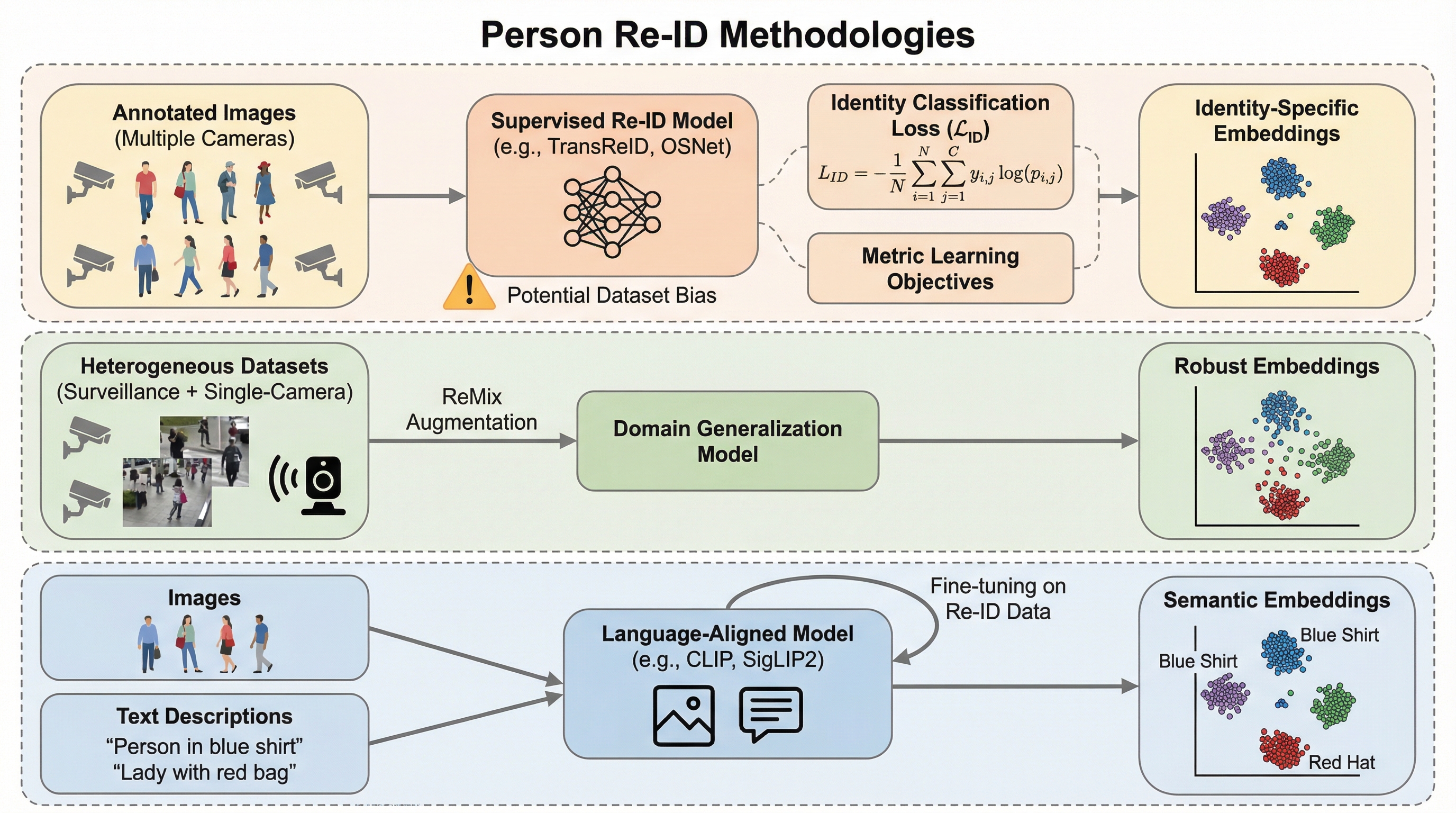
Person Re-ID in 2025: 教師あり、自己教師あり、言語アライメント。何が機能するのか?
本研究は2025年時点の人物再識別(Person Re-ID)における「教師あり学習」「自己教師あり学習」「言語アライメント」の3つの主要な学習パラダイムを、11種類のモデルと9種類の多様なデータセットを用いて包括的に評価したものである。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
本研究は2025年時点の人物再識別(Person Re-ID)における「教師あり学習」「自己教師あり学習」「言語アライメント」の3つの主要な学習パラダイムを、11種類のモデルと9種類の多様なデータセットを用いて包括的に評価したものである。
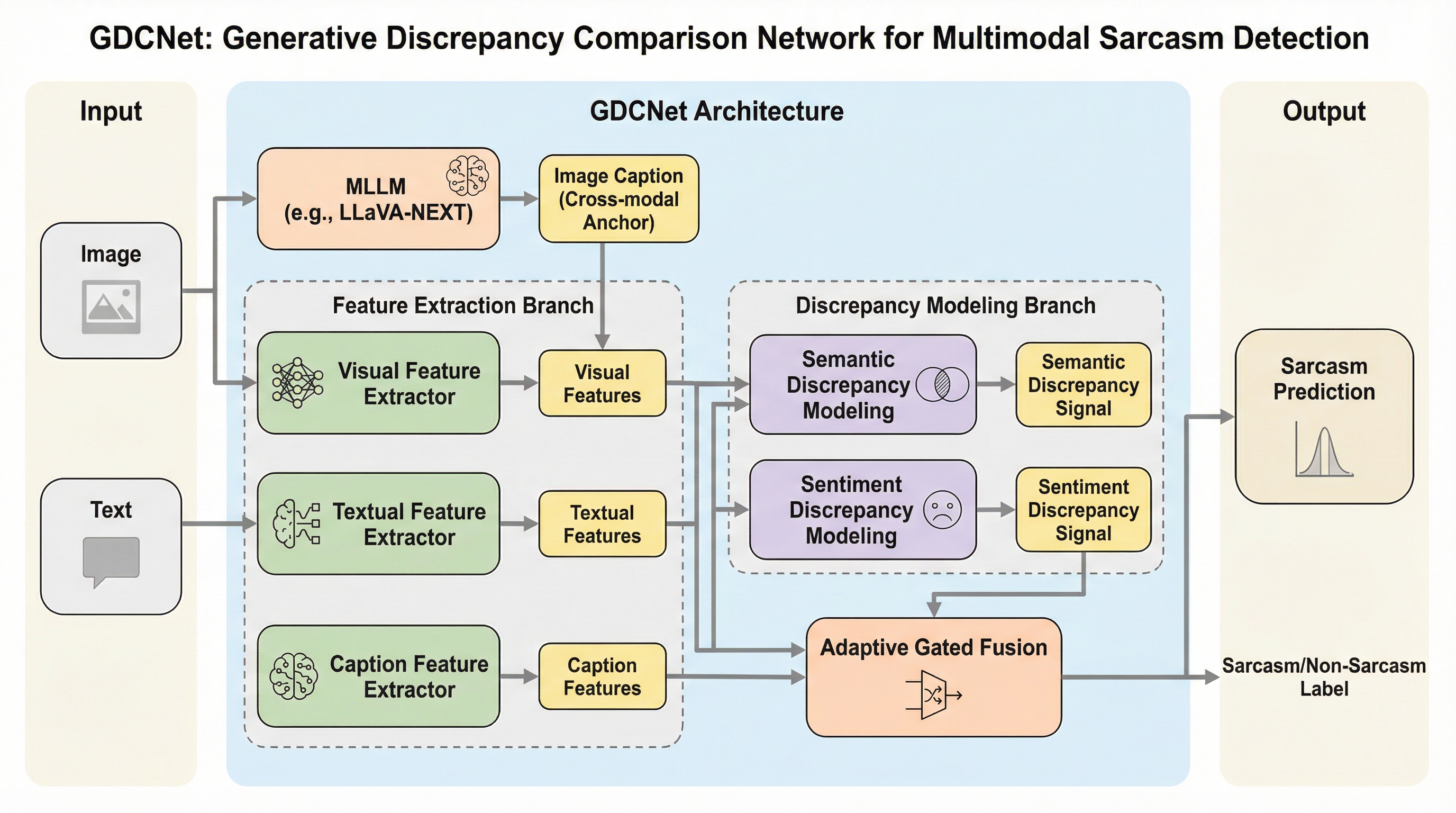
GDCNetは、画像とテキストのペアから皮肉を検出するために、マルチモーダル大規模言語モデル(MLLM)を「客観的な画像説明の生成器」として活用する新しいフレームワークである。従来のモデルがLLMに主観的な皮肉の理由を生成させていたのに対し、本手法は画像に基づいた事実的なキャプションを生成し、それを安定したセマンティック・アンカー(意味の指標)として活用することで、解釈の多様性によるノイズを抑制している。 このネットワークは、生成された客観的な画像説明と元のテキストとの間にある意味的な不一致、感情的な不一致、および画像とテキストの忠実度を測定する「生成的差異表現モジュール(GDRM)」を備えている。これにより、画像とテキストの間の微妙な矛盾や、文字通りの意味と意図された意味の乖離を、多角的な差異特徴として抽出することが可能になり、皮肉特有の複雑な不一致を捉えることができる。 大規模なベンチマークであるMMSD2.0を用いた実験において、GDCNetは既存のマルチモーダル手法や、GPT-4oなどの最新モデルを用いた直接的な推論手法を大幅に上回る最高精度を達成した。適応的なゲート付き融合メカニズムを導入することで、画像、テキスト、および差異情報の各モダリティの寄与を動的にバランスさせ、特定の情報の偏りを防ぎながら、頑健な皮肉検出を実現している。
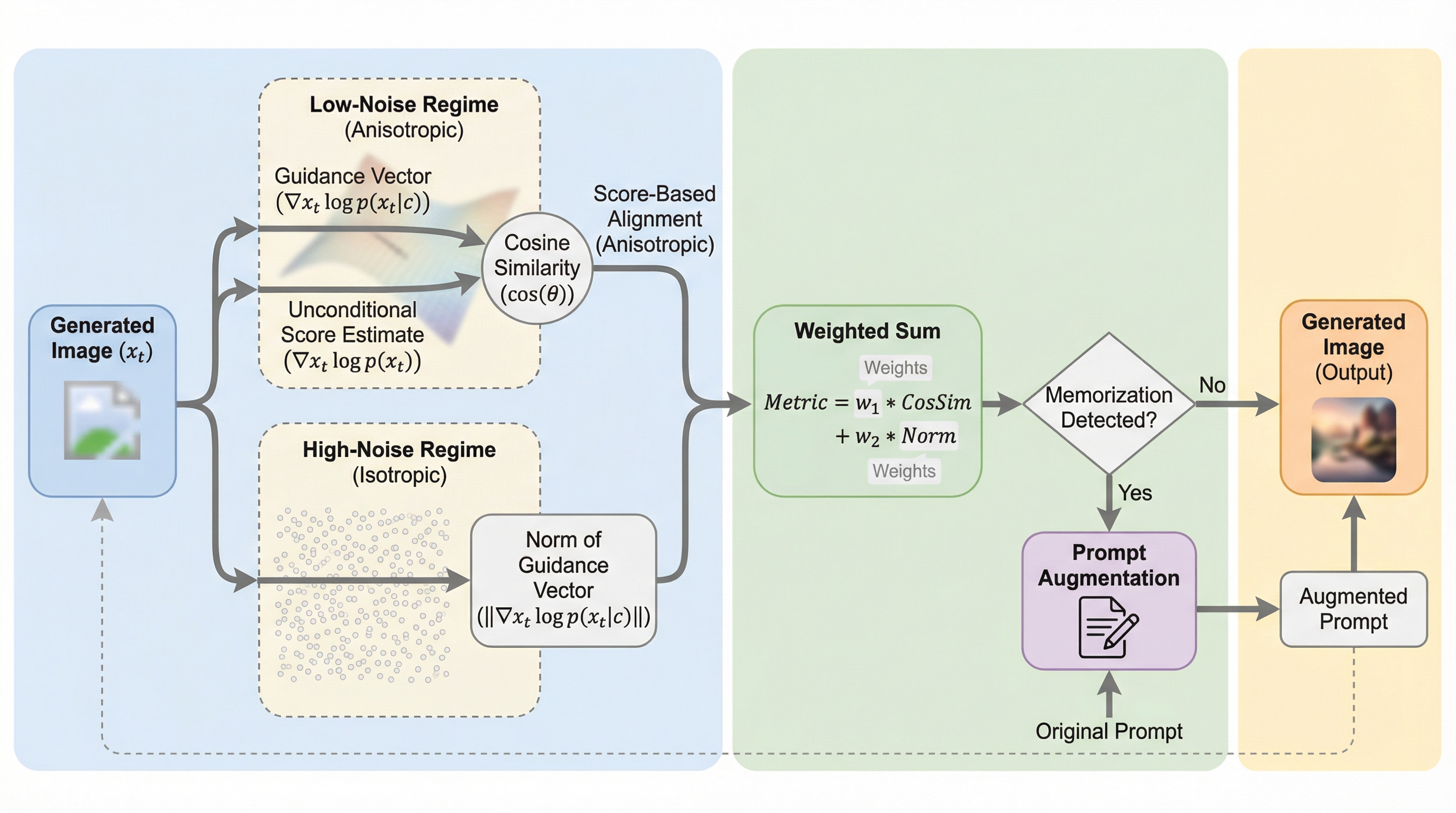
拡散モデルが学習データを複製する「記憶問題」に対し、従来のスコアのノルムに基づく検出法は高ノイズ時の等方的な状態でのみ有効であり、低ノイズ時の異方的な状態では精度が低下するという幾何学的な課題を特定しました。
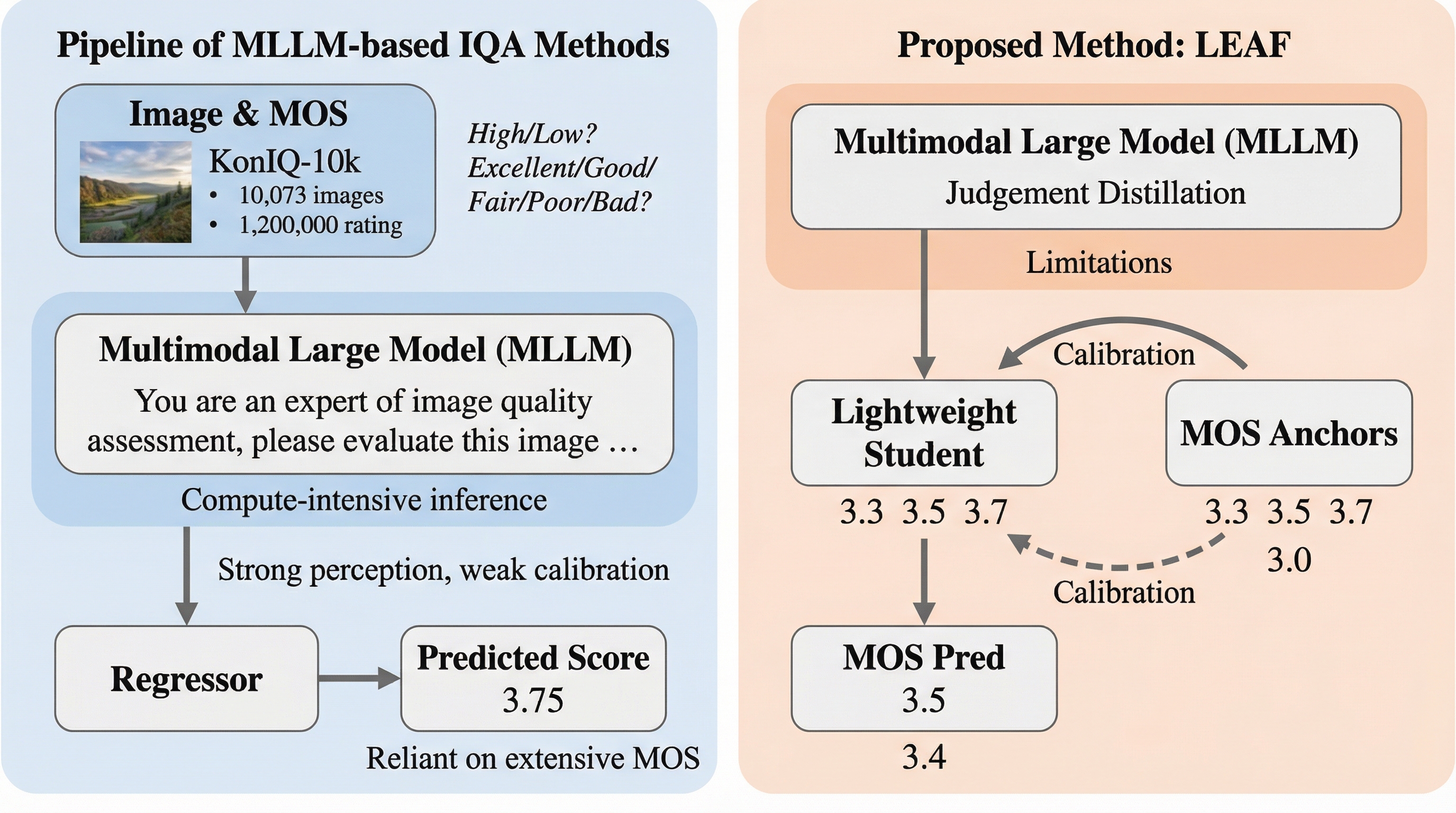
多峰性大規模言語モデル(MLLM)は画像品質評価(IQA)において優れた知覚能力を持つものの、膨大な計算コストと大量の人間による評価ラベル(MOS)への依存が実用上の大きな障壁となっている。 本研究が提案する「LEAF」は、MLLMの知覚能力と特定の評価尺度への校正を分離し、強力な教師モデルから軽量な学生モデルへ知覚知識を蒸留することで、極めて少数のラベルのみで高精度な予測を実現する。 検証の結果、わずか10%のラベルを用いた校正だけで、AI生成画像等のベンチマークにおいて従来のフルデータ学習に匹敵する性能を達成し、デバイス上での動作や大規模データの高速処理を可能にする道を示した。
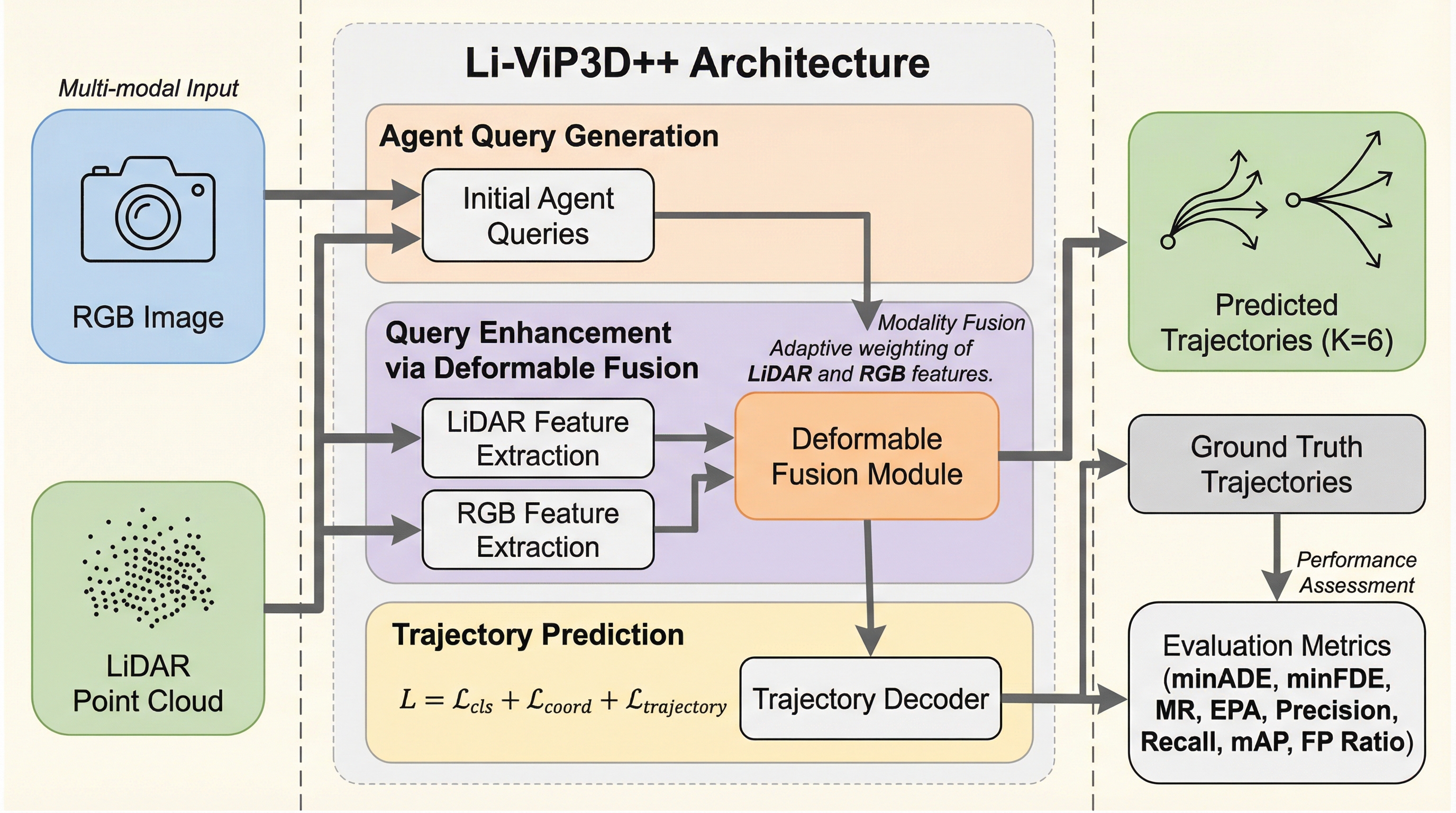
Li-ViP3D++は、自動運転における物体認識と軌跡予測を統合するエンドツーエンドのフレームワークであり、カメラとLiDARの情報をクエリ空間で融合するQuery-Gated Deformable Fusion(QGDF)を導入しています。
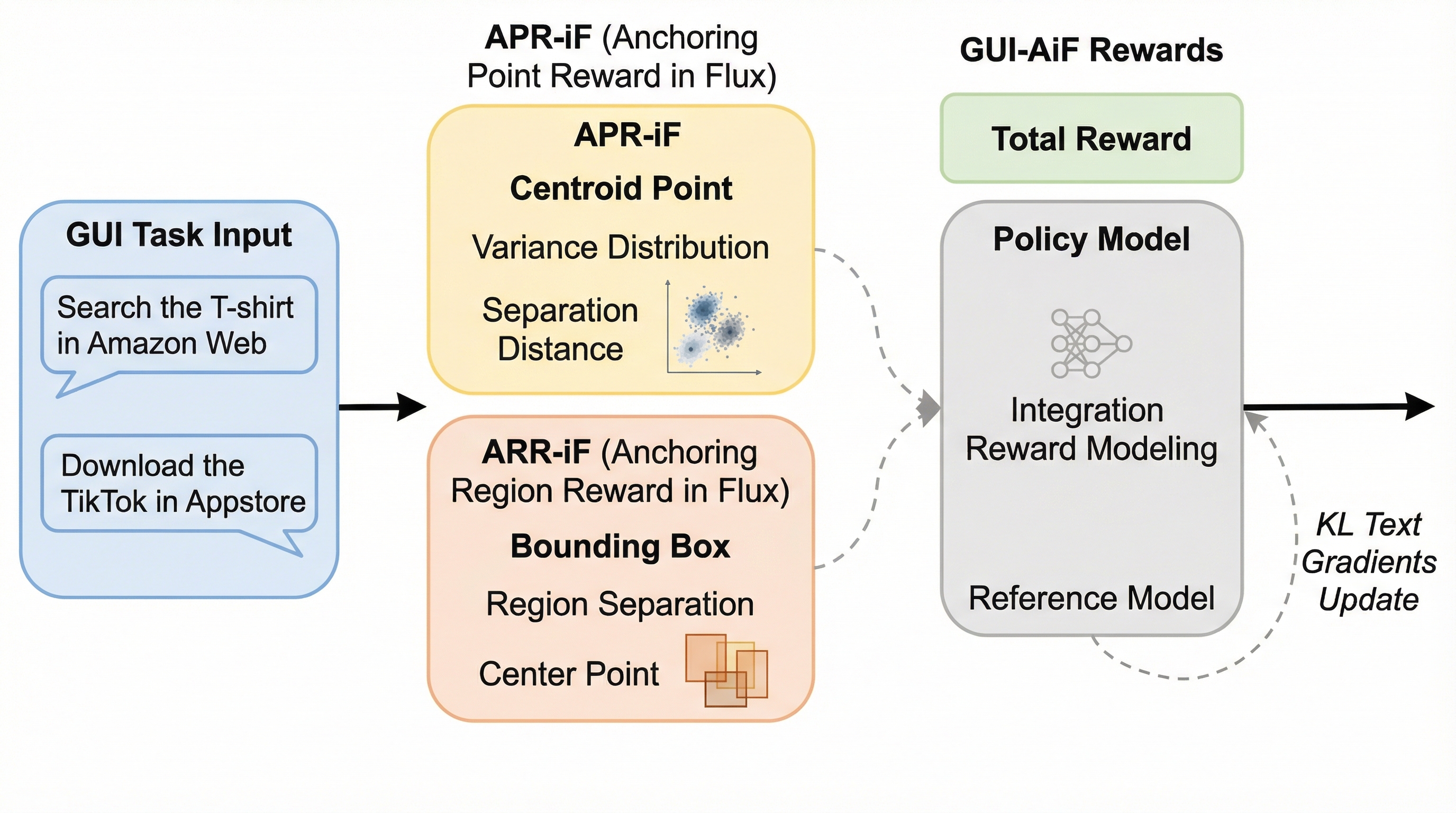
デジタル環境は新しいドメインや解像度の導入により常に変化しており、固定されたデータセットで学習した従来のGUIエージェントは性能が低下するという課題があります。 本研究では、変化する環境下で継続学習を行う「Continual GUI Agents」という新しいタスクと、多様な相互作用点と領域のアンカリングを強化する報酬枠組み「GUI-AiF」を提案しました。 検証の結果、提案手法はScreenSpot-V1、V2、Proの各ベンチマークにおいて、既存の教師あり微調整や強化学習ベースの手法を上回る世界最高水準の性能を達成しました。
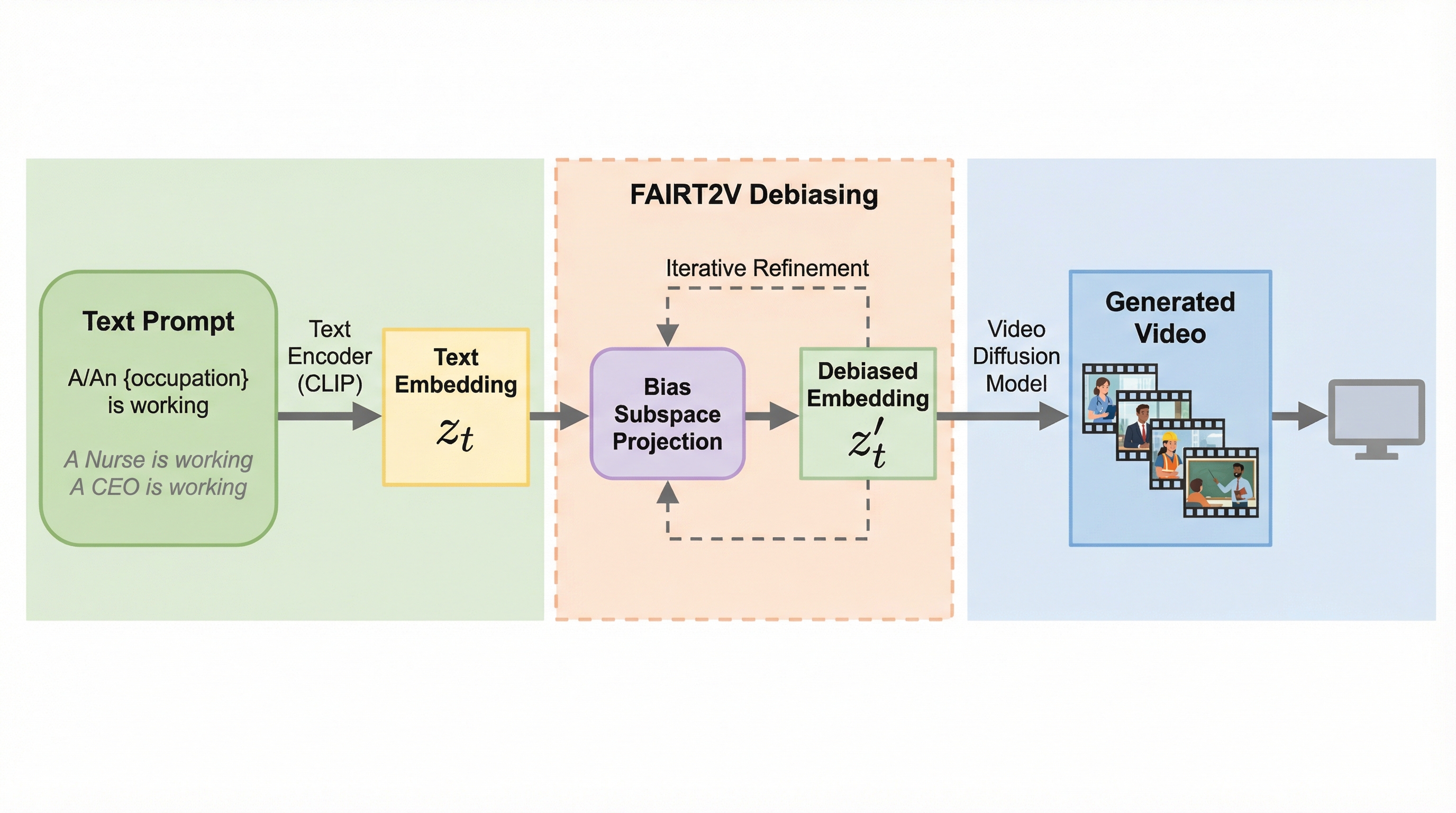
テキストから動画を生成する拡散モデル(T2V)において、特定の職業が特定の性別に偏って生成される深刻なジェンダーバイアスが存在することを特定し、その主な原因がCLIPなどの事前学習済みテキストエンコーダーにあることを詳細な分析によって明らかにしました。
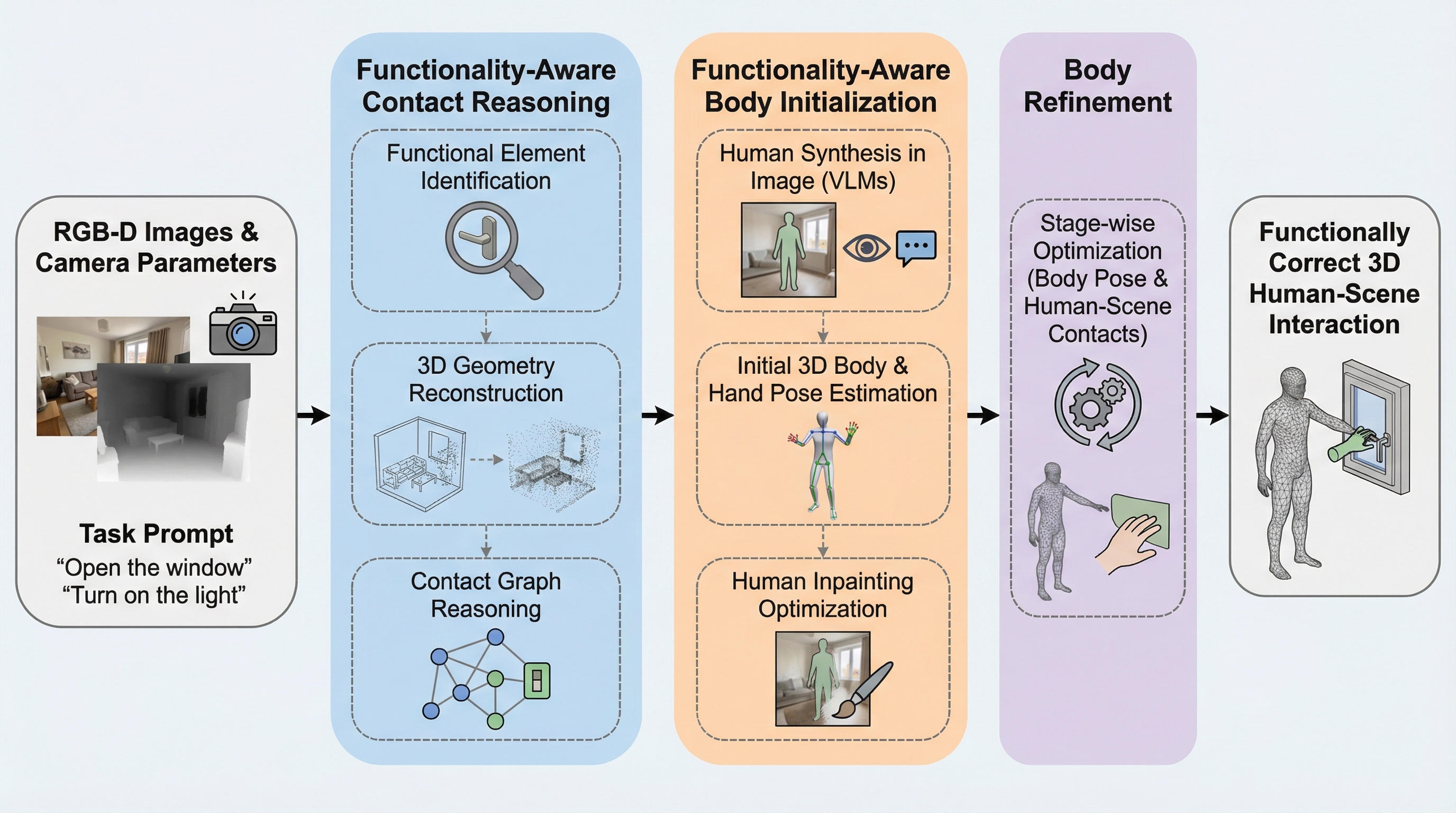
FunHSIは、事前の追加学習を必要としないトレーニングフリーなフレームワークであり、オープンボキャブラリーな指示に基づいて、3Dシーン内の特定の機能的要素と人間が正しく相互作用する様子を生成します。
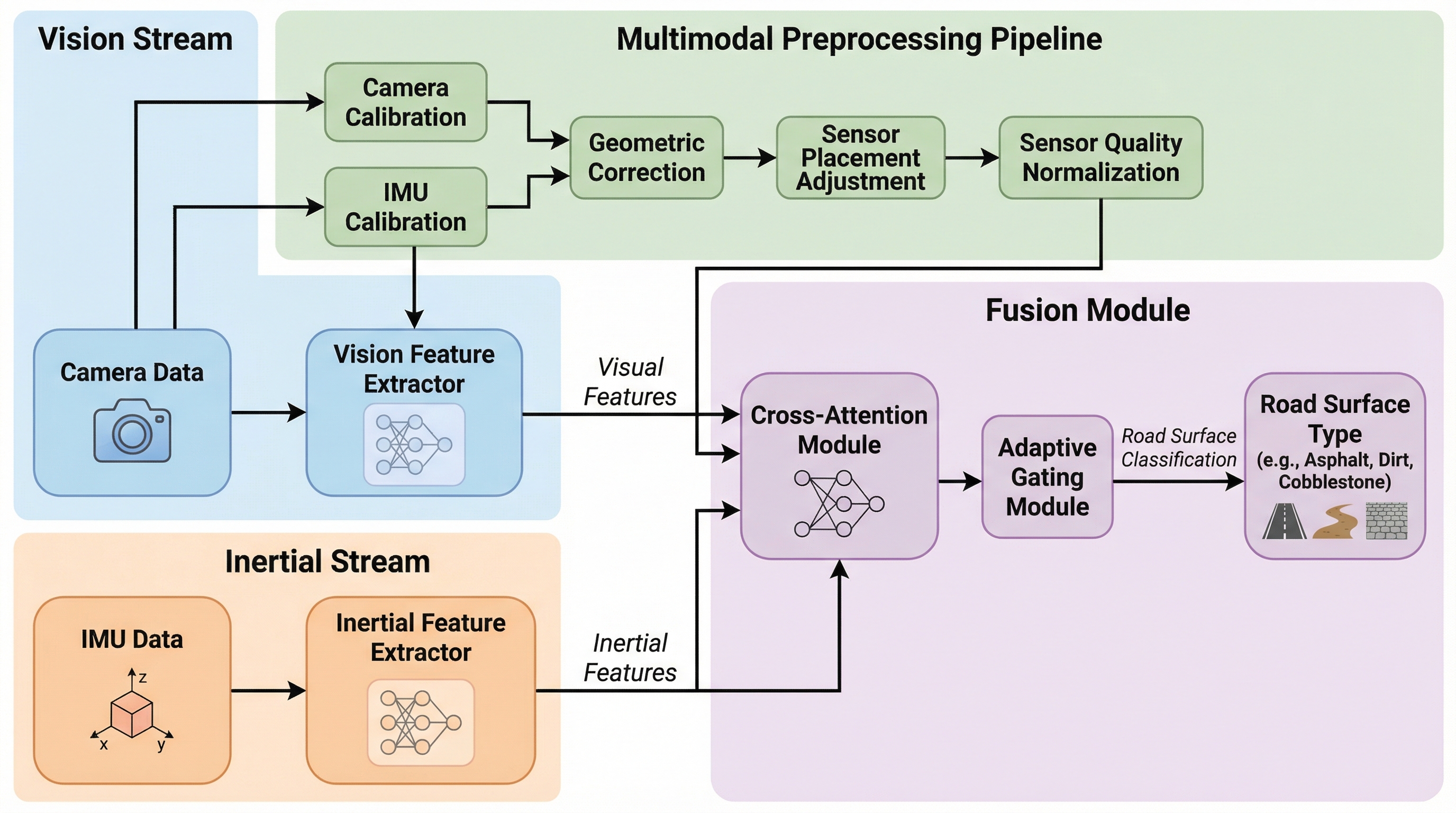
本研究は、カメラ画像と慣性計測装置(IMU)のデータを統合し、軽量な双方向クロスアテンションと適応型ゲーティング層を用いることで、夜間や豪雨、激しい砂埃といった過酷な環境下でも路面を正確に分類する新しいマルチモーダルフレームワークを提案しています。
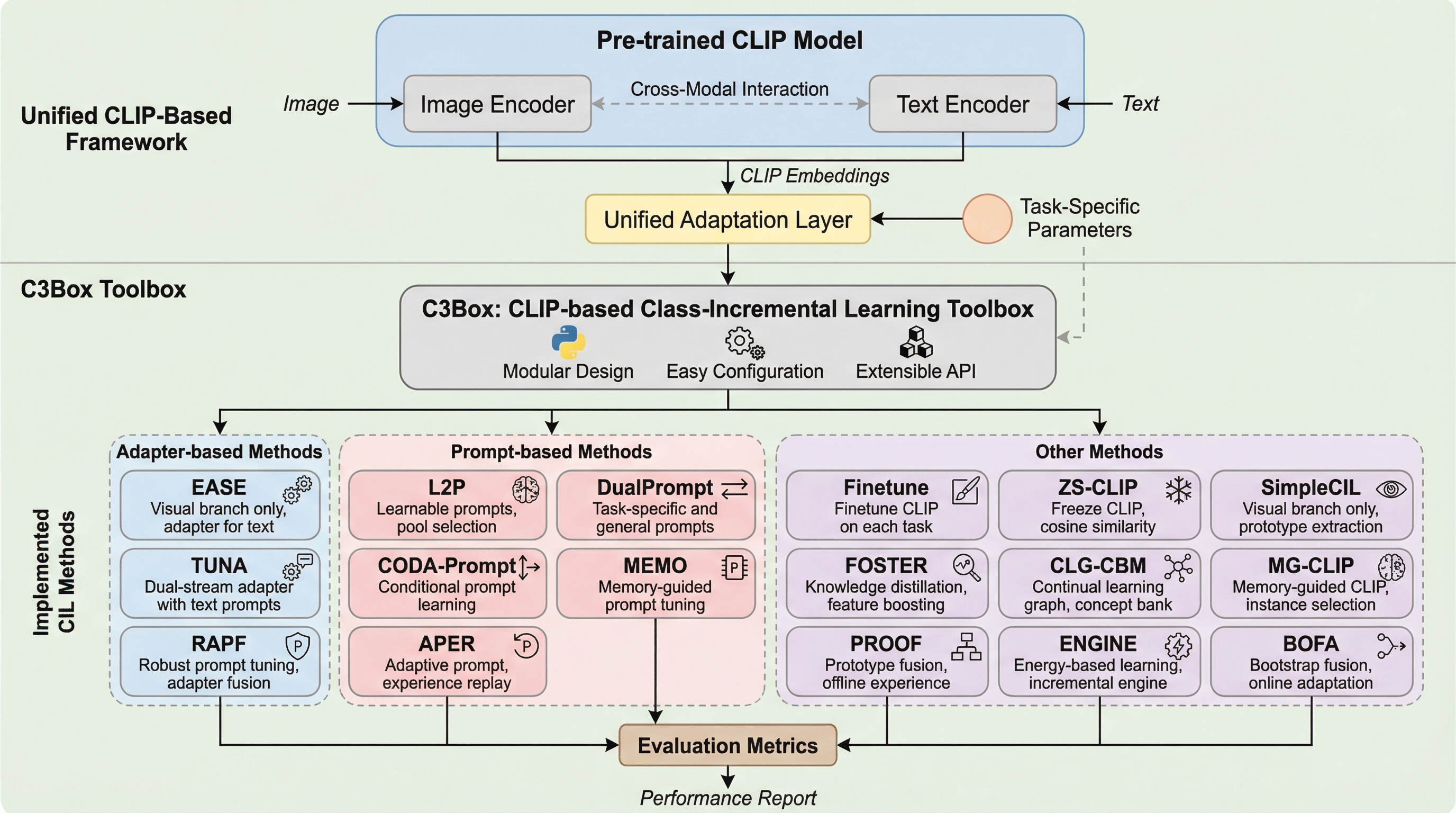
従来の深層学習は静的なデータ分布を前提としており、新しいクラスを順次学習する際に過去の知識を失う「破滅的忘却」が大きな課題となっていました。近年、CLIPのような事前学習済みモデルを活用したクラス増分学習(CIL)が注目されていますが、既存の手法は実装コードが分散しており、実験設定や評価指標が統一されていないため、公平な比較や再現が困難という問題がありました。 本研究では、CLIPを基盤としたクラス増分学習のためのモジュール化された包括的なPythonツールボックスである「C3Box」を提案し、伝統的な手法から最新のCLIP専用手法までを統合しました。C3Boxは、JSON形式の設定ファイルと標準化された実行パイプラインを採用することで、低いエンジニアリング負荷で再現性の高い実験を可能にし、研究者が新しい手法を容易に統合できる環境を提供します。 17種類の代表的な手法を10種類のベンチマークデータセットで検証した結果、CLIPベースの手法が従来のCIL手法を上回る性能を示すことが確認され、本ツールボックスが信頼性の高い評価プラットフォームであることが示されました。このツールボックスは、主要なOSをサポートし、広く普及しているオープンソースライブラリのみに依存しているため、コミュニティ全体での活用と継続的な発展が期待されます。