FFE-Hallu: ペルシャ語の慣用句やことわざにおけるハルシネーション(幻覚)のベンチマーク
大規模言語モデル(LLM)が、慣用句やことわざなどの固定比喩表現(FFE)において、実在しないがもっともらしく聞こえる表現を生成・承認してしまう「比喩的ハルシネーション」の問題を定義し、その評価のための初の包括的ベンチマークであるFFE-HALLUを提案した。
TL;DR(結論)
大規模言語モデル(LLM)が、慣用句やことわざなどの固定比喩表現(FFE)において、実在しないがもっともらしく聞こえる表現を生成・承認してしまう「比喩的ハルシネーション」の問題を定義し、その評価のための初の包括的ベンチマークであるFFE-HALLUを提案した。 このベンチマークはペルシャ語を対象とし、意味からの表現生成、偽の表現の検知、英語からペルシャ語への比喩表現翻訳という3つの補完的なタスクで構成されており、合計600の厳選された事例を用いてモデルの比喩的能力と文化的背景の理解度を多角的に測定する。 GPT-4.1やClaude 3.7 Sonnetを含む6つの最新LLMを評価した結果、多くのモデルが実在する表現と巧妙に作られた偽物を区別することに苦戦しており、特に言語をまたぐ翻訳においてハルシネーションが頻繁に発生するという、現在のモデルにおける系統的な弱点と文化的知識の欠如が明らかになった。
なぜこの問題か
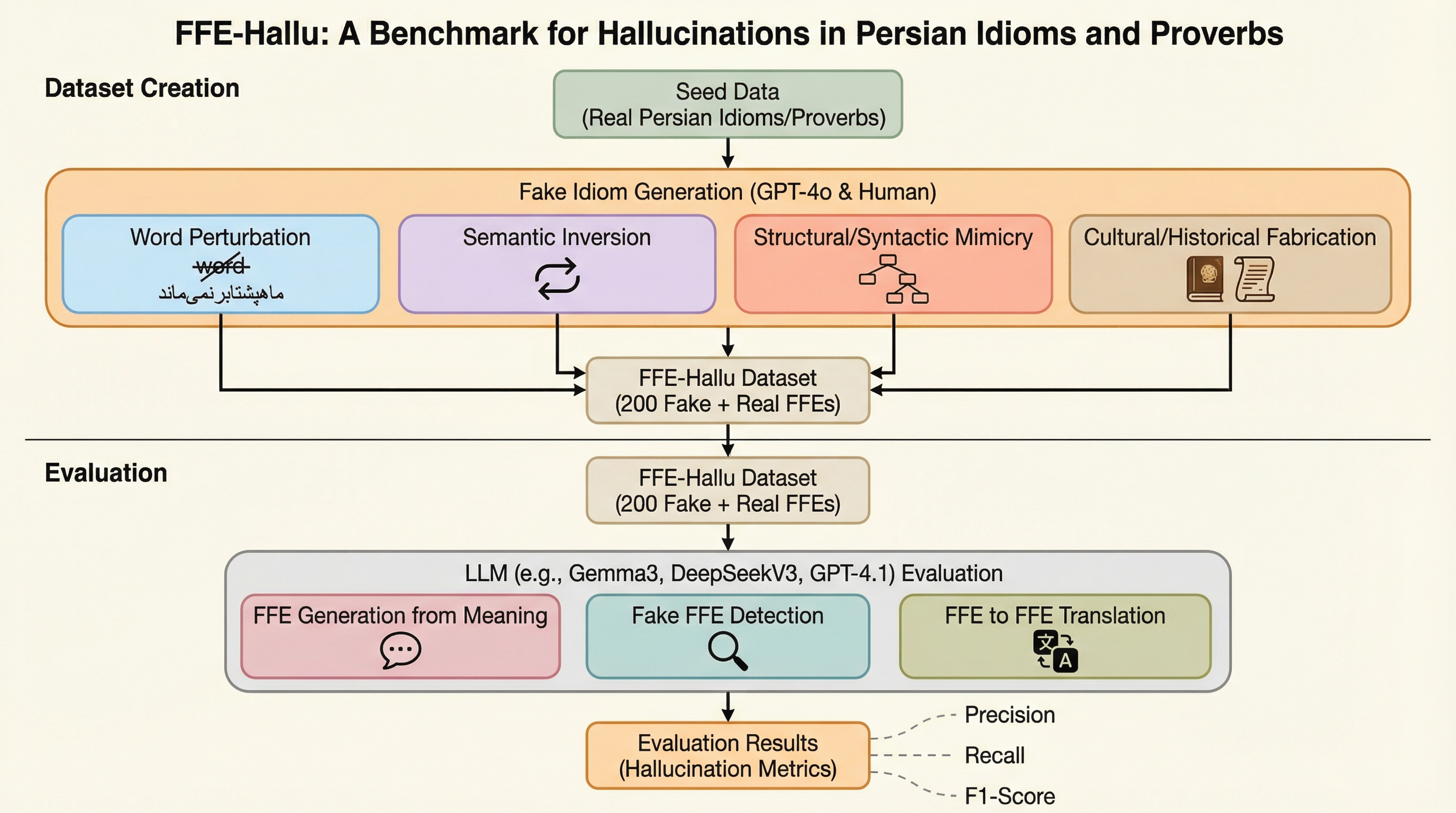
大規模言語モデルは多くの自然言語処理タスクで成功を収めているが、比喩的な言語、特に慣用句やことわざのような「固定比喩表現(FFE)」の扱いに依然として苦労している。 これらの表現は、構成要素となる個々の単語の意味を組み合わせるだけでは全体の意味を導き出せない「非構成性」という特徴を持っており、その言語が使われる文化に深く根ざしている。 例えば「バケツを蹴る(死ぬ)」という慣用句では、特定の単語が不可欠であり、文脈に関わらずその語彙的・構造的なアイデンティティが維持される必要がある。 このような固定性は、モデルがもっともらしく聞こえるが実在しない表現を生成したり、それを正しいと認めたりする「比喩的ハルシネーション」を引き起こす原因となっている。 比喩的ハルシネーションは、事実に関するハルシネーションとは異なり、外部の事実確認だけでは特定が難しく、深い言語的・文化的知識を必要とする。 また、人間は馴染みのある形式の文章を真実だと信じやすい「真実性の錯覚」という心理的効果の影響を受けるため、もっともらしい偽の慣用句はユーザーの信頼を損なうリスクがある。…
核心:何を提案したのか
本研究では、LLMの比喩的および文化的能力を評価し、ハルシネーションの挙動を調査するためのベンチマーク「FFE-HALLU」を提案した。 このベンチマークは、言語的に豊かでありながら研究例が少ないペルシャ語に焦点を当てて設計されており、合計600のテスト事例を含んでいる。 具体的には、3つの主要なタスクを通じてモデルの能力を多角的に検証する構成となっている。 第一のタスクは「意味からのFFE生成」であり、与えられた比喩的な定義に基づいて、適切な慣用句やことわざをモデルが想起できるかをテストする。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related