出力空間探索:凍結されたエンコーダによって定義された出力空間におけるLLM生成の標的化
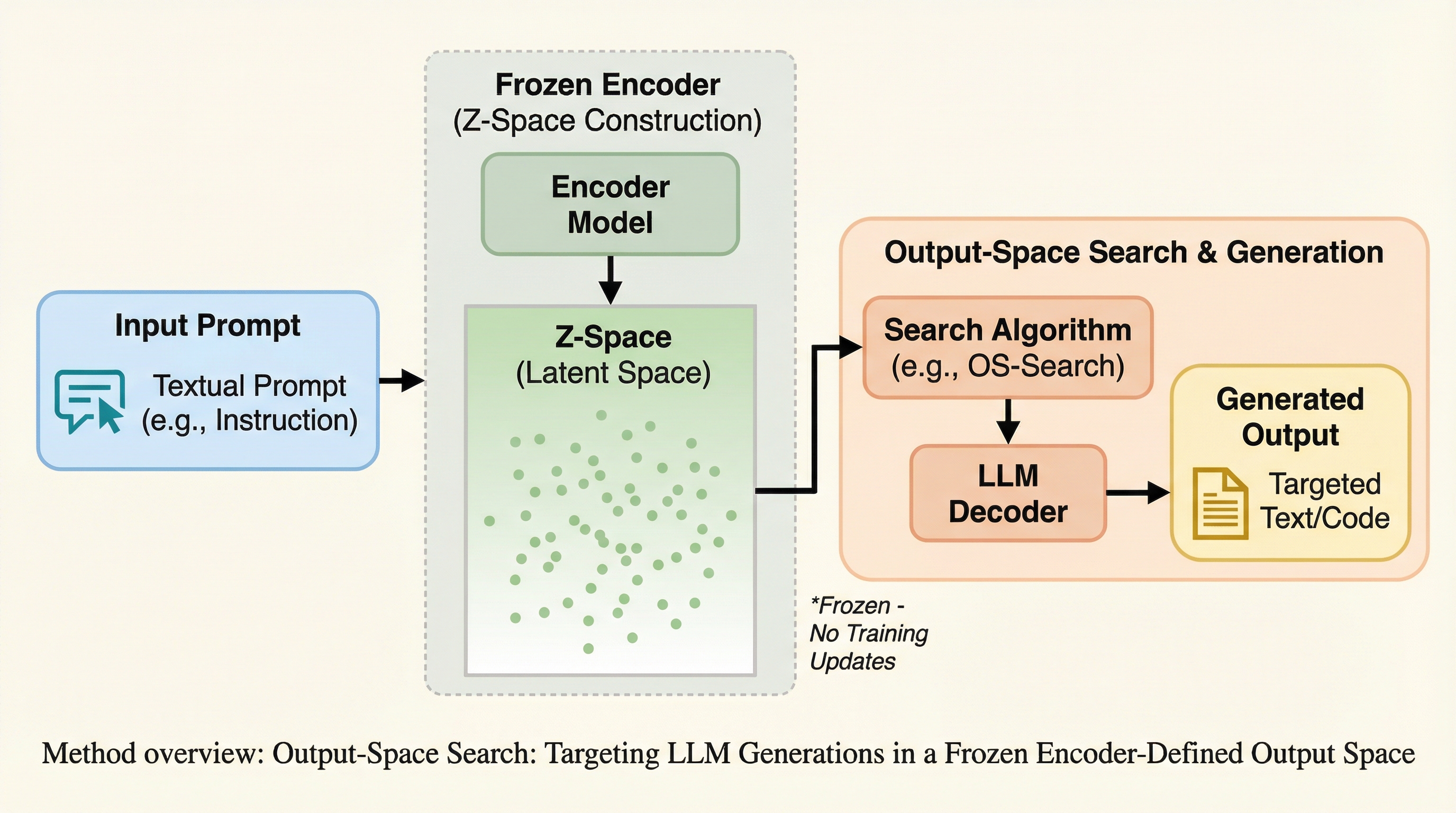
OS-Searchは、LLMの生成プロセスを従来のトークン単位の探索から、固定されたエンコーダが定義する3次元の出力空間(Z空間)における終点探索へと転換する革新的な手法である。 外部ループがターゲット座標を選択し、強化学習で訓練されたポリシーがその近傍に着地する出力を生成することで、パス依存のない並列スイープやブラックボックス最適化を可能にする。 物語生成では従来のプロンプトチェイニングと比較して3.1倍の多様性を実現し、コード生成ではベイズ最適化を用いることで、モデルが学習時に知らなかった外部評価指標のスコアを向上させることに成功した。
TL;DR(結論)
OS-Searchは、LLMの生成プロセスを従来のトークン単位の探索から、固定されたエンコーダが定義する3次元の出力空間(Z空間)における終点探索へと転換する革新的な手法である。 外部ループがターゲット座標を選択し、強化学習で訓練されたポリシーがその近傍に着地する出力を生成することで、パス依存のない並列スイープやブラックボックス最適化を可能にする。 物語生成では従来のプロンプトチェイニングと比較して3.1倍の多様性を実現し、コード生成ではベイズ最適化を用いることで、モデルが学習時に知らなかった外部評価指標のスコアを向上させることに成功した。
なぜこの問題か
現在の大型言語モデル(LLM)はテキストやコードの強力な生成器であるが、実務上の多くのワークフローでは単一の良好なサンプル以上のものが求められている。ユーザーは、多様な下書きや代替案を並列に探索したり、外部のエバリュエーター(ヒューリスティクスや学習済み判定器)を通じてのみ得られるスコアを最大化する出力を探索したりすることを望んでいる。しかし、現在のデコーディング手法はトークンレベルのパスに基づいた制御であり、温度設定やトップpサンプリングなどはサンプリングプロセスを修正するが、これらは本質的にパスに依存した手法である。 実務において、多様性の確保や最適化は、トークン空間での繰り返しサンプリングや、以前の生成結果をコンテキストにフィードバックするアダプティブループ(プロンプトチェイニングやリジェクションサンプリングなど)によって行われている。しかし、これらの手法は逐次的な依存関係を導入したり、コンテキスト長を増大させたりする問題があり、外部ループが直接最適化できるような安定した低次元のインターフェースを提供していない。…
核心:何を提案したのか
本論文では、表現と実行をモジュール化した「Output-Space Search(OS-Search)」を提案している。この手法の核心は、凍結されたエンコーダによって定義される外部の出力空間Zと、指定されたターゲット座標 $z^$ に到達するように強化学習(RL)で訓練されたコントローラーを組み合わせた点にある。まず、表現の側面では、タスクの出力に対する固定座標 $z(x)$ を定義するために、既存の学習済みエンコーダと線形投影(PCAおよびVarimax回転)を使用する。これにより、高次元のテキスト空間を解釈可能な3次元の連続空間に圧縮し、制御の足場を固めている。 次に、実行の側面では、要求されたターゲット $z^$ に基づいて条件付けられた、検索ベースのポリシーを訓練する。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related