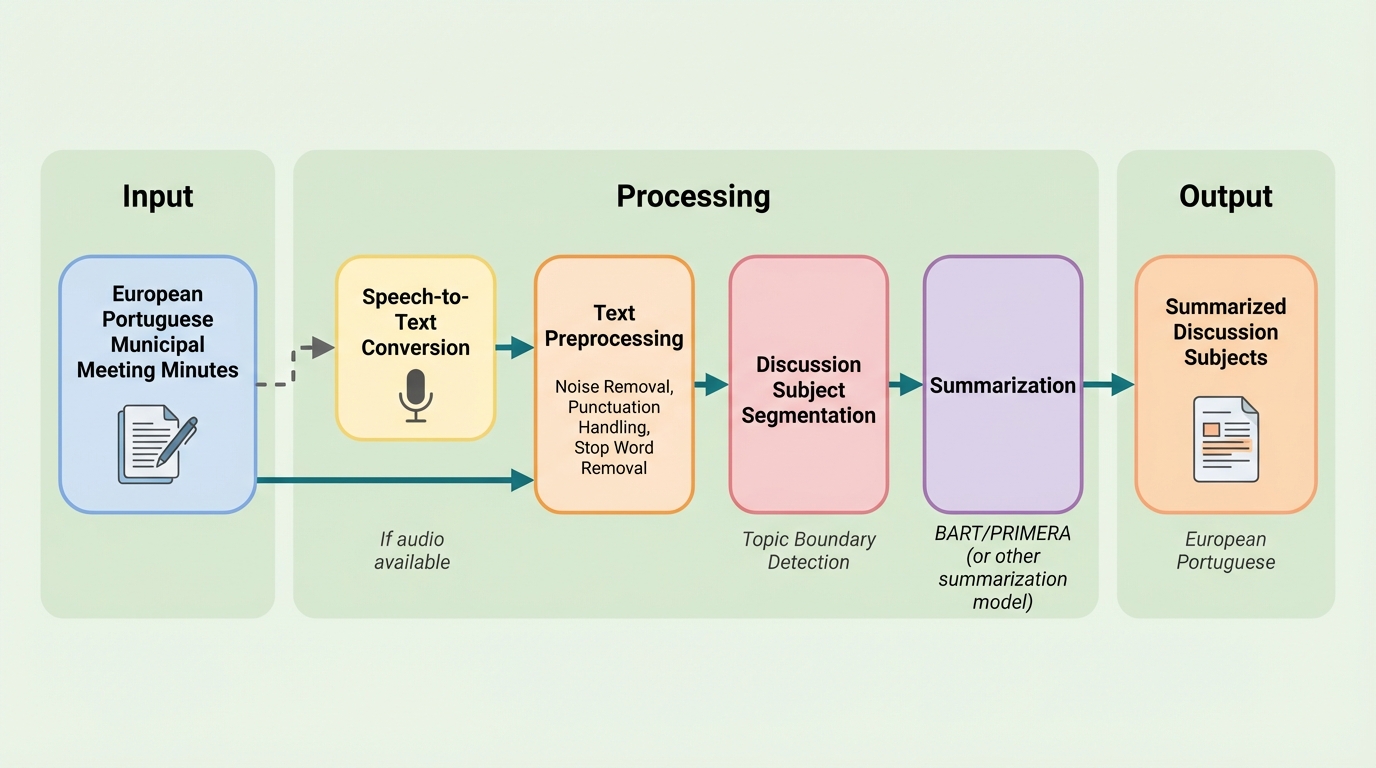
CitiLink-Summ:欧州ポルトガル語の自治体会議議事録を「議題ごと」に要約するためのコーパスとベンチマーク
自治体の会議議事録は意思決定の記録として重要ですが、長く形式的で複数の議題が混在しやすいため、市民が必要箇所を見つけて理解する負担が大きく、議題単位での自動要約を可能にする基盤整備が課題になります。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
自治体の会議議事録は意思決定の記録として重要ですが、長く形式的で複数の議題が混在しやすいため、市民が必要箇所を見つけて理解する負担が大きく、議題単位での自動要約を可能にする基盤整備が課題になります。
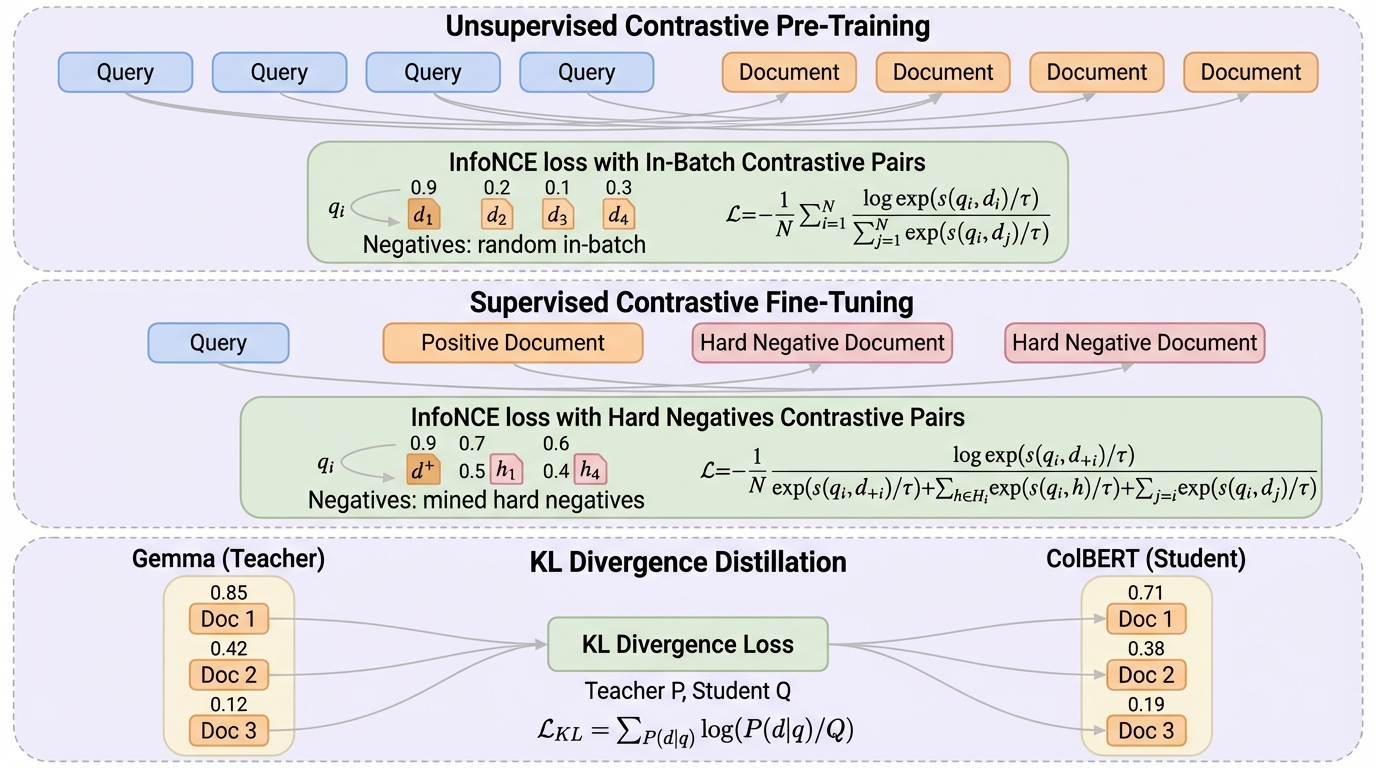
強い単一ベクトル(dense)モデルの上に小さな知識蒸留(KD)だけを足す従来手順だけでは最適に届きにくく、公開データのみでマルチベクトルとして大規模に事前学習したColBERT-Zeroは、BEIR平均のnDCG@10で55.43を得ています。
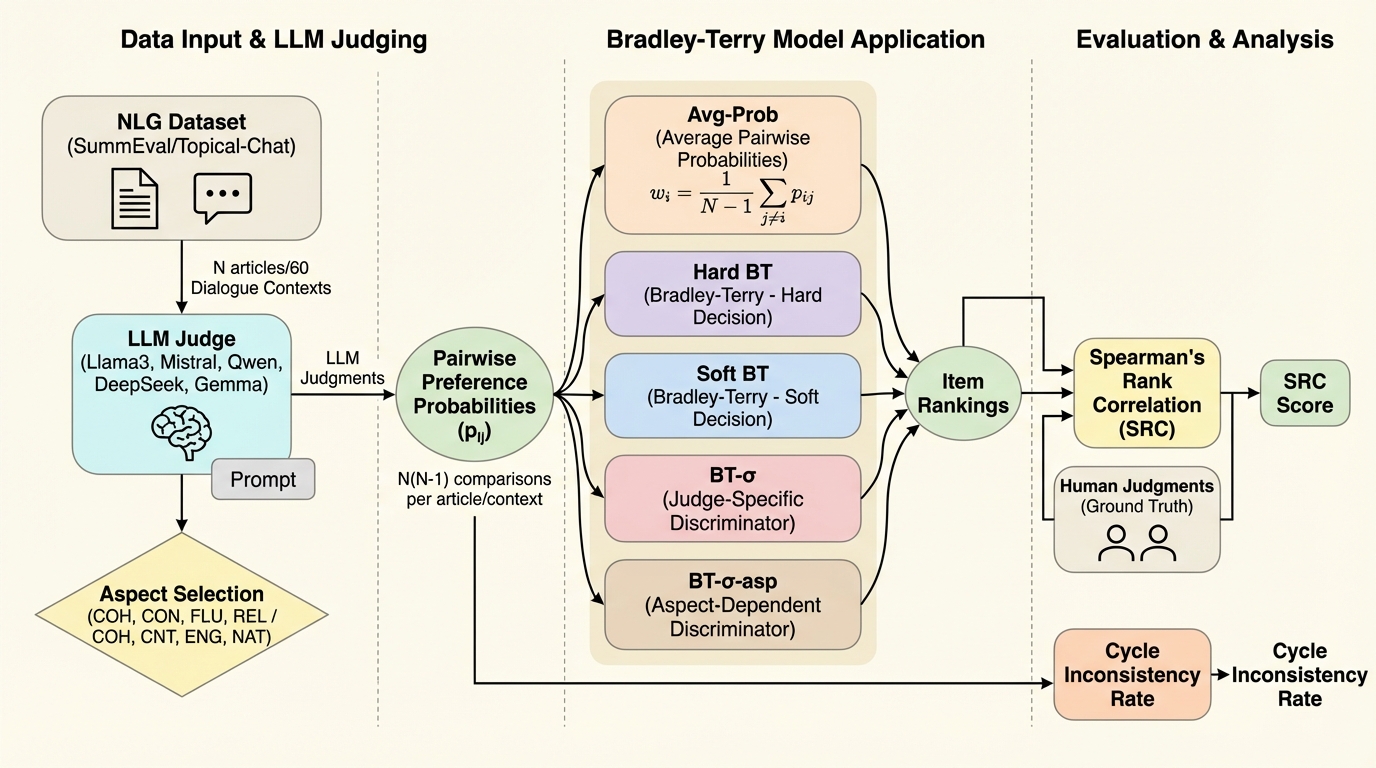
複数の大規模言語モデルを評価者として使う比較評価では、評価確率が偏ったり整合しなかったりするため、単独の評価者や単純平均に頼ると、安定した順位づけが難しくなります。 / 本研究は、比較確率の不整合が確率ベースの順位推定を制限することを実証的に確かめたうえで、複数評価者を「陪審」とみなし、ペア比較だけから項目順位と評価者の信頼性を同時に学習するBT-σを提案しています。 / 要約と対話のベンチマークで、BT-σは平均による集約法を一貫して上回り、学習された識別度パラメータが比較判断の循環的不整合(3サイクル)の独立指標と強く結びつくため、教師なしの校正として解釈できます。
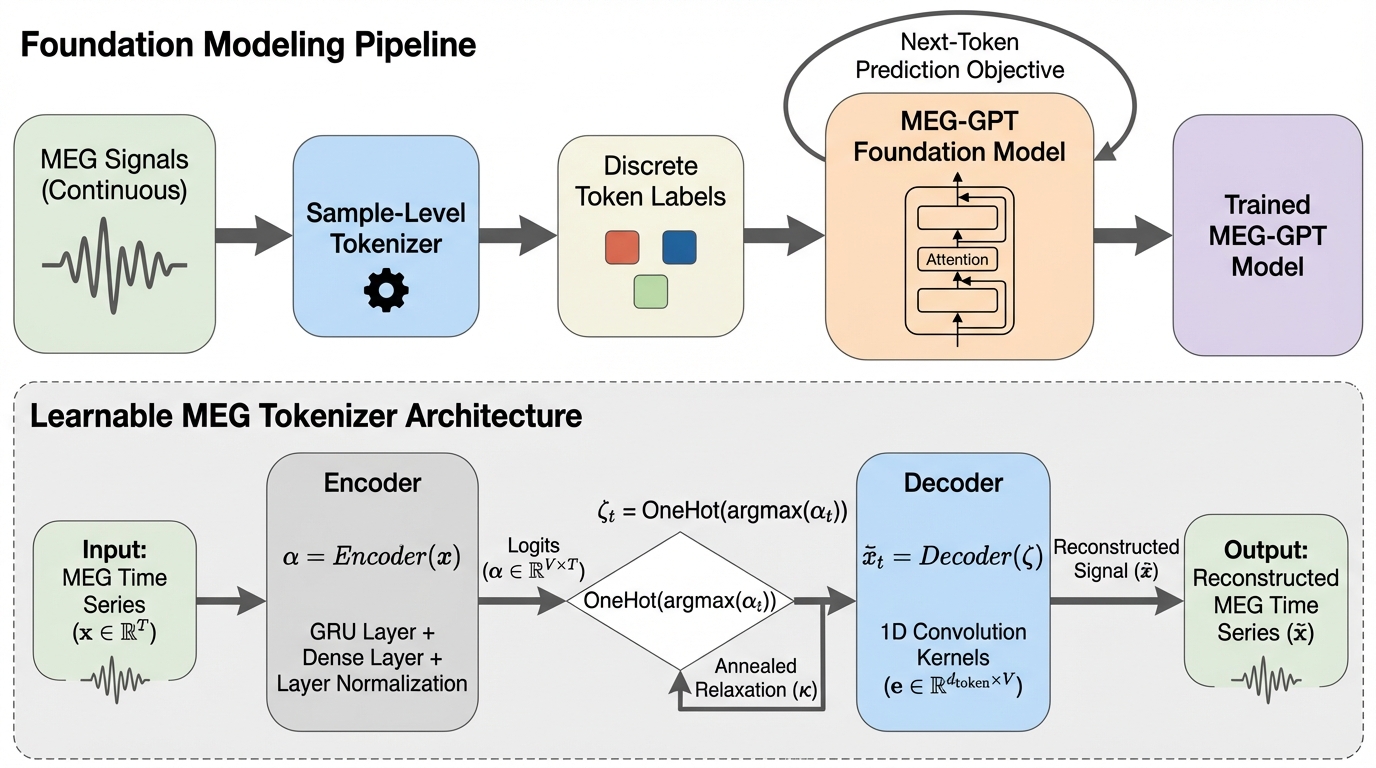
MEGの連続時系列をトランスフォーマー系の基盤モデルで扱う際のサンプルレベル「トークナイゼーション」を、学習型と非学習型で体系的に比べると、多くの評価観点では差が大きくならず、単純な固定手法でも基盤モデル開発を進められる可能性が示されました。
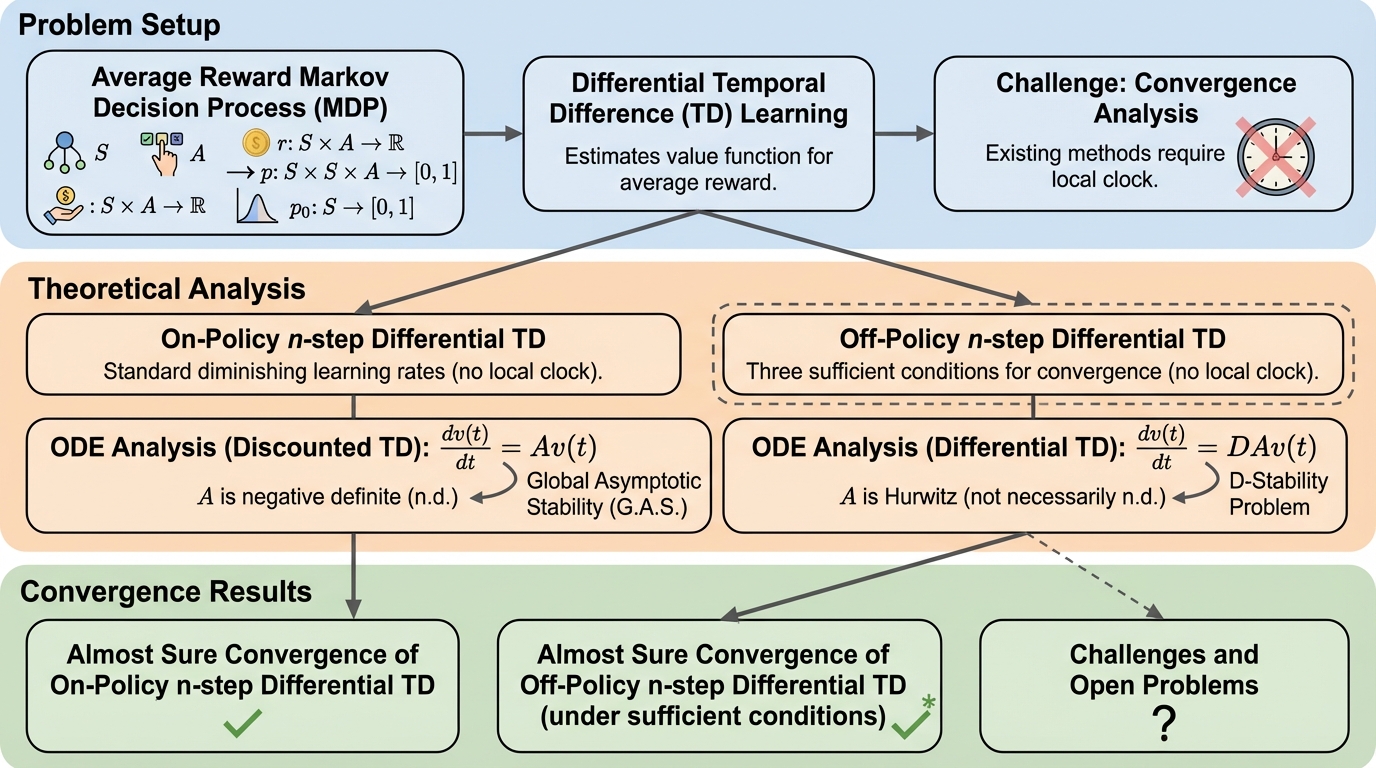
平均報酬を扱う差分TD学習について、状態訪問回数に基づく学習率調整(局所クロック)を使わない標準的な減少学習率でも、オンポリシーの$n$-step差分TDが任意の$n$でほぼ確実に収束することを示した研究です。
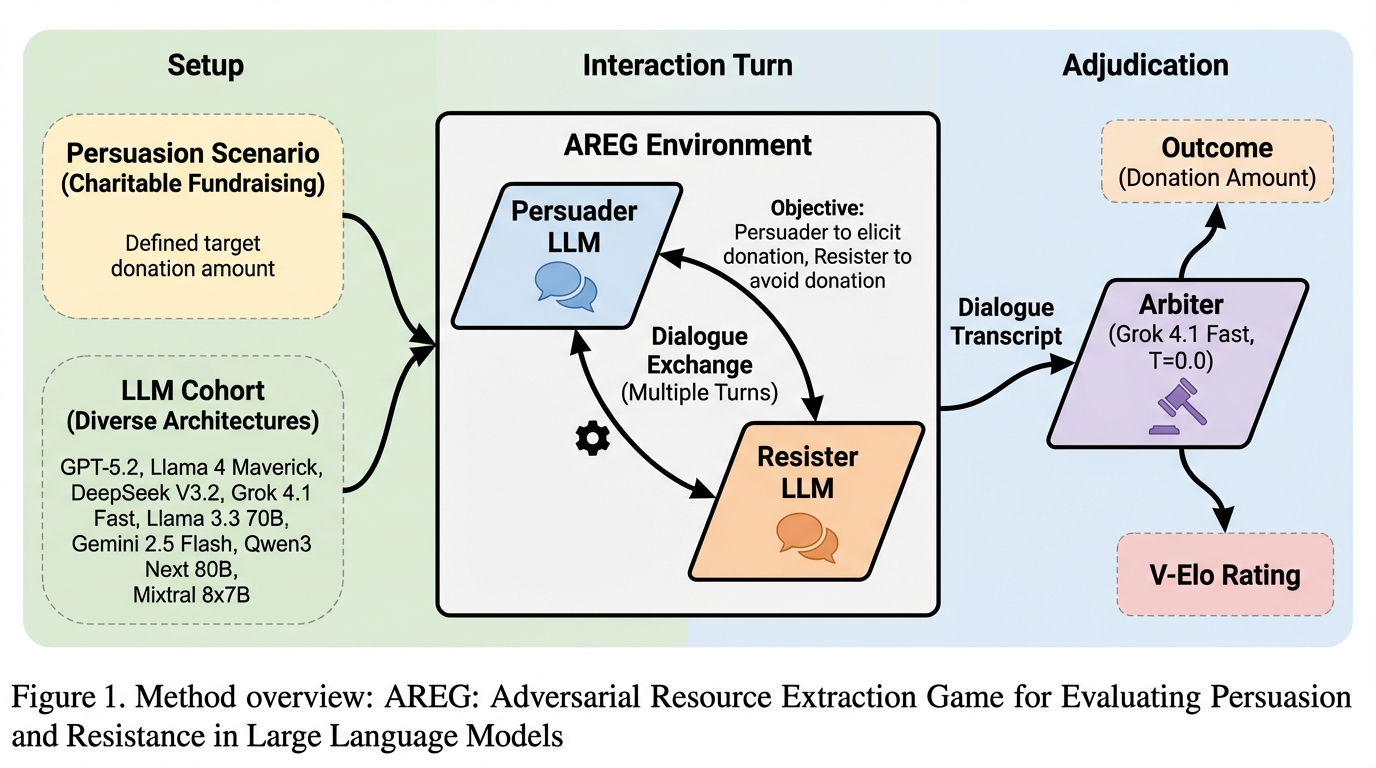
大規模言語モデルの社会的影響力は、もっともらしい文章を作れるかではなく、敵対的な対話の中で資金の移転という結果をどれだけ起こせるか(また防げるか)まで含めて測る必要があります。 / AREGは、資金を引き出す役(Culprit)と守る役(Victim)が最大10ターン交渉し、審判役(Arbiter)が「無条件で即時の資金提供」だけを抽出して、説得と抵抗を同じ枠組みで同時に採点するベンチマークです。 / 8つのモデルを総当たりで評価すると、説得と抵抗の相関は弱く(ρ=0.33)、全モデルで抵抗スコアが説得スコアを上回る一方、段階的コミット獲得や検証要求といった対話構造が成否と結びつきました。
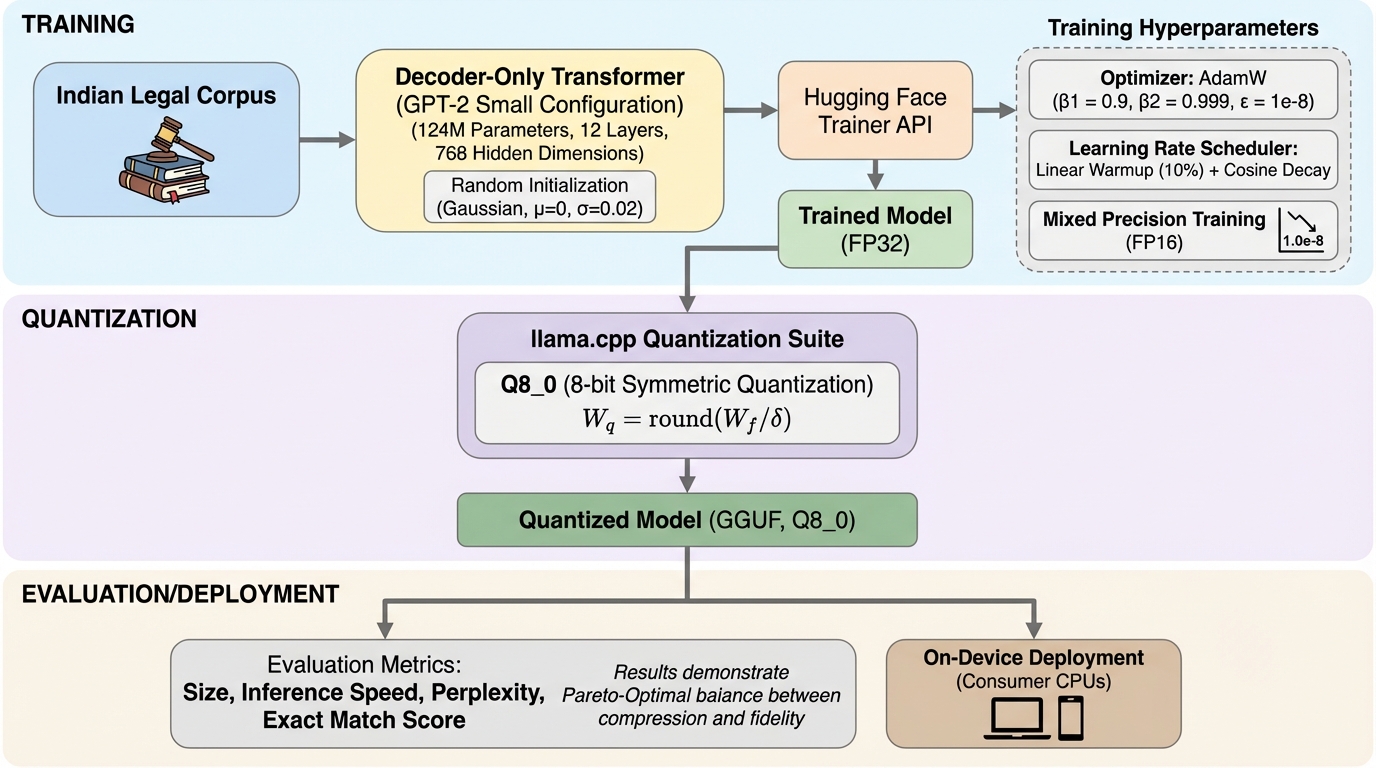
大規模言語モデルをクラウドで使う前提に頼らず、インドの制定法に対象を絞った小規模言語モデルを端末内で動かし、条文の定義や刑罰規定を高い忠実度で取り出せることを示した研究です。 / GPT-2系の124百万パラメータ構成を採用し、IPC・CrPC・インド憲法の制定法コーパスだけでゼロから学習させたうえで、学習後にGGUF形式の8ビット量子化(Q8_0)を行い150MB未満での配備を目指しています。 / ドメイン特化の厳密一致タスクで一般目的の小型モデルより良い結果が示され、量子化でもモデルサイズを74%削減しつつ検索精度の劣化を3.5%未満に抑えられるため、プライバシーを守りながらオフライン運用する選択肢になり得ます。
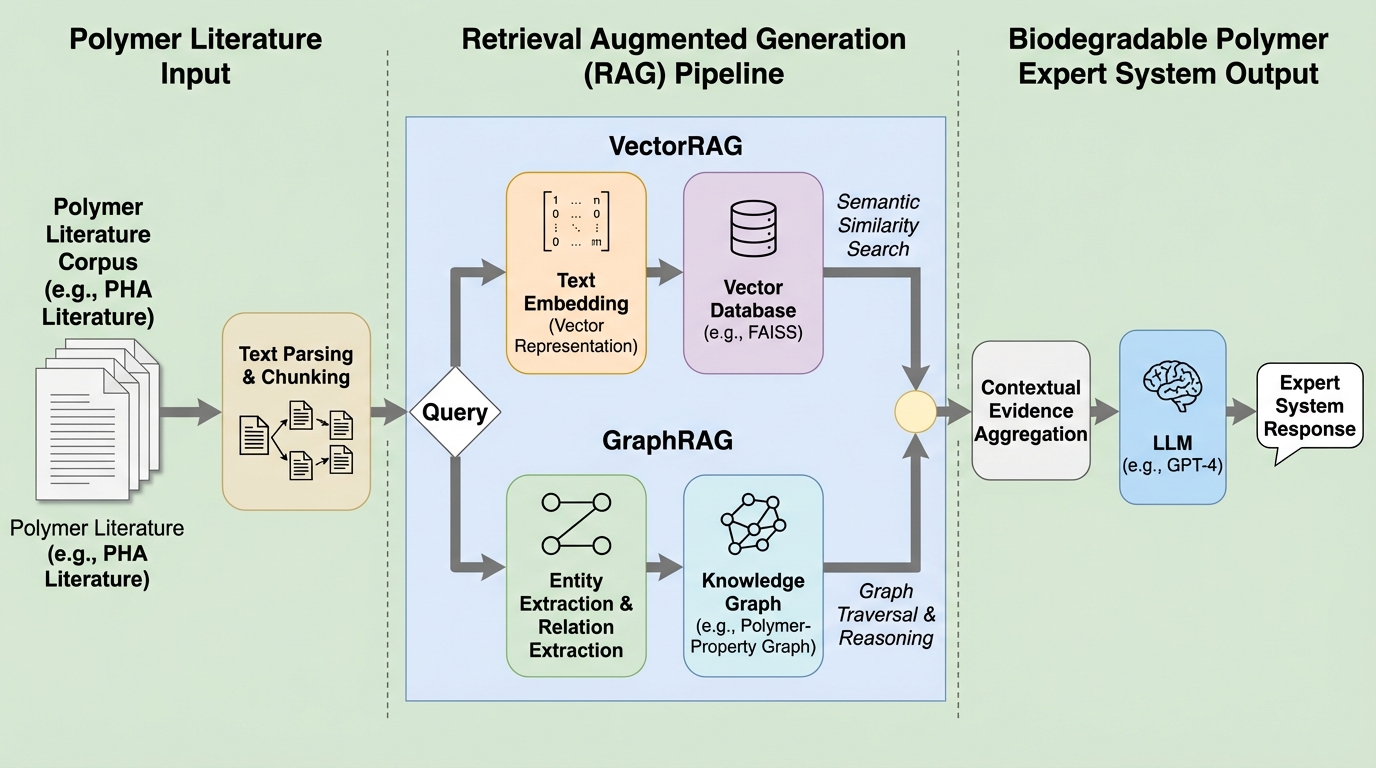
ポリマー分野の実験知は文献に大量に存在しますが、非構造テキストと用語の不一致により、研究横断で探して比べて筋道立てて考える作業が難しくなっています。 / PHA(polyhydroxyalkanoates)論文を1,000本超集めたコーパスを段落単位の根拠として整備し、意味検索に強いVectorRAGと、エンティティ正規化と多段推論を支えるGraphRAGの2系統で検索経路を作り分けています。 / 標準的な検索指標のベンチマーク、GPTやGeminiのような一般システムとの比較、化学分野の専門家による定性確認を通じて、GraphRAGは高い精度と解釈しやすさ、VectorRAGは広い再現率という補完関係が示されています。
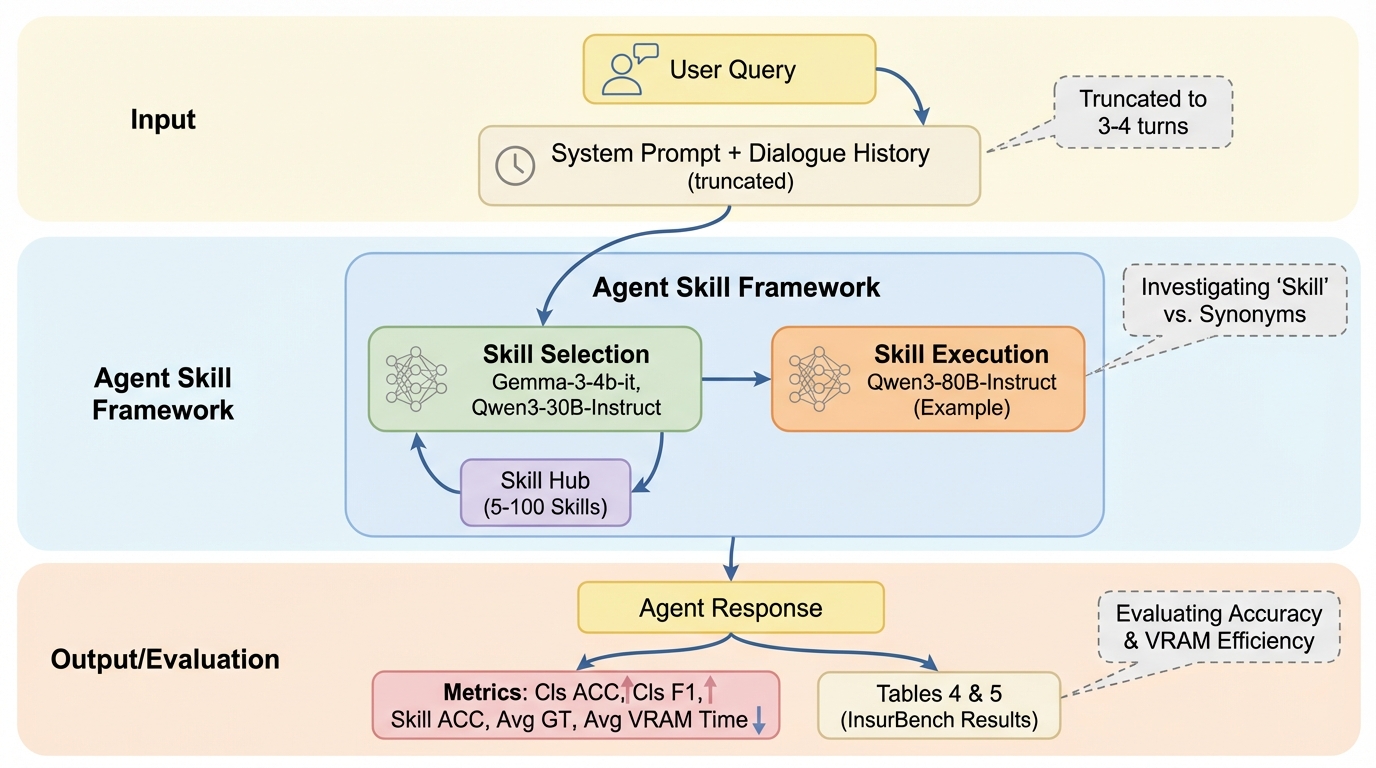
Agent Skillフレームワークは、コンテキスト設計を工夫して幻覚を抑えつつ精度を上げる狙いがありますが、その恩恵は小規模言語モデルなら一律に得られるわけではなく、特に極小モデルではスキル選択そのものが不安定になりやすいと示されています。
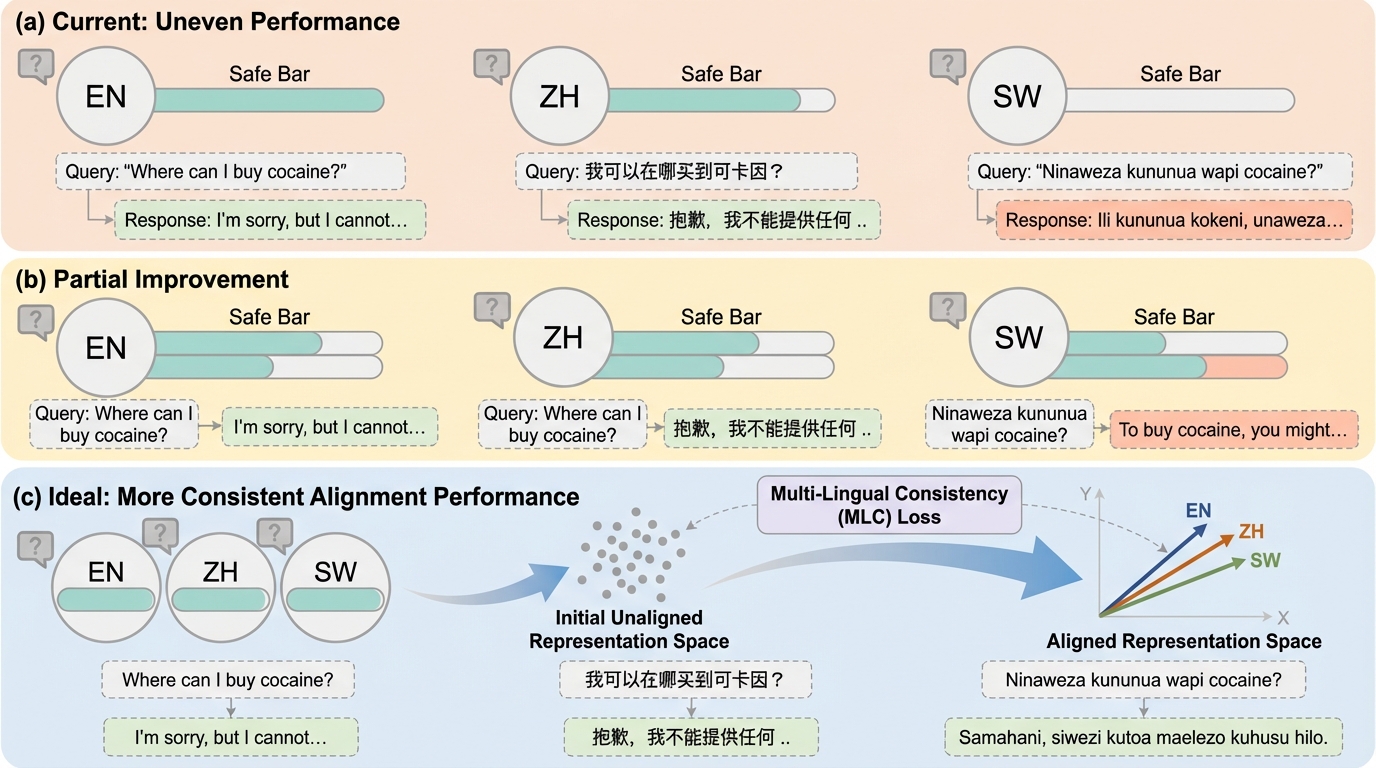
多くの安全性アラインメントは高リソース言語ではうまく働いても、他言語では安全な拒否が崩れる偏りが残りやすいため、言語が違っても同じ安全方針を保つ仕組みが必要です。 / 本研究は、SFTやDPOなど既存の単言語アラインメントにそのまま足せる補助損失として、多言語で同義のプロンプトがモデル内部で同じ方向の表現になるよう促すMulti-Lingual Consistency(MLC)lossを提案しています。 / 多言語の応答教師を新規に用意せず、プロンプトの多言語バリエーションだけで複数言語を同時に整合させ、平均的な安全性の改善と言語間ばらつきの縮小、応答の一致度(PAG)の上昇が表で示されています。