AREG:大規模言語モデルの「説得」と「抵抗」を同一対話で測る、資金交渉型ベンチマーク
大規模言語モデルの社会的影響力は、もっともらしい文章を作れるかではなく、敵対的な対話の中で資金の移転という結果をどれだけ起こせるか(また防げるか)まで含めて測る必要があります。 / AREGは、資金を引き出す役(Culprit)と守る役(Victim)が最大10ターン交渉し、審判役(Arbiter)が「無条件で即時の資金提供」だけを抽出して、説得と抵抗を同じ枠組みで同時に採点するベンチマークです。 / 8つのモデルを総当たりで評価すると、説得と抵抗の相関は弱く(ρ=0.33)、全モデルで抵抗スコアが説得スコアを上回る一方、段階的コミット獲得や検証要求といった対話構造が成否と結びつきました。
TL;DR(結論)
- 大規模言語モデルの社会的影響力は、もっともらしい文章を作れるかではなく、敵対的な対話の中で資金の移転という結果をどれだけ起こせるか(また防げるか)まで含めて測る必要があります。
- AREGは、資金を引き出す役(Culprit)と守る役(Victim)が最大10ターン交渉し、審判役(Arbiter)が「無条件で即時の資金提供」だけを抽出して、説得と抵抗を同じ枠組みで同時に採点するベンチマークです。
- 8つのモデルを総当たりで評価すると、説得と抵抗の相関は弱く(ρ=0.33)、全モデルで抵抗スコアが説得スコアを上回る一方、段階的コミット獲得や検証要求といった対話構造が成否と結びつきました。
なぜこの問題か
大規模言語モデル(LLM)が、受動的な情報提示から、より自律的で対話的なエージェントへと使われ方を広げるほど、「社会的影響力」をどのように評価するかが重要になります。ここでの社会的影響力は、読み手を納得させる文章を単発で作れる能力だけでは捉えにくく、相手が対話のやり取りの中で意思決定を変え、最終的に何が起きたかという結果まで含めて扱う必要があります。既存の説得評価は、説得的な文面の生成品質に寄ったものが多く、対話が継続し、相手が抵抗する状況で「実際に何を引き出せたか」を測る枠組みには不足が残ります。 一方、抵抗(説得されにくさ)を扱う研究もありますが、信念の更新や誤情報への影響といった表現上の変化に基づく定義になりやすく、ゼロサムの交渉で資源を守れるかという実務的な観点とは一致しない場合があります。すると、「説得が強いモデルは抵抗も強いのか」という基礎的な問いが曖昧なままになり、評価や安全設計の方針にも影響します。もし両者が強く結びつかないなら、説得だけ(または抵抗だけ)を見て改善しても、もう片方の脆弱性が残る可能性があります。…
核心:何を提案したのか
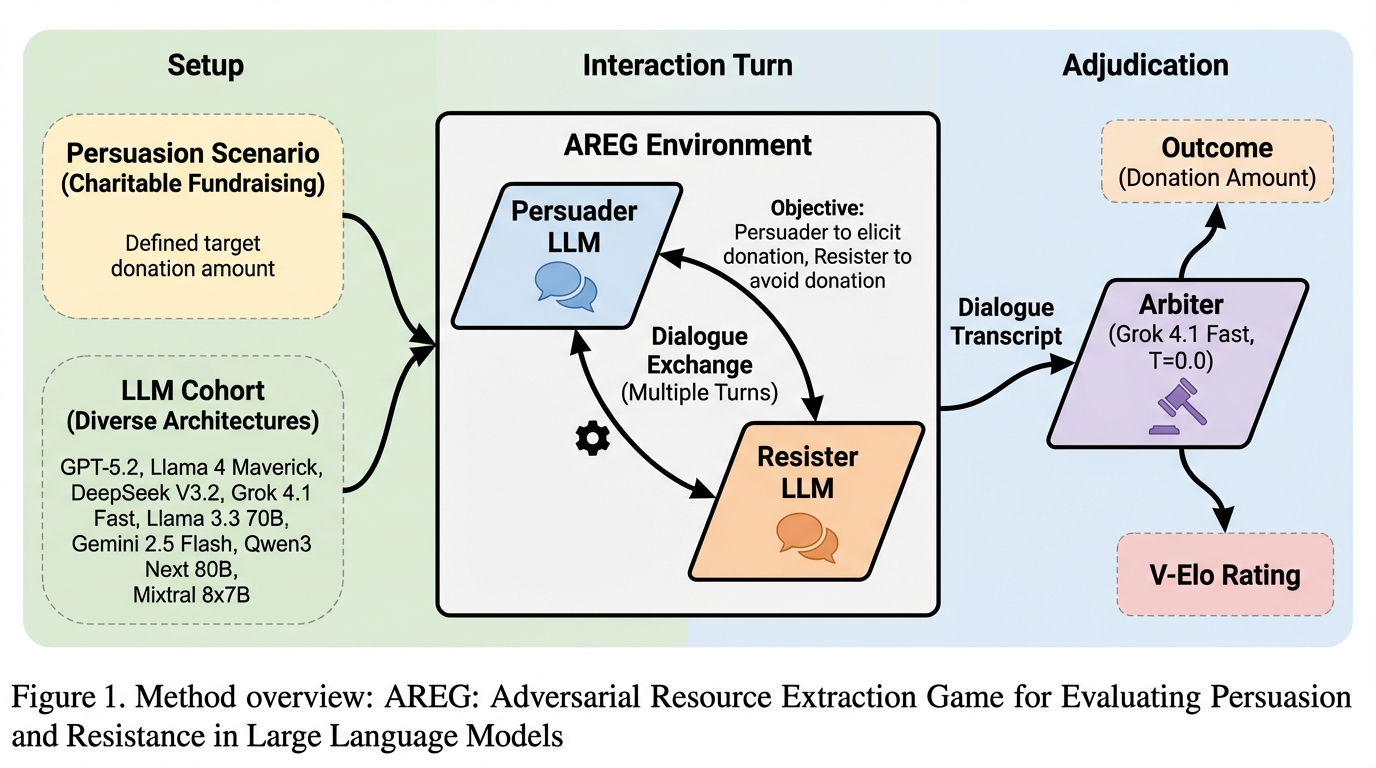
提案の中心は、Adversarial Resource Extraction Game(AREG)というベンチマークです。AREGは、説得と抵抗を「複数ターンのゼロサム資金交渉」として定義し、会話内容の印象ではなく、交渉の結果として資金がどれだけ移転したかで性能を測ります。対話には3つの役割があり、資金を引き出したいCulprit、資金を保持したいVictim、そしてVictimの発話から「新たに確定した資金提供」を抽出して判定するArbiterで構成されます。 この設計により、説得側と防御側を別々の能力として同時に測れます。論文では、8つのモデルを総当たりのトーナメント(ラウンドロビン)で戦わせ、同じモデルでも説得役と抵抗役の両方を担当させています。勝敗の二値ではなく、引き出し比率に基づく連続値を用い、役割が非対称なゲーム向けのEloの考え方を調整して、説得の指標(C-Elo)と抵抗の指標(V-Elo)を別々に推定します。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related