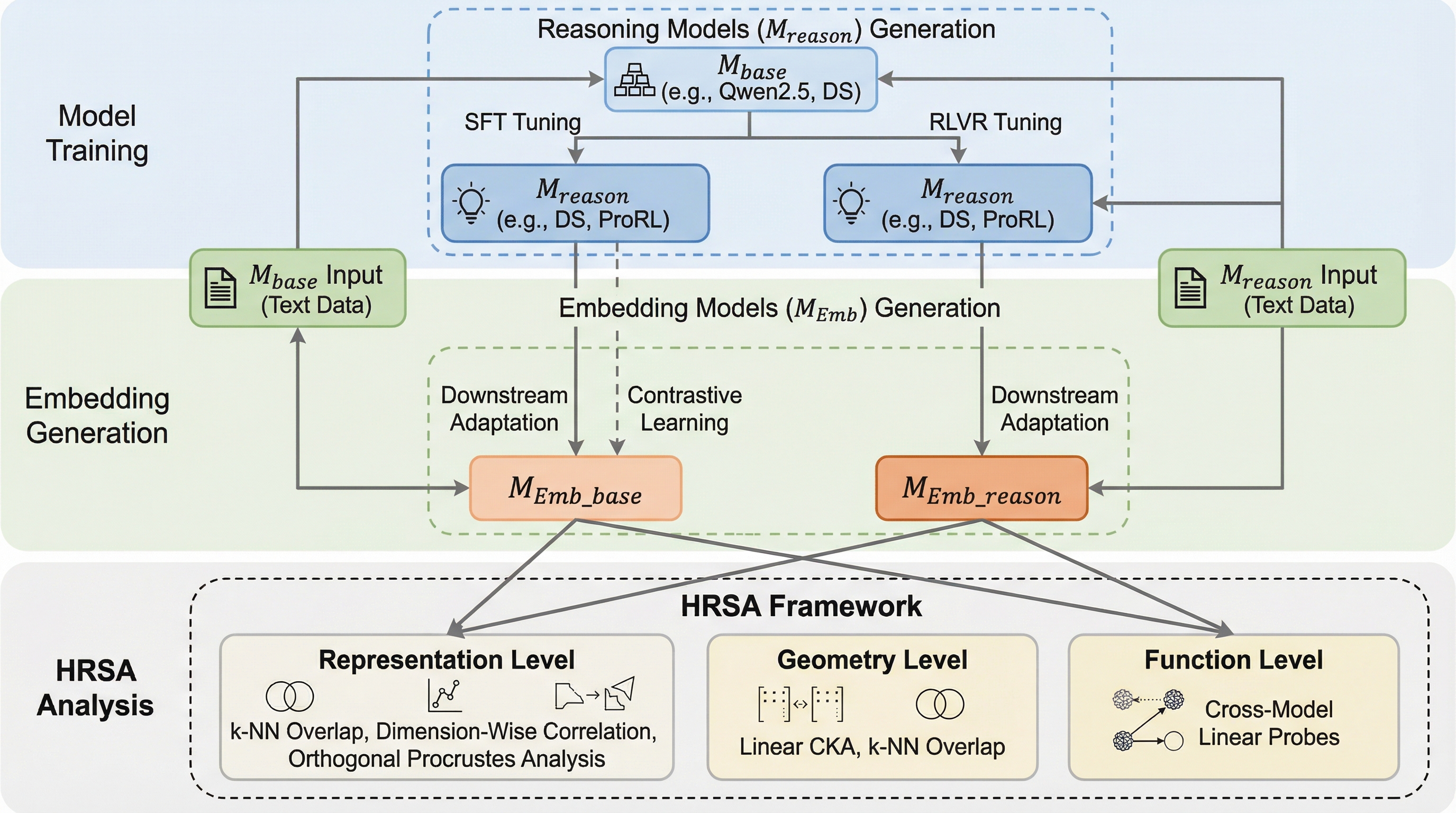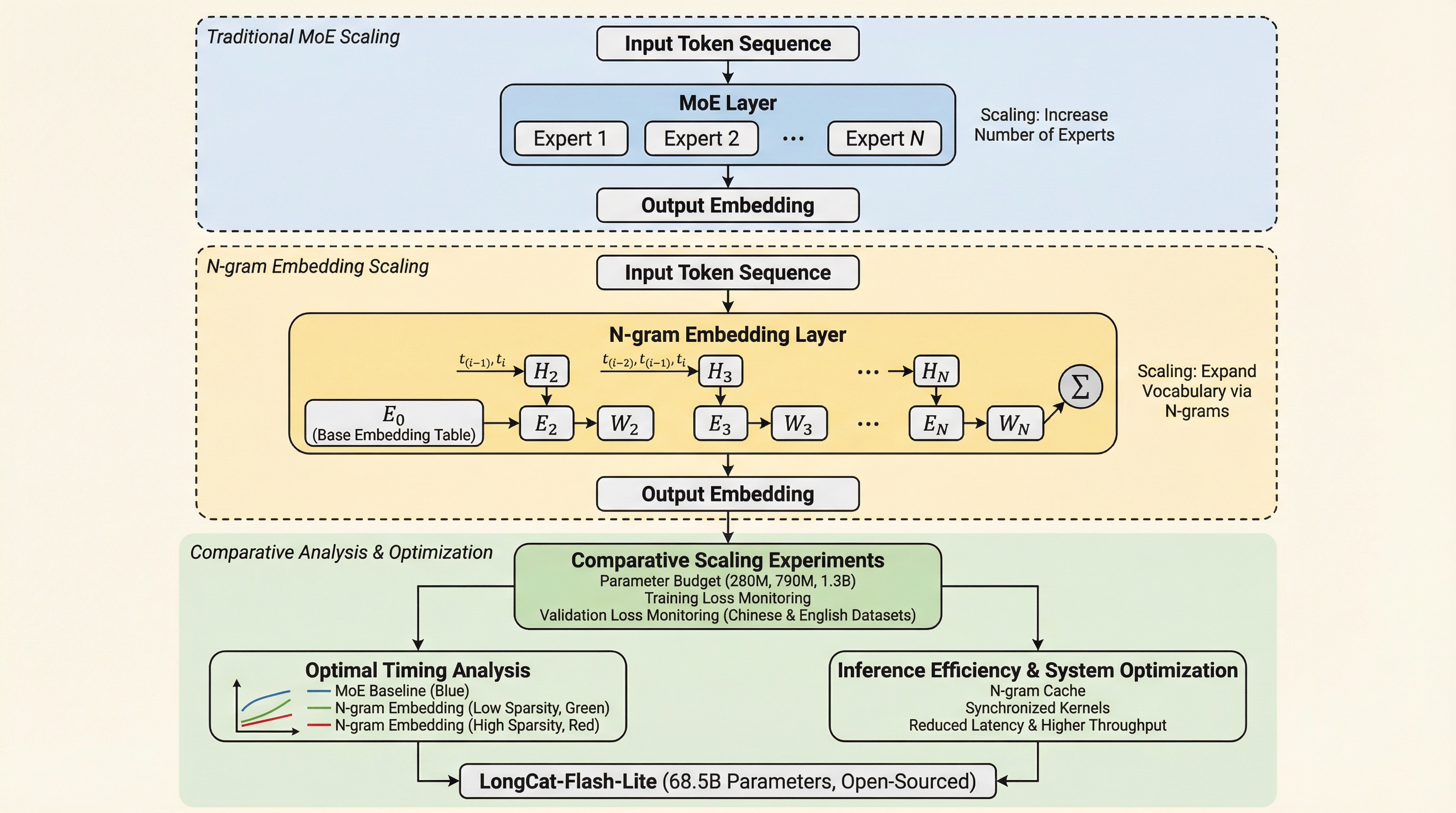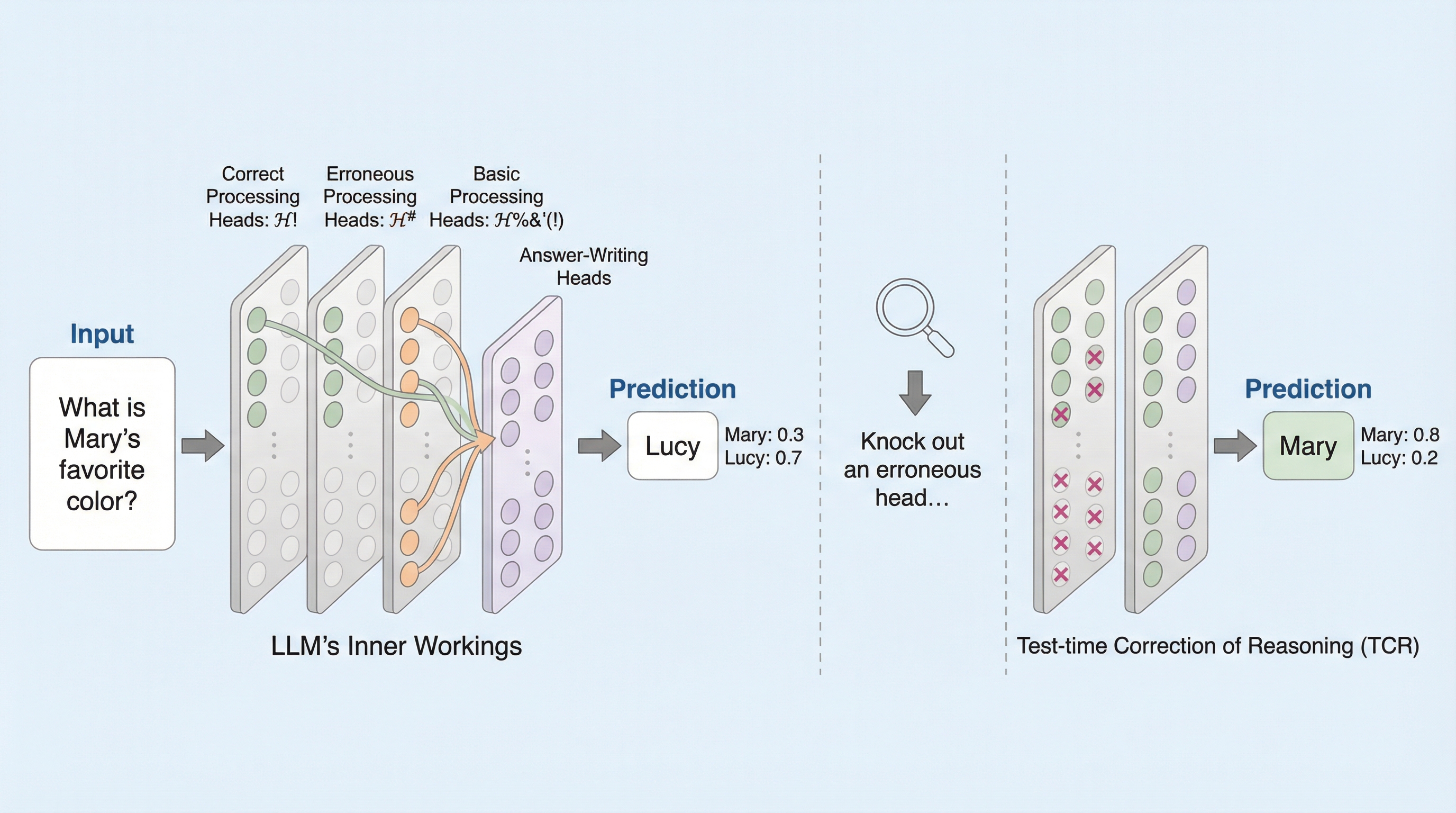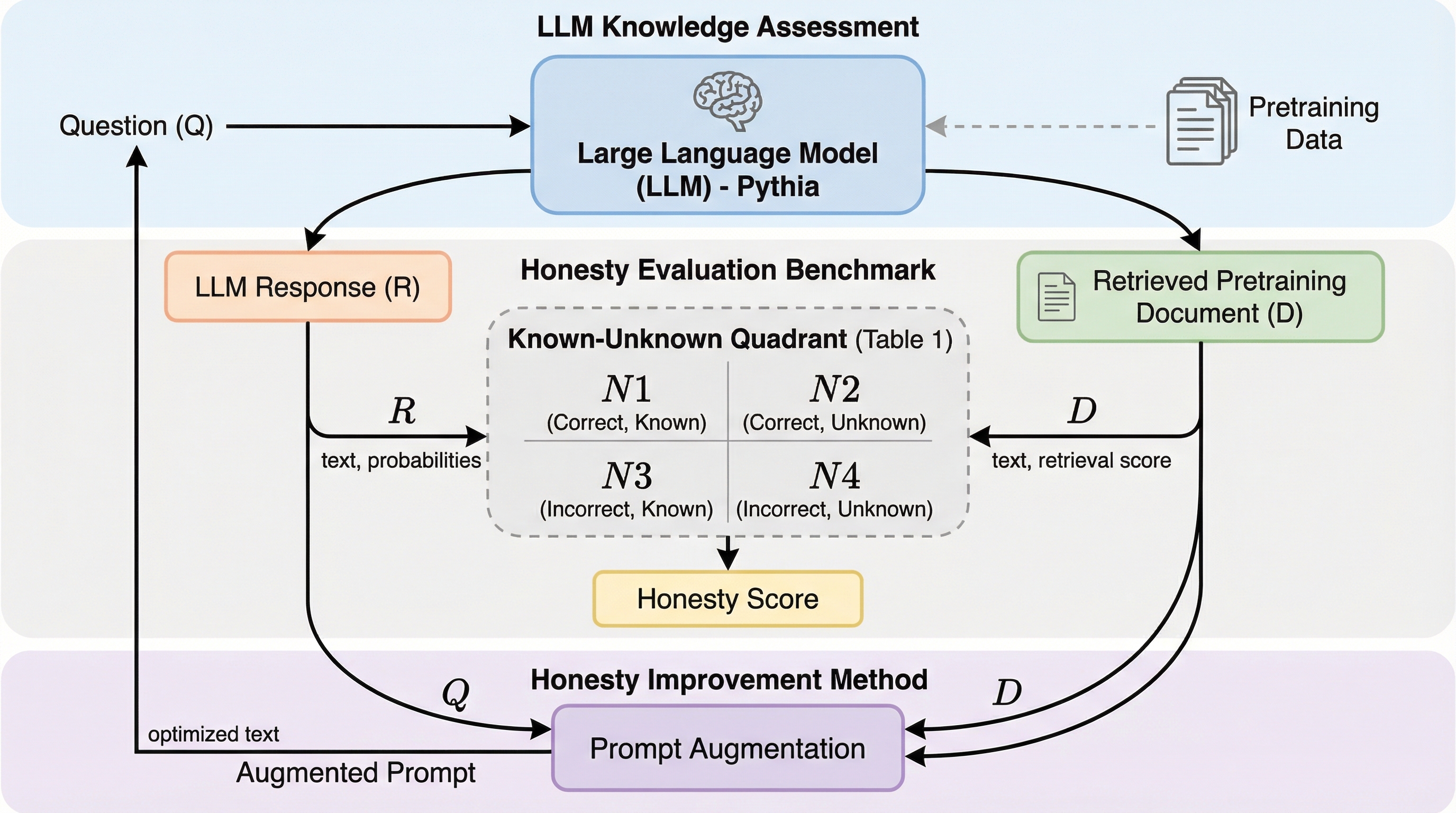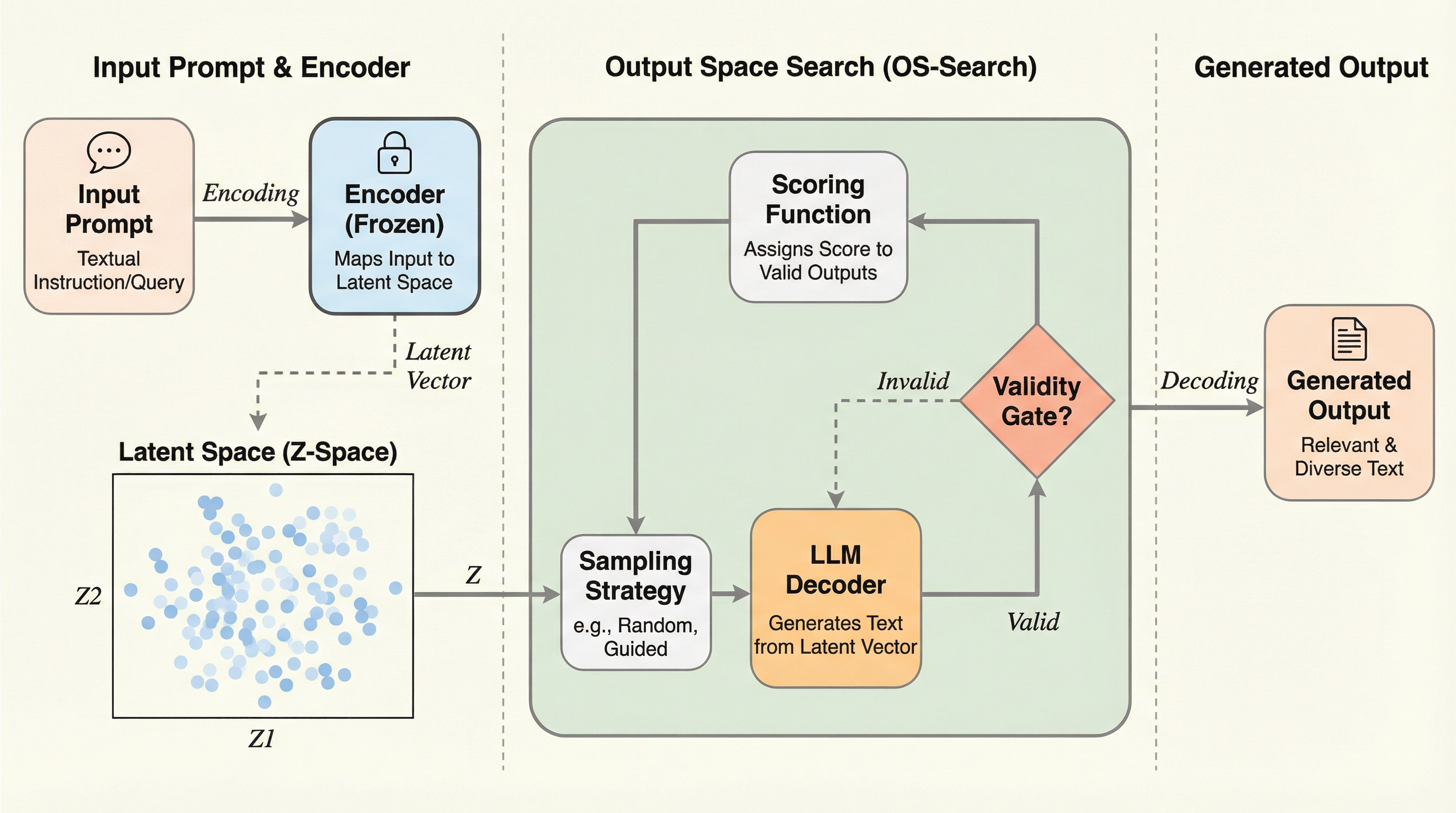
出力空間探索:フリーズされたエンコーダによって定義された出力空間におけるLLM生成の標的化
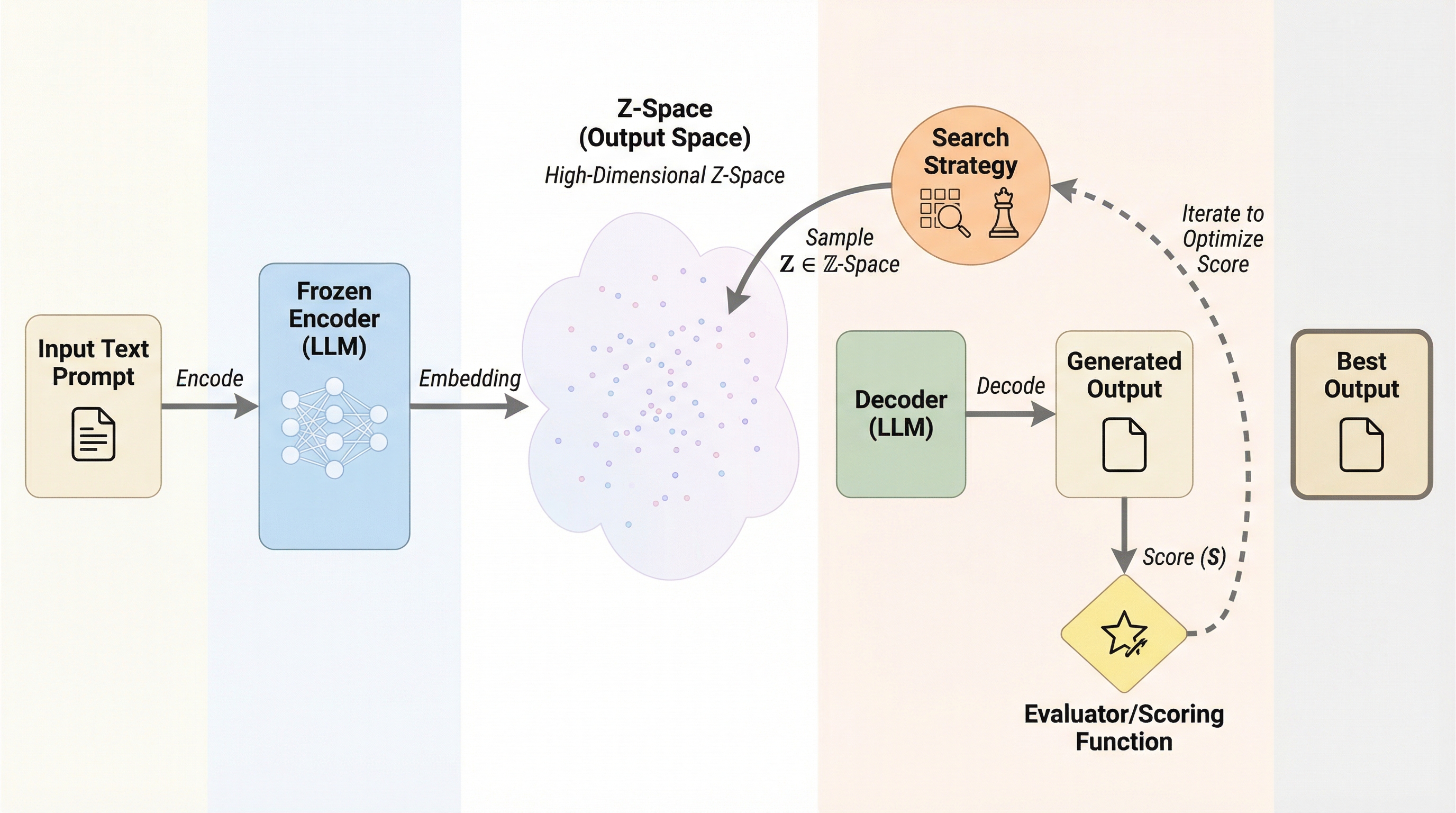
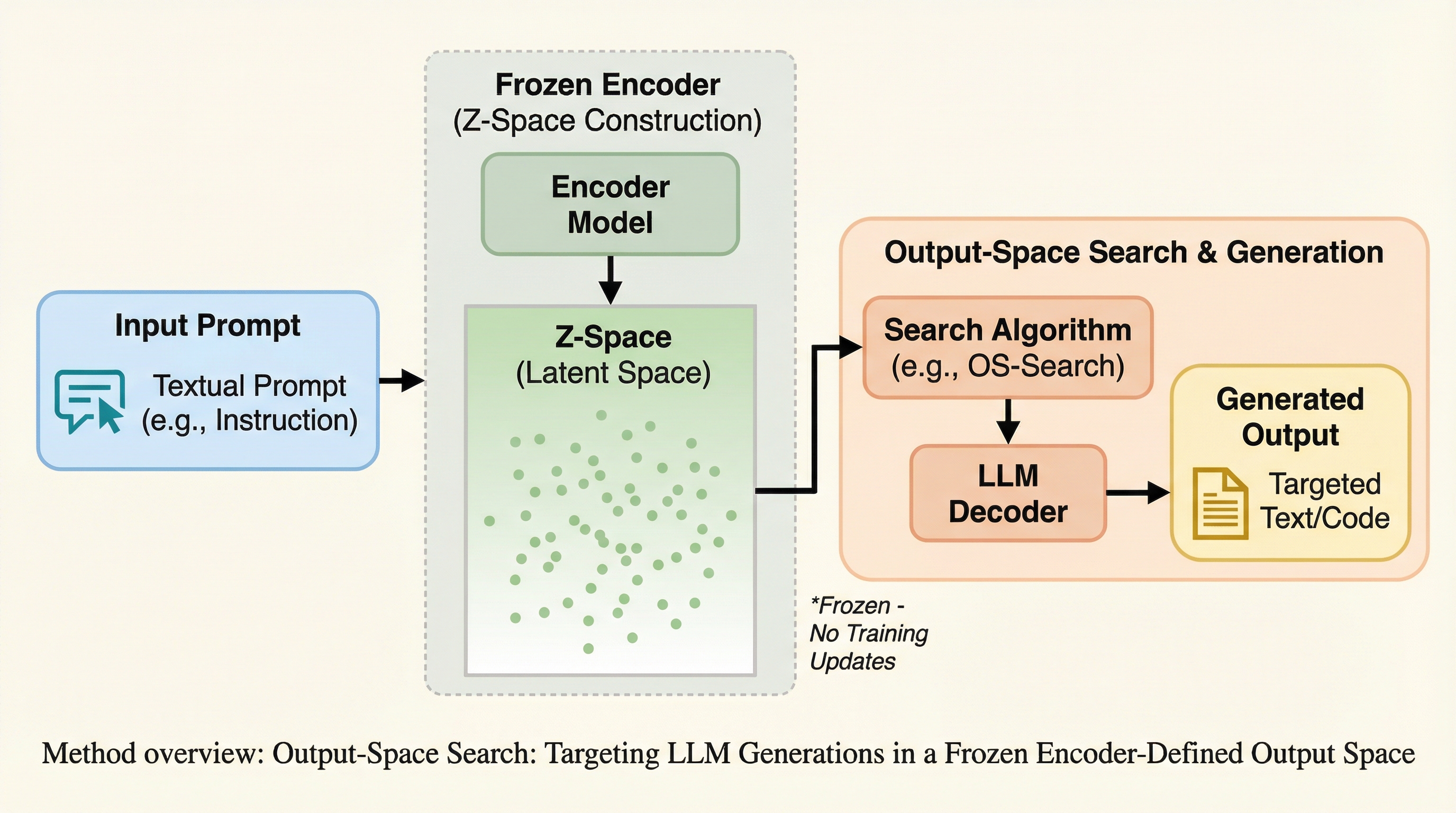
大規模言語モデル(LLM)の生成を、従来の「トークンの逐次的な選択」から、3次元の出力空間(Z空間)における「終点の探索」へと転換する手法「OS-Search」を提案した。 固定されたエンコーダと強化学習(RL)を用いて、指定された座標(z*)の近傍に着地する出力を生成するポリシーを構築し、並列的な多様性探索やブラックボックス最適化を可能にした。 物語生成では従来のプロンプトチェイニングより3.1倍高い多様性を実現し、コード生成では外部評価指標を最大化する最適化に成功するなど、高い制御性と実用性が示された。