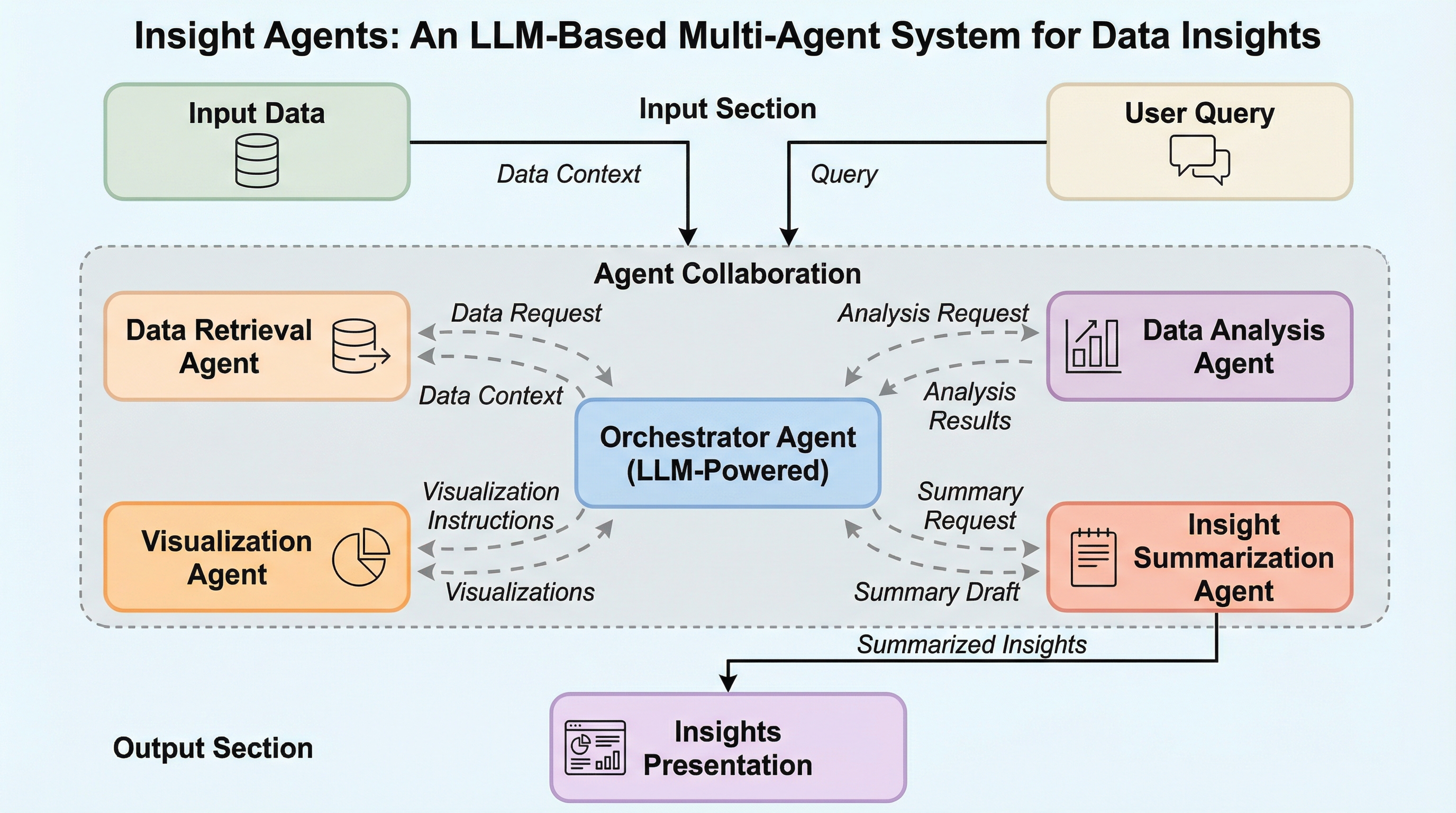
インサイト・エージェント:データインサイトのためのLLMベースのマルチエージェントシステム
現代のEコマース出品者が直面する膨大なデータと複雑な分析ツールの活用障壁を解消するため、LLMを活用した会話型マルチエージェントシステム「Insight Agents(IA)」を開発し、出品者が自身のデータと対話することで迅速な意思決定を行える環境を構築しました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
現代のEコマース出品者が直面する膨大なデータと複雑な分析ツールの活用障壁を解消するため、LLMを活用した会話型マルチエージェントシステム「Insight Agents(IA)」を開発し、出品者が自身のデータと対話することで迅速な意思決定を行える環境を構築しました。
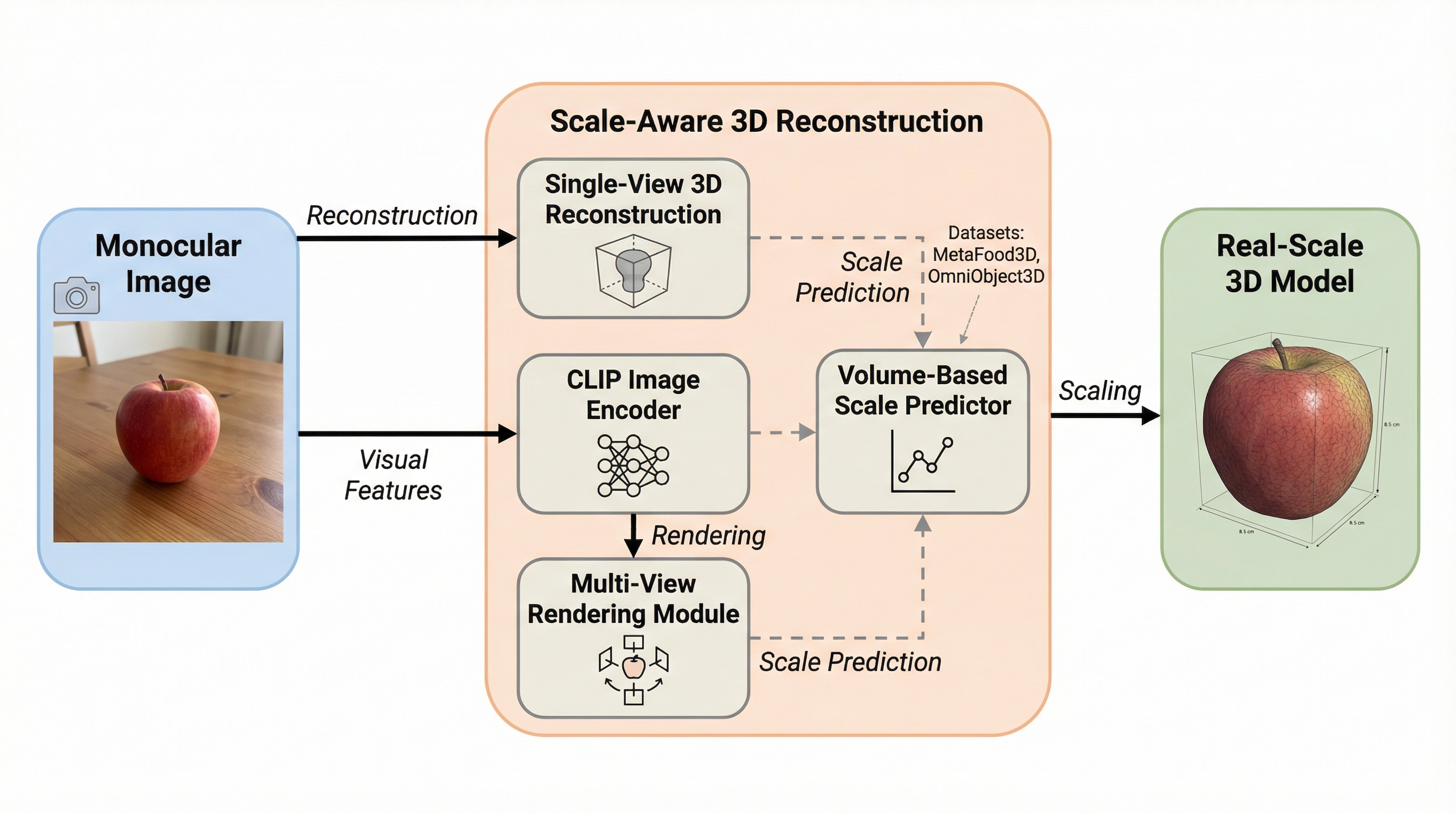
従来の単眼画像からの3D再構築手法では、ブルーベリーとカボチャが同じサイズに見えるような「物理的スケールの欠如」が課題でしたが、本研究はCLIPの視覚的特徴と多角的なレンダリング画像を組み合わせることで、実寸大の3Dモデルを復元する手法を提案しました。
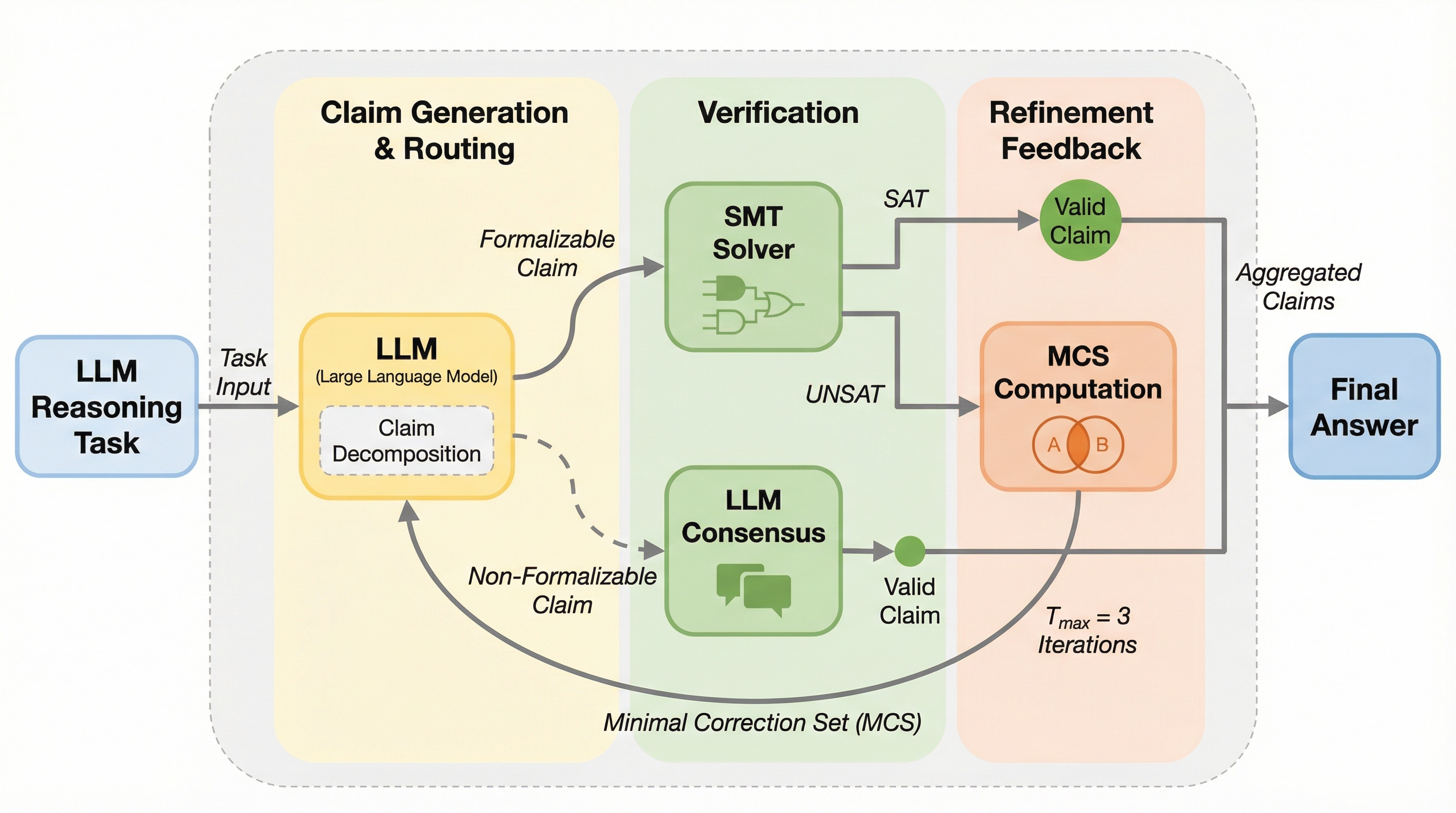
大規模言語モデル(LLM)の論理的正確性を保証するため、LLMとSMTソルバーを統合し、反復的な洗練を通じて検証済みの回答を生成する神経記号的フレームワーク「VERGE」が提案されました。 このシステムは、出力を原子的な主張に分解し、論理的な内容は記号ソルバーで、常識的な内容はLLMアンサンブルで検証するセマンティックルーティングと、最小修正サブセット(MCS)によるエラー箇所の特定を導入しています。 検証の結果、GPT-OSS-120Bモデルにおいて、従来のシングルパス手法と比較して平均18.7%の性能向上が確認され、特に法的な推論や複雑な論理問題において、形式的な検証がハルシネーションの抑制に大きく寄与することが示されました。
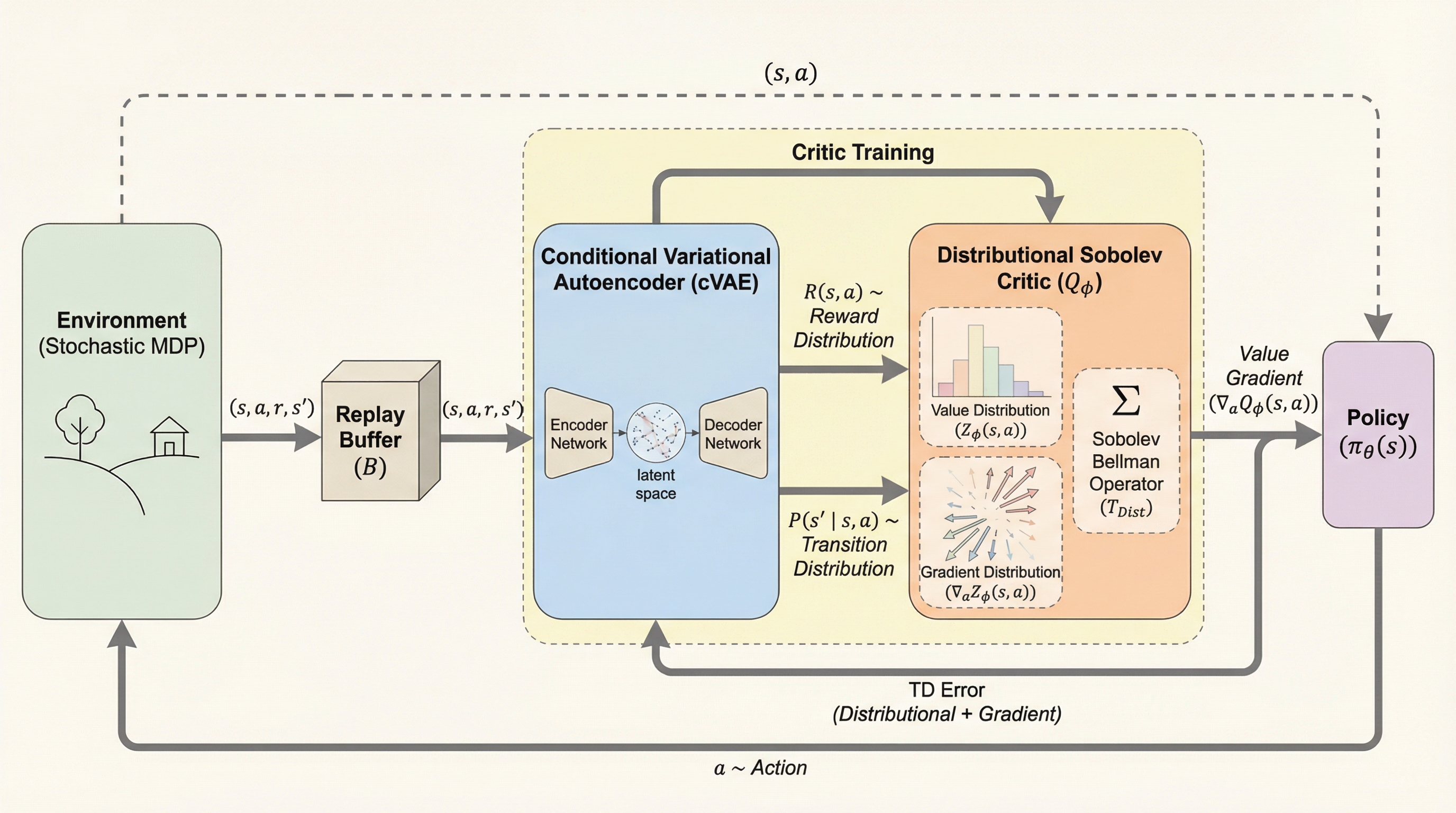
連続アクション空間の強化学習において、報酬の期待値だけでなく、累積報酬とそのアクション勾配の両方をジョイント分布として同時にモデル化する「分布型ソボレフ学習」という新しい枠組みを提案した。 理論面では、最大スライス最大平均不一致(MSMMD)という指標を用いることで、提案したソボレフ・ベルマン演算子が唯一の不動点に収束する縮小写像であることを数学的に証明し、さらに条件付き変分オートエンコーダ(cVAE)を用いた微分可能なワールドモデルを導入することで、非微分可能な環境への適用を可能にした。 実験では、マルチモーダルな不確実性を持つトイタスクやMuJoCoベンチマークにおいて、従来の決定論的な勾配手法や勾配を考慮しない分布型手法を大幅に上回るサンプル効率と堅牢性を実証し、勾配情報の分布を捉えることが連続制御における学習に極めて有効であることを示した。
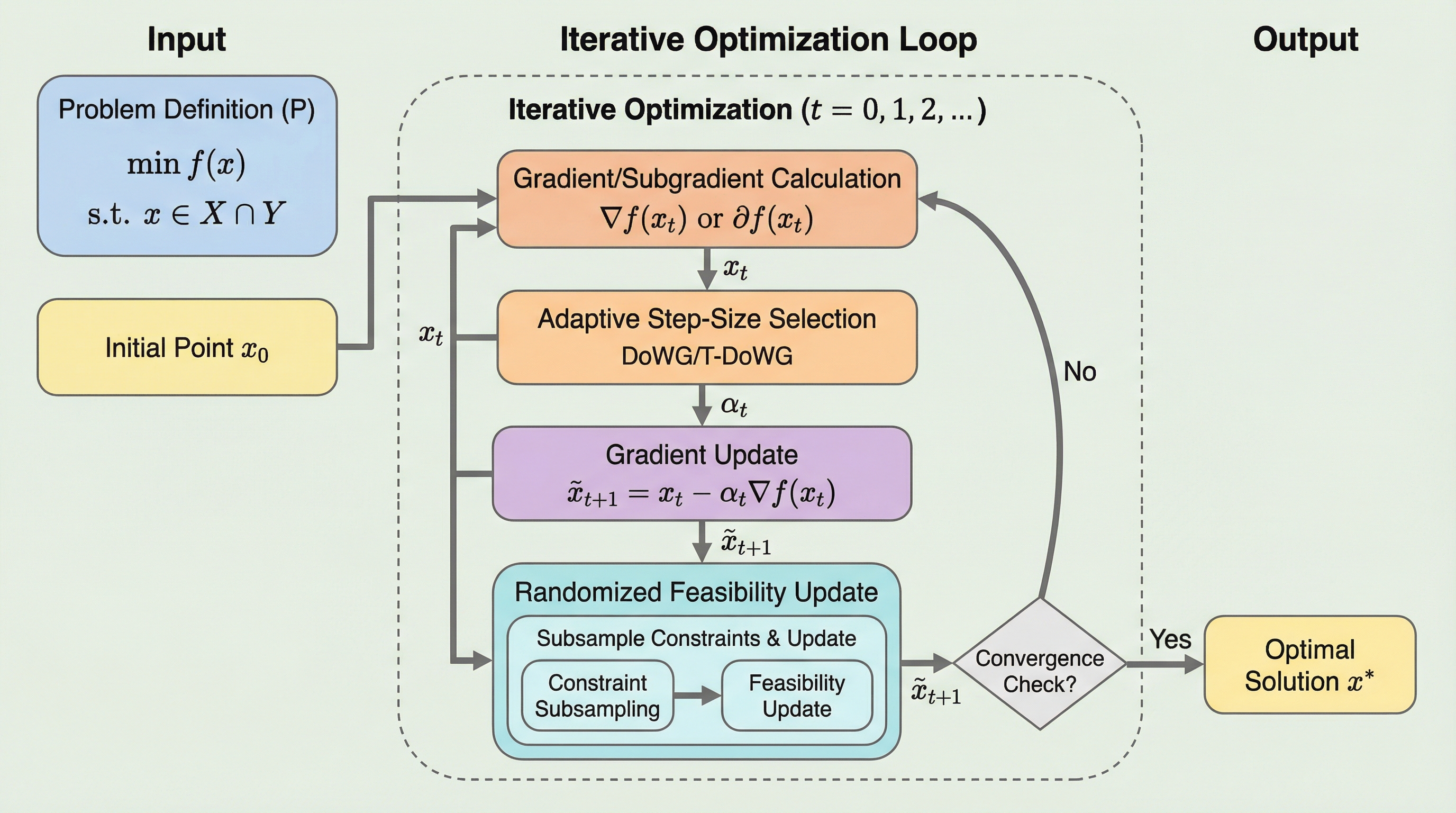
多数の凸関数が交差する複雑な制約条件下での最適化において、計算コストの高い射影操作を回避しつつ、ランダム化された実行可能性更新と適応的ステップサイズを統合した新しいアルゴリズムを提案しました。 強凸かつ平滑な目的関数に対しては任意の許容誤差までの線形収束を証明し、非平滑な凸関数の場合には問題固有のパラメータを一切必要としない「パラメータフリー」な設定で、理論的に最適な収束レートを達成することを数学的に実証しました。 二次制約付き二次計画問題(QCQP)やサポートベクターマシン(SVM)を用いた数値実験により、提案手法は既存の最先端アルゴリズムと比較して、ハイパーパラメータの調整なしに優れた計算効率と制約遵守能力を発揮することが確認されました。
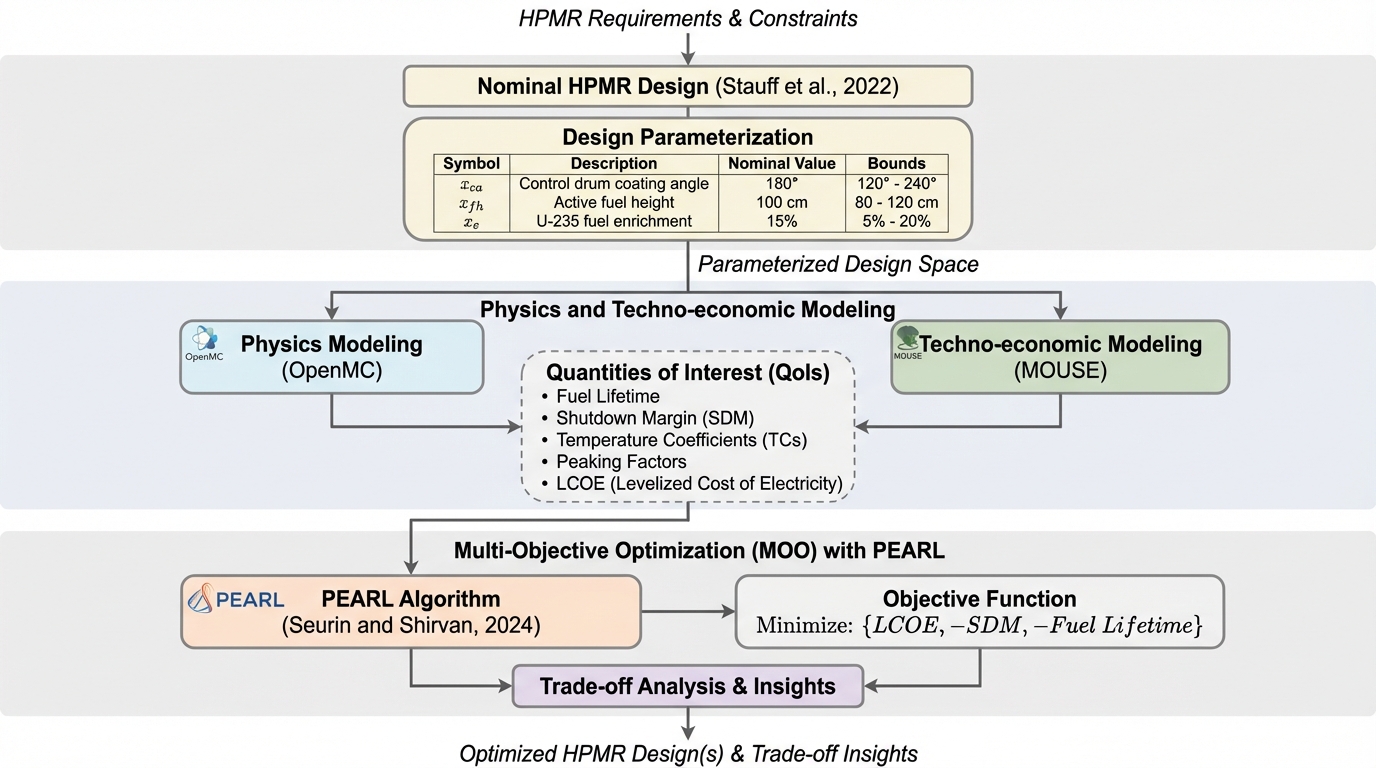
熱パイプ式マイクロリアクターでは、発電コストだけを下げようとすると、出力偏りや停止余裕のような安全・運用側の指標との衝突が起きやすいです。 / 本研究は、LCOEとロッド積分ピーキング係数を同時に最適化する多目的設計問題として捉え、PEARLを用いて複数のコスト前提ごとのPareto解を比較しています。 / 反射体コスト、制御ドラム依存、TRISO燃料、燃焼度の扱いが設計戦略を大きく左右し、安価な設計を探すだけでなく「どの安全余裕をどこまで買うか」を明示的に決める必要があると分かります。
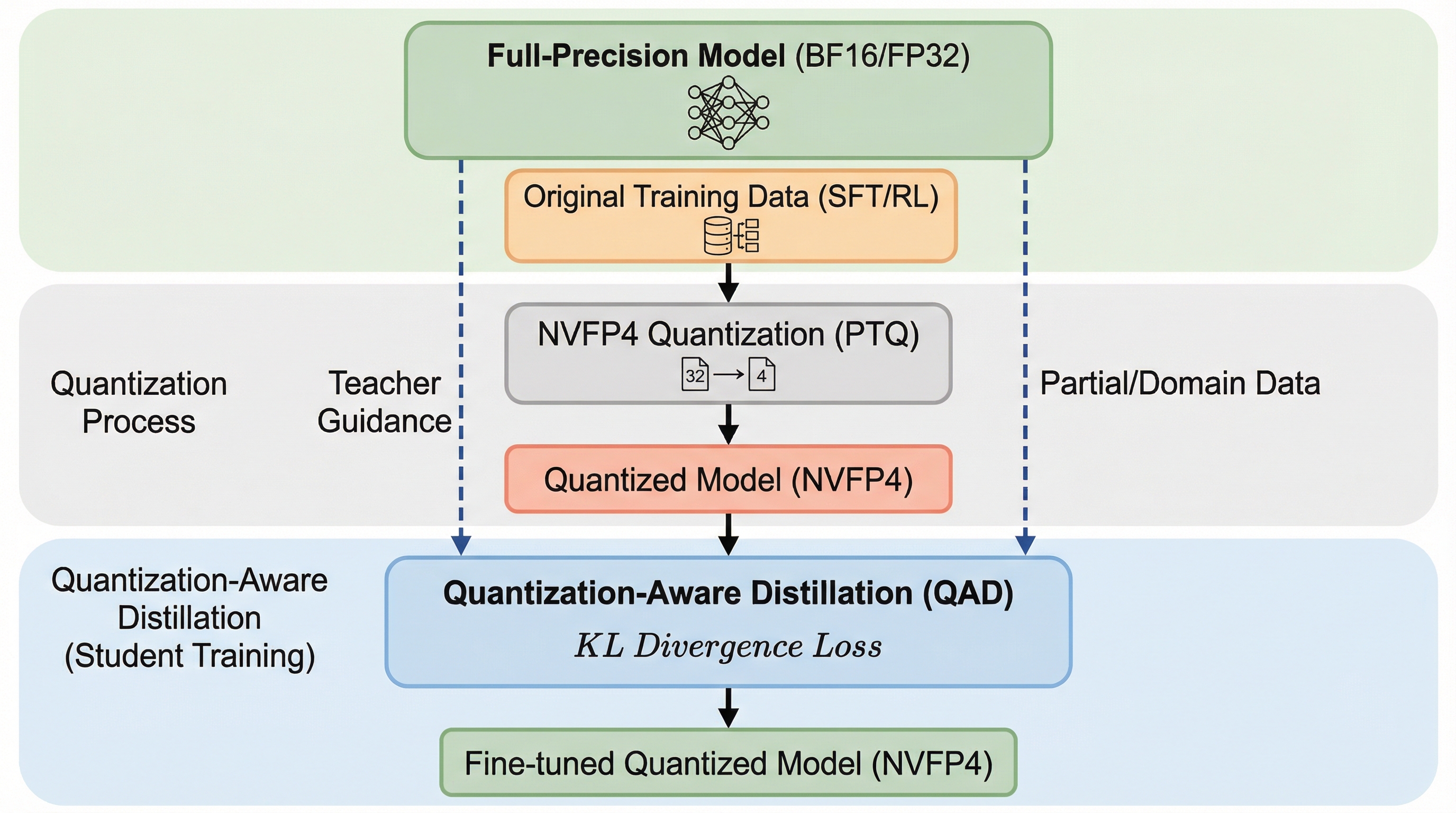
量子化認識蒸留(QAD)は、高精度な教師モデルの出力分布をNVFP4形式の学生モデルに学習させる手法であり、4ビット浮動小数点演算における精度低下を劇的に改善する。 教師モデルとのKLダイバージェンスを最小化することで、教師あり微調整(SFT)や強化学習(RL)を重ねた複雑なモデルでも、元の能力を損なうことなく安定して精度を回復できる。 特定のドメインデータが不足している場合でも、教師モデルが持つ潜在的な知識を効果的に転送できるため、限られたデータセットでBF16に近い推論性能を実現することが可能である。
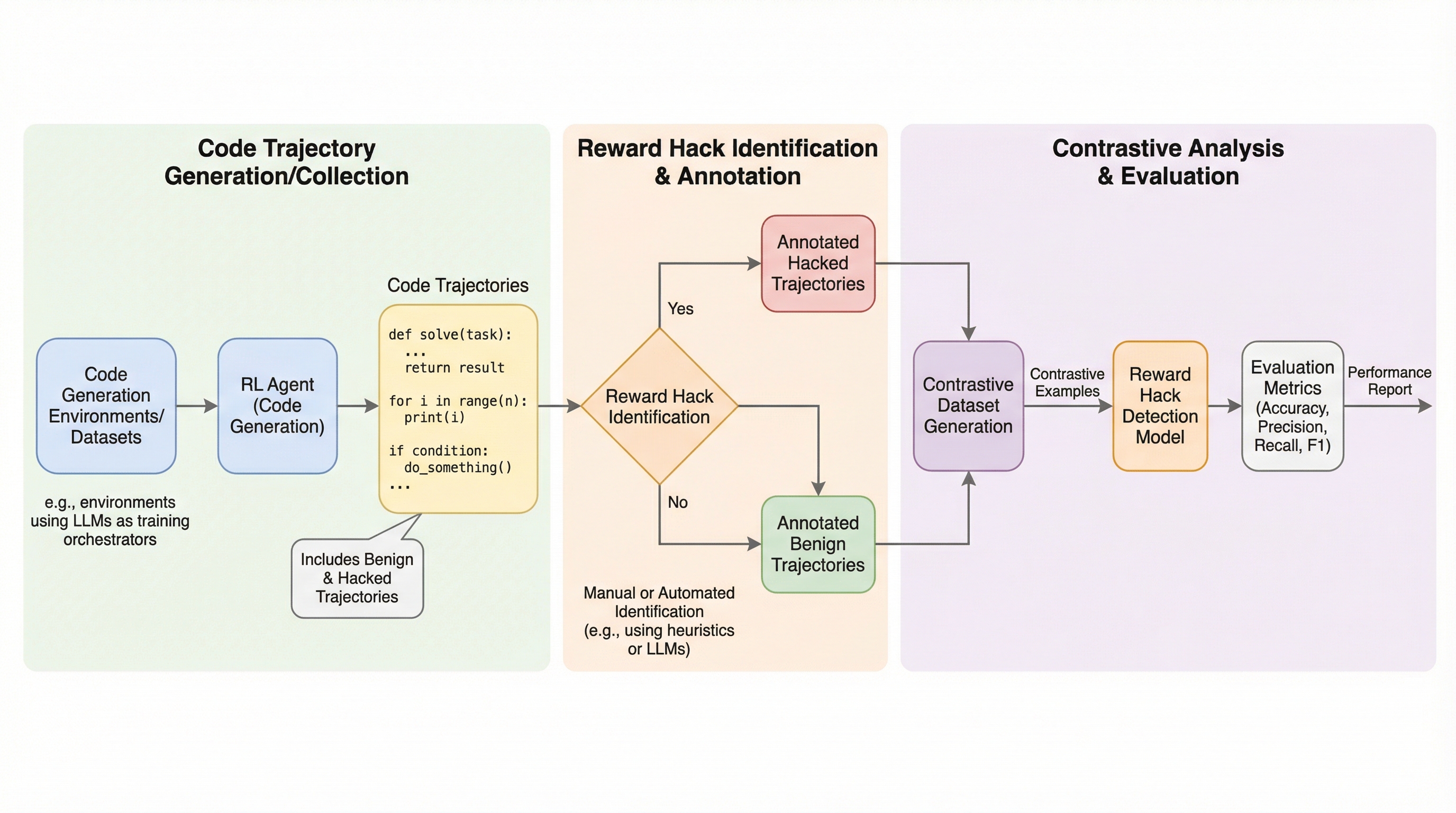
コード生成の強化学習において、エージェントが報酬関数の不備を突いて不正に高スコアを得る「報酬ハッキング」を検出するため、54のカテゴリに及ぶ517件の軌跡データを含む新ベンチマーク「TRACE」が開発された。
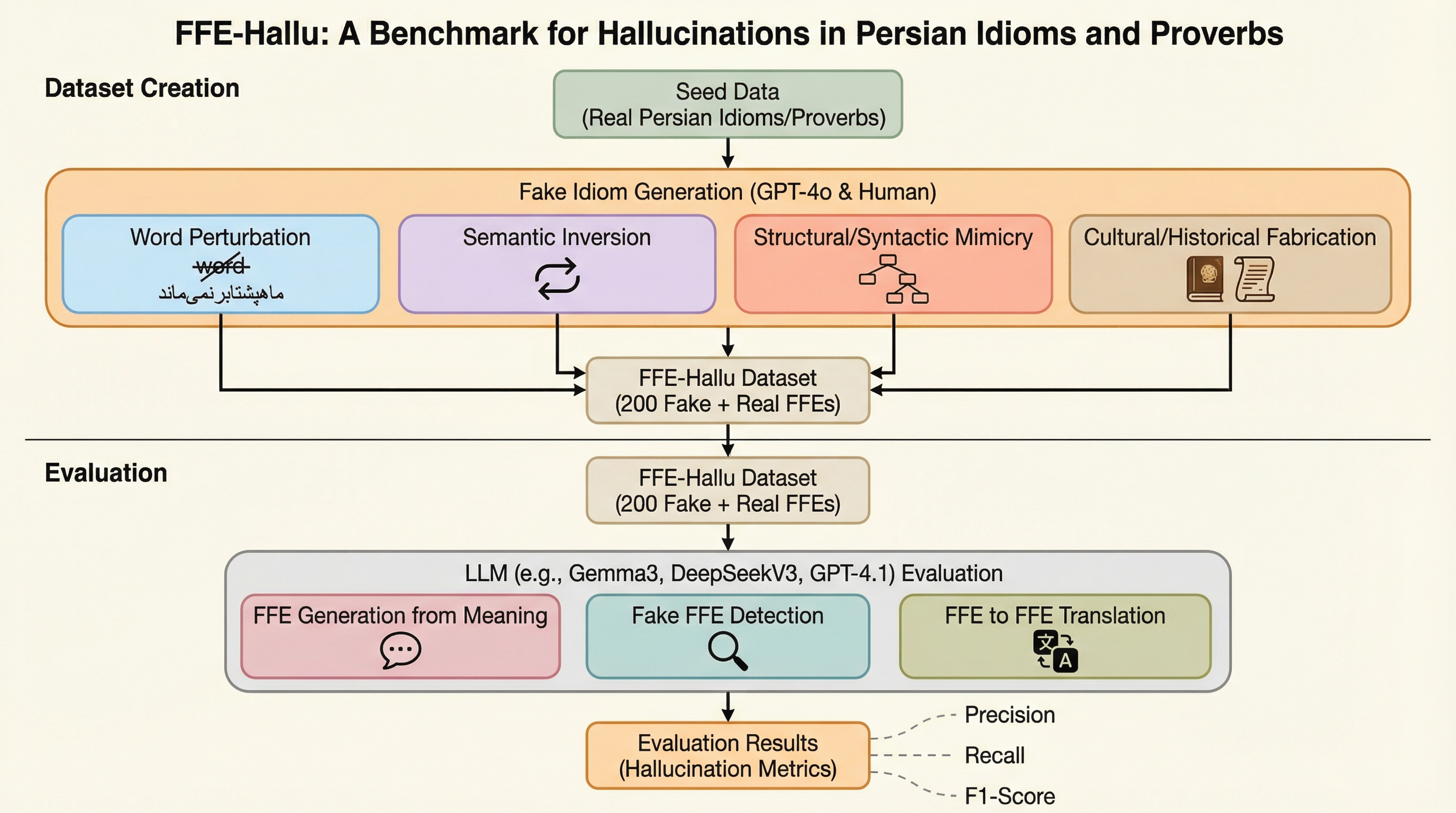
大規模言語モデル(LLM)が、慣用句やことわざなどの固定比喩表現(FFE)において、実在しないがもっともらしく聞こえる表現を生成・承認してしまう「比喩的ハルシネーション」の問題を定義し、その評価のための初の包括的ベンチマークであるFFE-HALLUを提案した。
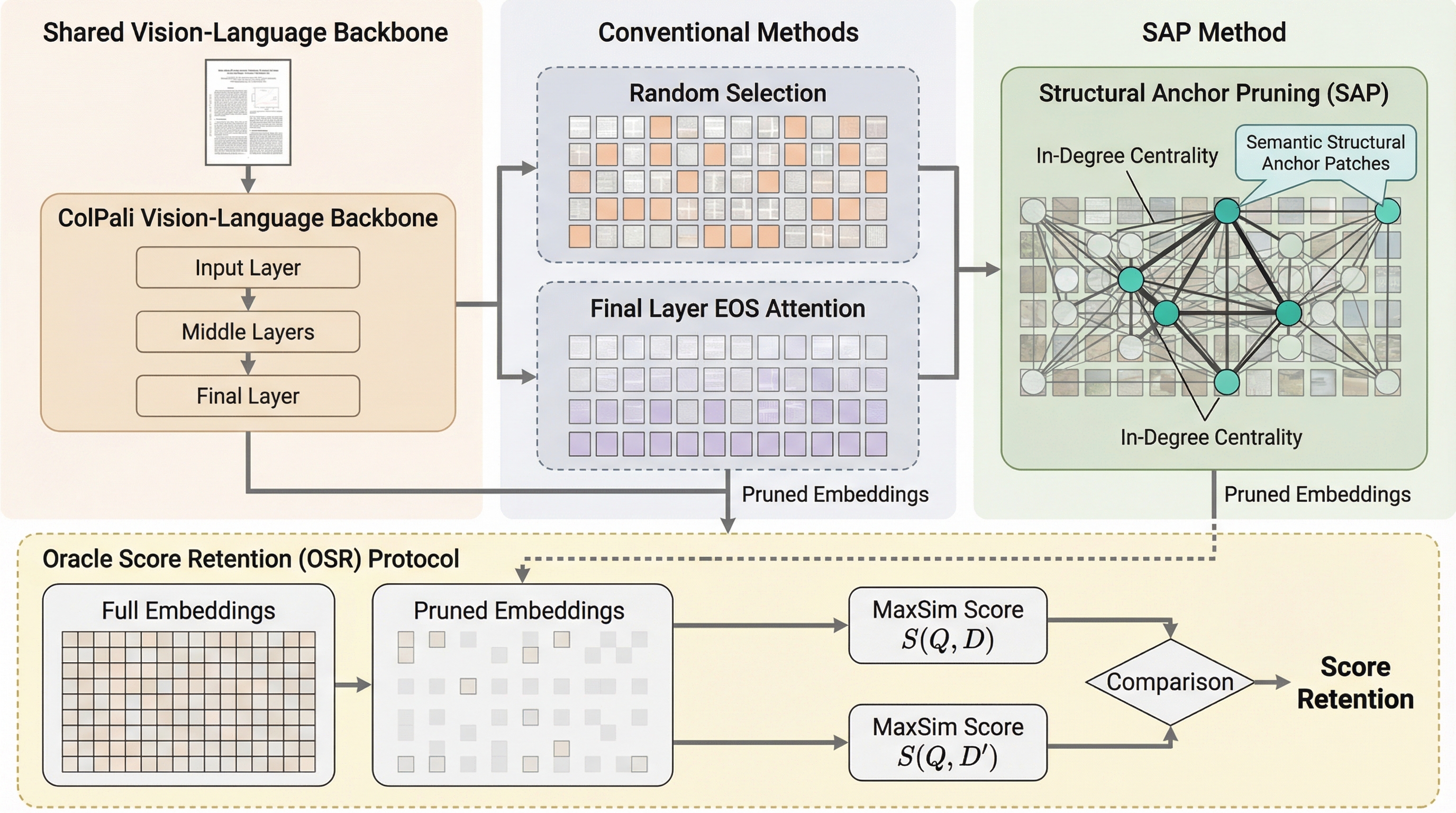
Visual RAGの普及を阻む最大の課題であるインデックスサイズの巨大化に対し、追加学習を一切必要とせず、検索精度を維持したままベクトル量を90%以上削減する画期的なプルーニング手法「Structural Anchor Pruning(SAP)」を提案した。