マルチエージェント協調による適応型メモリシステム「AMA」
大規模言語モデル(LLM)エージェントが長期的な対話や複雑な推論を遂行するために、4つの専門エージェントが協調してメモリを管理する新フレームワーク「AMA(Adaptive Memory via Multi-Agent Collaboration)」が提案されました。
TL;DR(結論)
大規模言語モデル(LLM)エージェントが長期的な対話や複雑な推論を遂行するために、4つの専門エージェントが協調してメモリを管理する新フレームワーク「AMA(Adaptive Memory via Multi-Agent Collaboration)」が提案されました。 このシステムは、情報の粒度を「生のテキスト」「構造化された事実」「抽象的なエピソード」の3階層で保持し、タスクの要求に応じて最適な情報を動的に選択する適応型ルーティングを実現することで、情報の断片化やノイズの混入を効果的に防ぎます。 検証の結果、既存の最先端手法を凌駕する性能を達成しつつ、コンテキスト全体を利用する場合と比較してトークン消費量を約80%削減し、さらに論理的な矛盾を自動修正することで約90%という極めて高い知識更新精度を記録しました。
なぜこの問題か
大規模言語モデル(LLM)を基盤としたエージェントは、複雑な推論やツールの利用、そして多段階にわたる対話において目覚ましい能力を発揮していますが、これらの高度な振る舞いを支えるためには、文脈の整合性と一貫性を維持するための長期メモリシステムが不可欠です。現在、長期メモリを実現するアプローチは、モデルの内部パラメータに情報を蓄積する「内部メモリ」と、外部ストレージを利用する「外部メモリ」の2つに大別されます。しかし、内部メモリは容量に物理的な限界があり、情報を更新するたびに膨大な計算コストがかかるという課題を抱えています。そのため、拡張性と編集の容易さに優れた外部メモリが主流となっていますが、既存の外部メモリシステムには「情報の粒度の不一致」という深刻な問題が残されていました。 多くの既存システムは、固定長のテキスト分割や、一律で粗い要約手法に依存しています。このような静的な管理戦略では、情報の意味的なまとまりが不自然に分断されることが避けられません。検索の粒度が粗すぎると、タスクとは無関係なノイズが大量に混入し、モデルの判断を狂わせる原因となります。…
核心:何を提案したのか
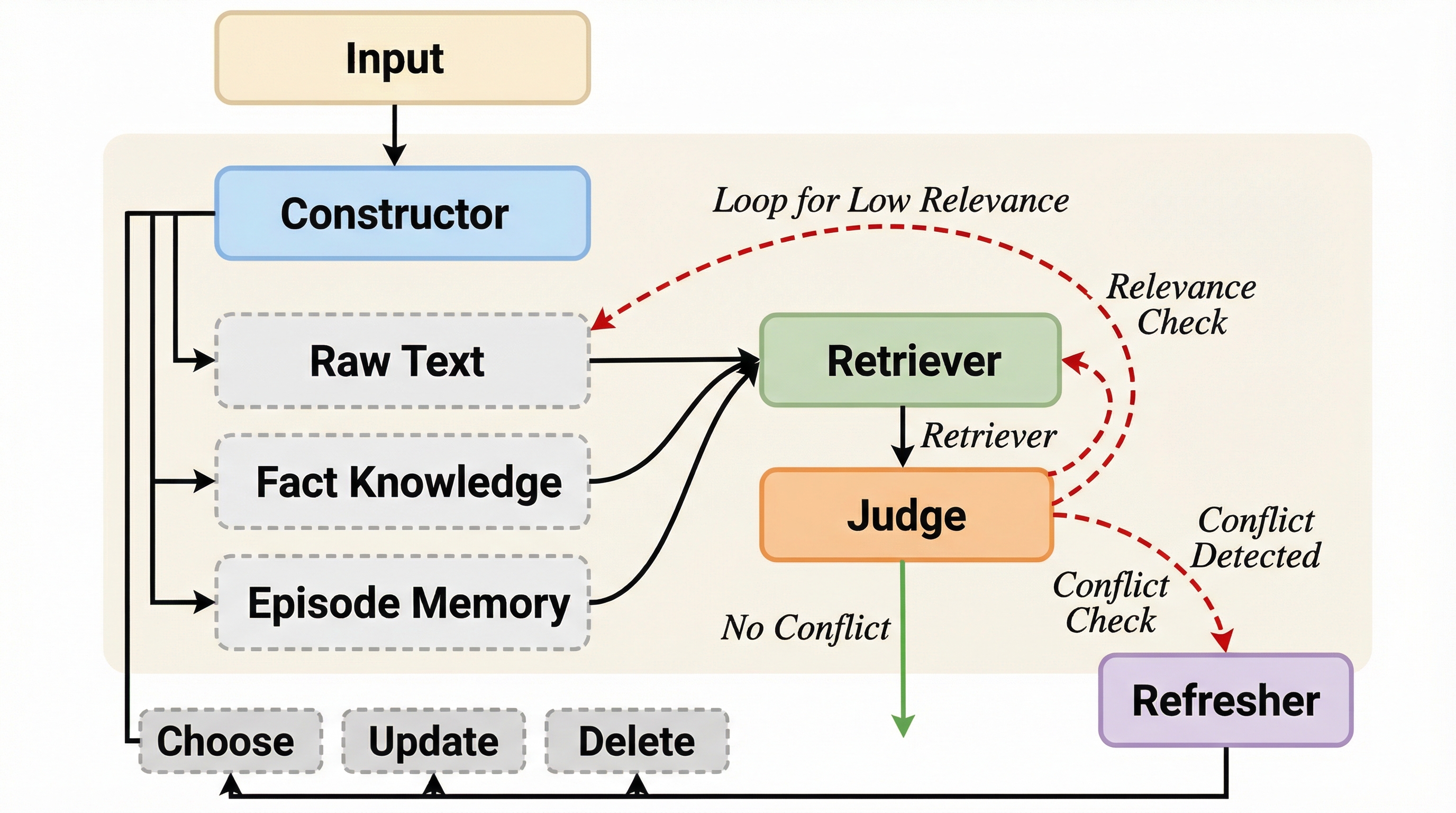
本論文では、これらの課題を解決するために、マルチエージェントの協調によってメモリのライフサイクルを自律的に管理する「AMA(Adaptive Memory via Multi-Agent Collaboration)」という革新的なフレームワークを提案しています。AMAの最大の特徴は、メモリの構築、検索、検証、更新という一連のプロセスを、それぞれ独立した専門的な役割を持つ4つのエージェント(Constructor、Retriever、Judge、Refresher)に分解して担当させている点にあります。この設計により、単一のエージェントでは処理しきれなかった「きめ細かな制御」と「論理的な整合性の維持」を同時に実現することが可能になりました。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related