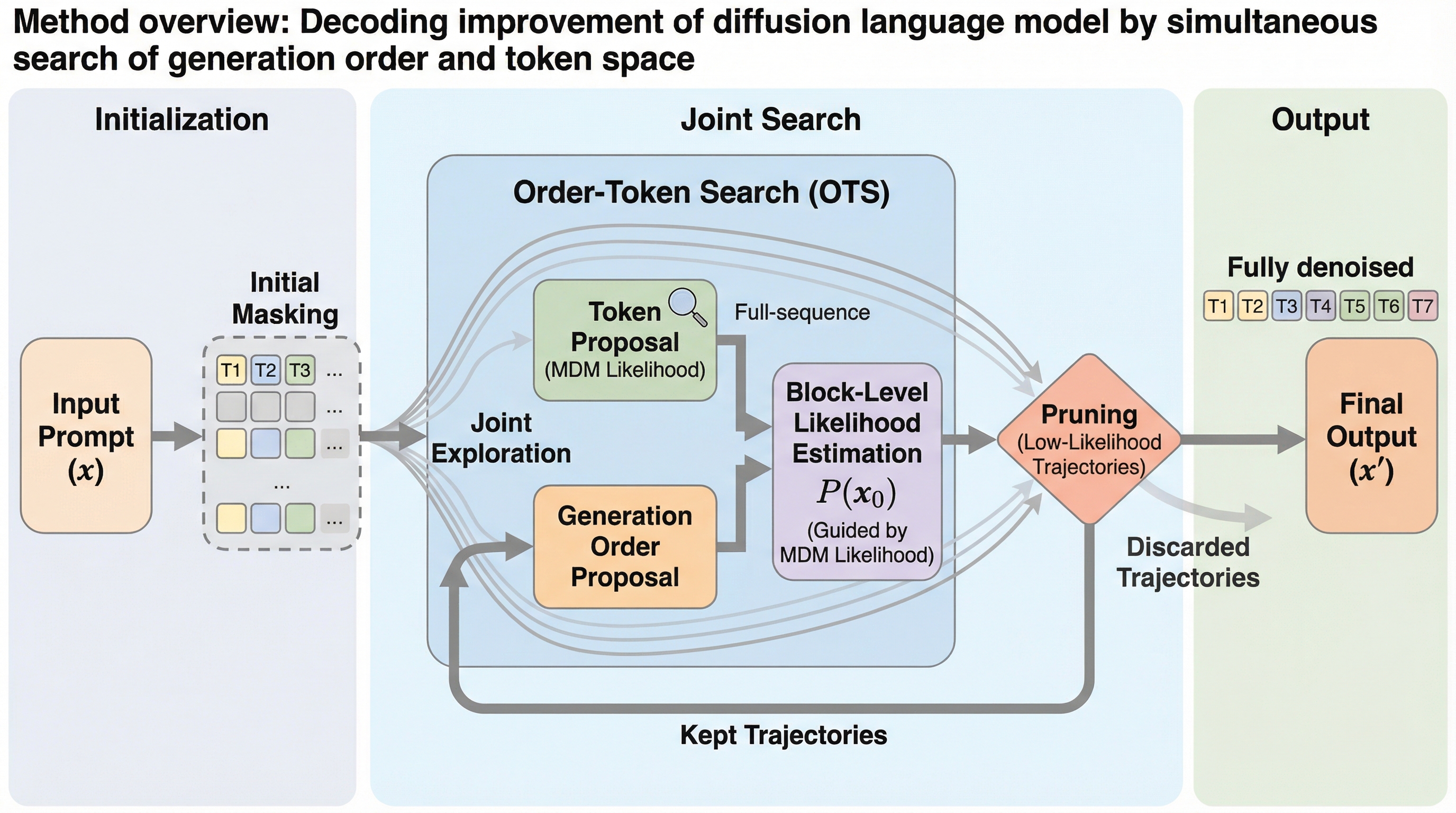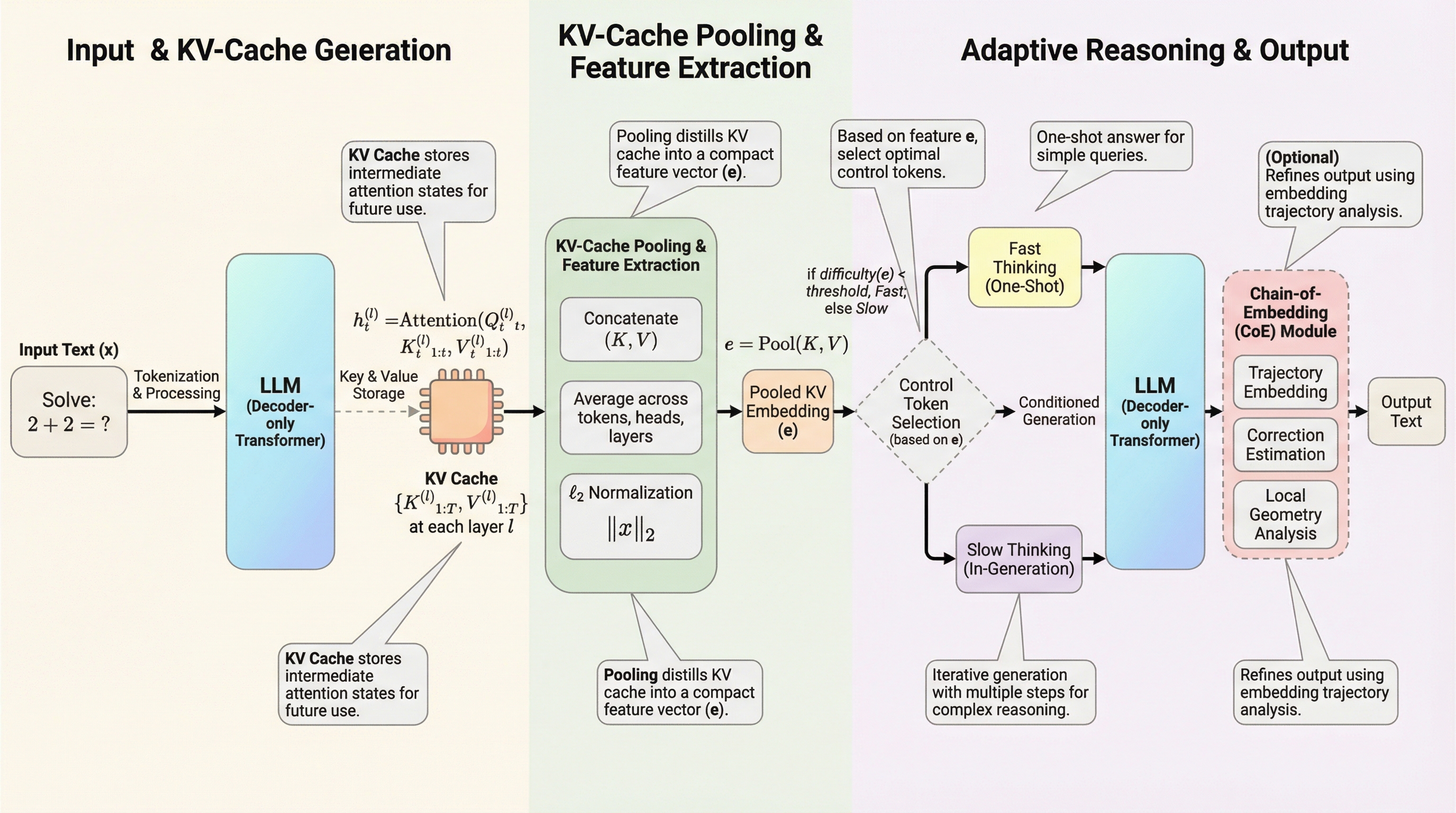
スピードアップの先へ:KVキャッシュをサンプリングと推論に活用する
大規模言語モデルの推論を高速化するために不可欠なKVキャッシュを、単なる加速手段ではなく、下流タスクのための軽量な表現(埋め込み)として再利用する手法が提案されました。 この手法は、追加の計算コストやメモリ消費をほとんど伴わずに、推論パスの選択を行うChain-of-Embeddingや、問題の難易度に応じて思考の深さを切り替えるFast/Slow Thinking Switchに適用可能です。 実験では、Llama-3.1やQwen2などのモデルにおいて、フル状態の隠れ層を用いる手法に匹敵する性能を示しつつ、特定のタスクでは生成トークン数を最大5.7倍削減することに成功しました。