ColBERT-Zero:ColBERT系マルチベクトル検索モデルは事前学習が必要なのかを段階別に検証する
強い単一ベクトル(dense)モデルの上に小さな知識蒸留(KD)だけを足す従来手順だけでは最適に届きにくく、公開データのみでマルチベクトルとして大規模に事前学習したColBERT-Zeroは、BEIR平均のnDCG@10で55.43を得ています。
TL;DR(結論)
- 強い単一ベクトル(dense)モデルの上に小さな知識蒸留(KD)だけを足す従来手順だけでは最適に届きにくく、公開データのみでマルチベクトルとして大規模に事前学習したColBERT-Zeroは、BEIR平均のnDCG@10で55.43を得ています。
- 学習を「教師なしコントラスト」「教師ありコントラスト」「KD」の3段階に分け、KDのみ、教師あり+KD、全段階をマルチベクトルで実施(ColBERT-Zero)を同一データ条件で比較し、さらにプロンプトの有無を事前学習と微調整で揃える重要性も確かめています。
- KDのみは差が残りますが、KDの前に教師あり段階を入れると全段階実施との差が0.31まで縮み、加えて事前学習と微調整でプロンプト設定がずれると性能が大きく落ちることが示されています。
なぜこの問題か
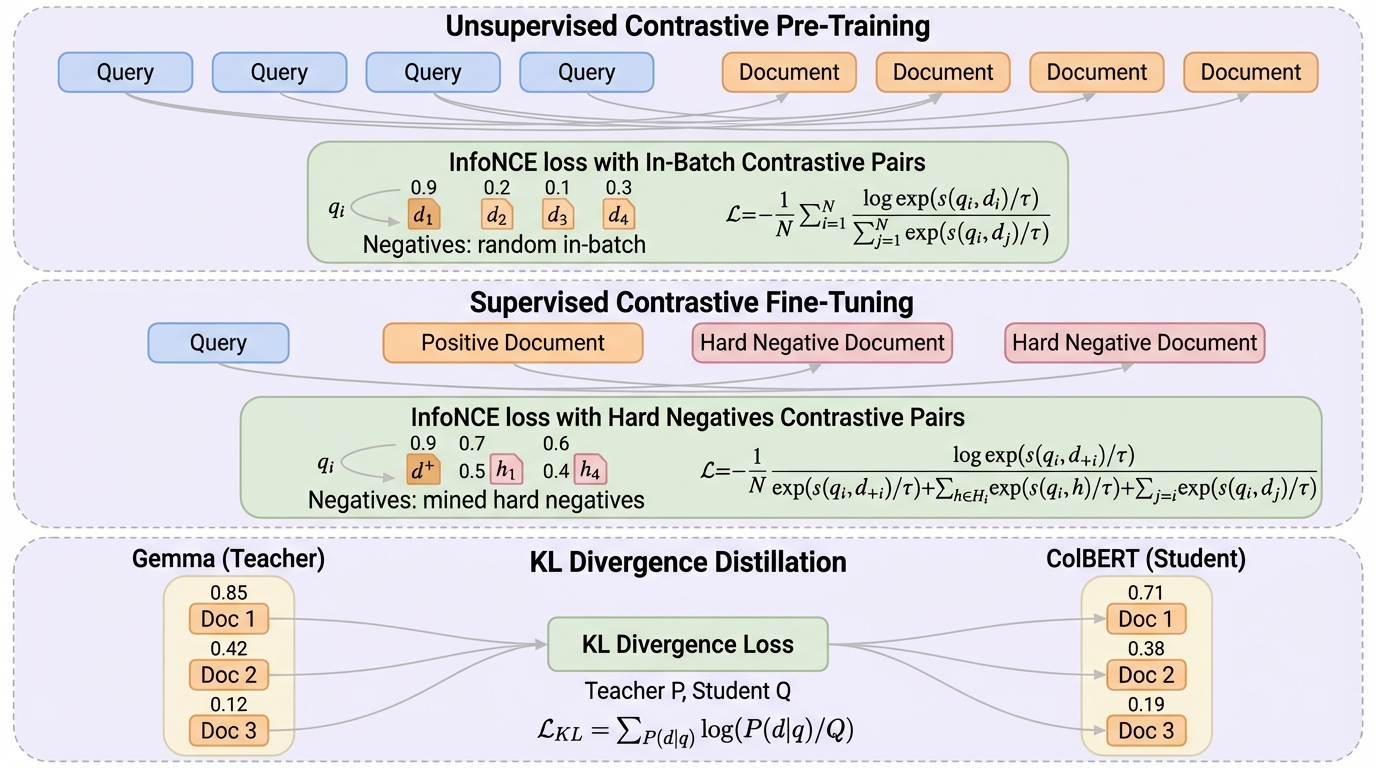
Late interactionモデルは、マルチベクトル検索やColBERT系モデルとも呼ばれ、ドメイン外の検索、長い文脈を含む検索、推論要素が強い検索での強みが報告されています。にもかかわらず、単一ベクトルの検索モデルと比べると、学習の設計やレシピの整理が進みにくい状況があると述べられています。現状の強いColBERT系モデルとして、GTE-ModernColBERTやColBERT-smallが挙げられており、これらは強いdenseモデルの大規模事前学習を活用しつつ、最後に小規模なKDをColBERT側で行う作り方が一般的だと位置づけられています。 この「最後にKDだけを足す」やり方は、マルチベクトル設定を後付けの工程として扱っている点が問題になり得ます。検索モデルの学習は最大で3段階、すなわち(1)教師なしのコントラスト事前学習、(2)教師ありのコントラスト微調整、(3)KDとして整理できるため、どの段階をマルチベクトルで行うべきかが性能を左右する可能性があります。特に教師なし段階はin-batch negativesに依存するため大きなバッチが必要になり、計算コストが支配的になりやすいと説明されています。…
核心:何を提案したのか
本研究の核心は、ColBERT系マルチベクトル検索モデルの学習を「段階の組み合わせ」として分解し、どの段階をマルチベクトル設定で実施することが重要かを同条件で検証することです。具体的には、(a)KDのみ、(b)教師ありコントラスト+KD、(c)教師なし・教師あり・KDのすべてをマルチベクトルで実施、という3つのパイプラインを比較します。(c)が「完全にColBERTとして事前学習されたモデル」に相当し、ColBERT-Zeroとして提示されています。 比較の要点は、同じ元モデルと同じデータを使い、違いが「コントラスト学習をdenseで行うか、late interaction(マルチベクトル)で行うか」にできるだけ集約されるようにする点です。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related