Quecto-V1:8ビット量子化した小規模言語モデルでオンデバイスのインド法検索を実証分析する
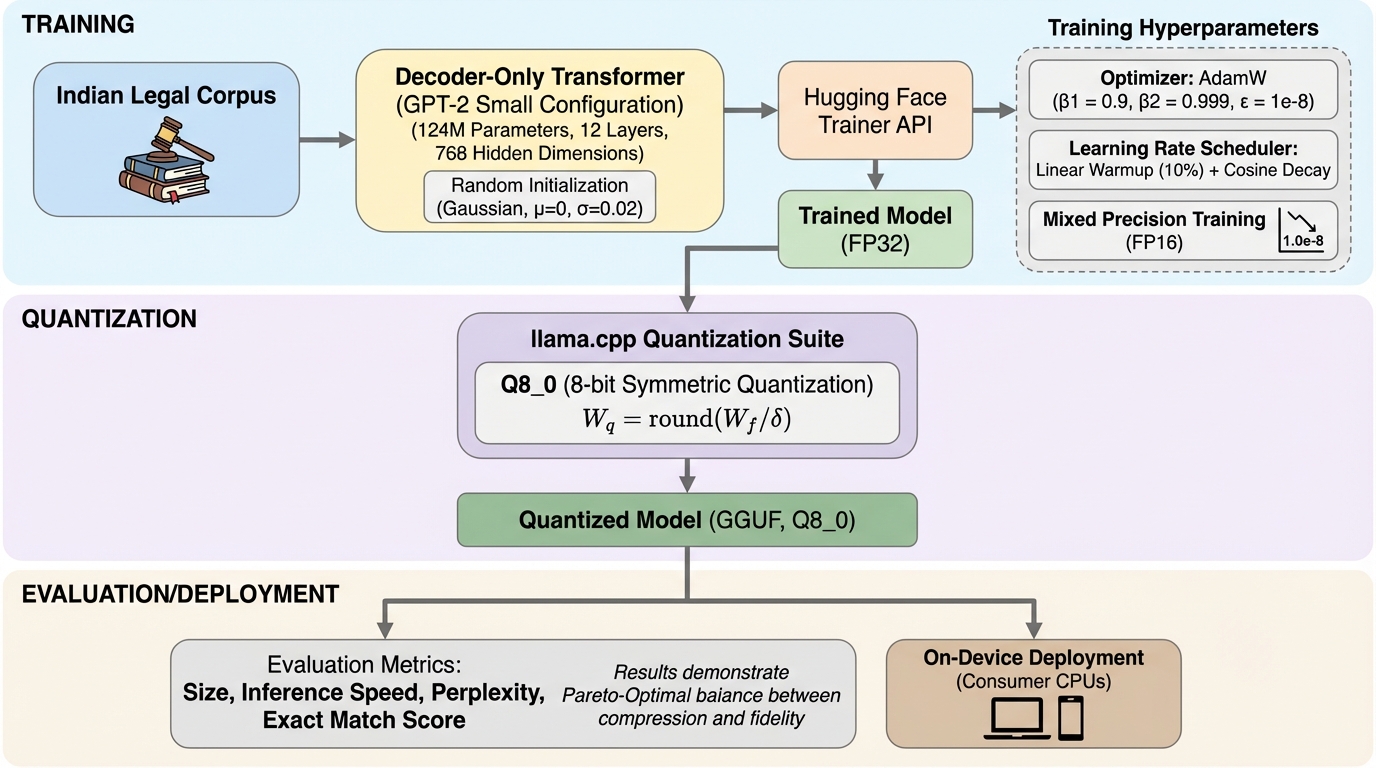
大規模言語モデルをクラウドで使う前提に頼らず、インドの制定法に対象を絞った小規模言語モデルを端末内で動かし、条文の定義や刑罰規定を高い忠実度で取り出せることを示した研究です。 / GPT-2系の124百万パラメータ構成を採用し、IPC・CrPC・インド憲法の制定法コーパスだけでゼロから学習させたうえで、学習後にGGUF形式の8ビット量子化(Q8_0)を行い150MB未満での配備を目指しています。 / ドメイン特化の厳密一致タスクで一般目的の小型モデルより良い結果が示され、量子化でもモデルサイズを74%削減しつつ検索精度の劣化を3.5%未満に抑えられるため、プライバシーを守りながらオフライン運用する選択肢になり得ます。
TL;DR(結論)
- 大規模言語モデルをクラウドで使う前提に頼らず、インドの制定法に対象を絞った小規模言語モデルを端末内で動かし、条文の定義や刑罰規定を高い忠実度で取り出せることを示した研究です。
- GPT-2系の124百万パラメータ構成を採用し、IPC・CrPC・インド憲法の制定法コーパスだけでゼロから学習させたうえで、学習後にGGUF形式の8ビット量子化(Q8_0)を行い150MB未満での配備を目指しています。
- ドメイン特化の厳密一致タスクで一般目的の小型モデルより良い結果が示され、量子化でもモデルサイズを74%削減しつつ検索精度の劣化を3.5%未満に抑えられるため、プライバシーを守りながらオフライン運用する選択肢になり得ます。
なぜこの問題か
大規模言語モデルの普及は自然言語処理を押し上げた一方で、利用できる計算資源や接続環境の差による「資源の分断」を生んだ、と本研究は問題設定しています。最先端の法務インテリジェンスは巨大なパラメータ規模(7B以上)とクラウド推論に依存しやすく、資源が限られる実務家や学習者には届きにくい状況があると述べられています。さらに法的問い合わせは依頼者情報などの機微情報を含みやすく、第三者クラウドへの送信は秘匿やデータ主権の観点でリスクになり得ます。研究ではこの点を、プライバシーの問題としてだけでなく、現場で安心して使えるかという運用上の制約として扱っています。 加えて、推論に必要な計算資源自体も障壁になります。例として、Llama-3-70Bのような大規模モデルの推論には企業向けGPU(NVIDIA A100など)が必要になり得て、個人や小規模組織には費用面で難しいという文脈が示されています。法律文書は古風な語彙、複雑な構文、長距離の文脈依存が強い「法律文体(Legalese)」として特徴づけられ、条文の定義や規定を正確に参照できることが重要です。…
核心:何を提案したのか
本研究の提案は、Quecto-V1というインド法ドメインに特化した小規模言語モデル(SLM)を作り、オンデバイスで制定法検索を成立させることです。狙いは、巨大な汎用モデルをクラウドで使うことを前提にしない形で、インドの法務インテリジェンスへのアクセスを広げる点に置かれています。モデルはGPT-2アーキテクチャをカスタム構成した124百万パラメータで、汎用モデルの微調整ではなく、乱数初期化からの学習を採用しています。これにより、法律に関する振る舞いが大規模ウェブデータの「残り香」によるものではなく、制定法コーパスに由来する効果として説明しやすくする意図が示されています。 学習データはインドの制定法に限定され、Indian Penal Code(IPC)、Code of Criminal Procedure(CrPC)、Constitution of Indiaが含まれています。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related