NVFP4推論精度回復のための量子化認識蒸留(QAD)
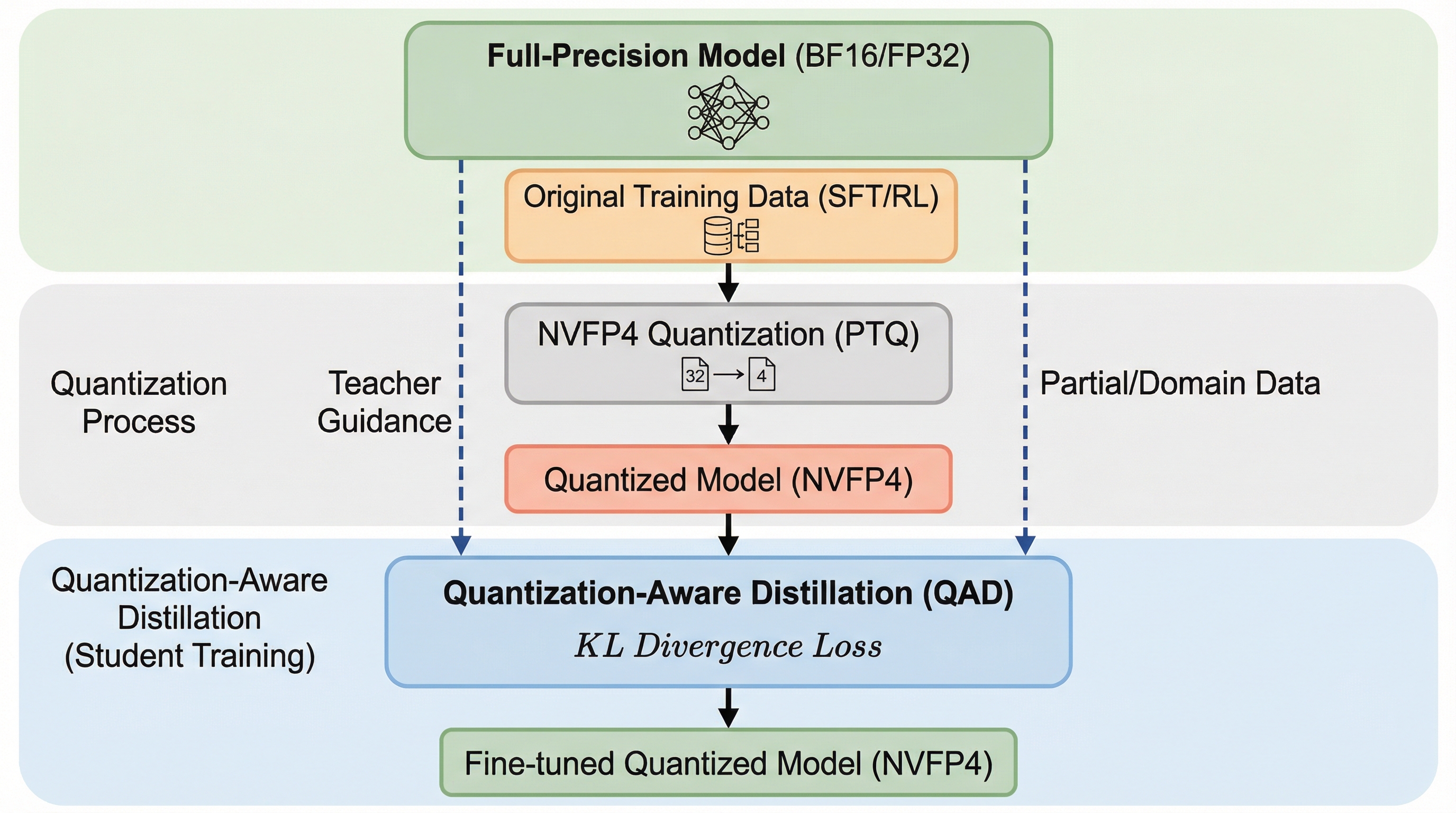
量子化認識蒸留(QAD)は、高精度な教師モデルの出力分布をNVFP4形式の学生モデルに学習させる手法であり、4ビット浮動小数点演算における精度低下を劇的に改善する。 教師モデルとのKLダイバージェンスを最小化することで、教師あり微調整(SFT)や強化学習(RL)を重ねた複雑なモデルでも、元の能力を損なうことなく安定して精度を回復できる。 特定のドメインデータが不足している場合でも、教師モデルが持つ潜在的な知識を効果的に転送できるため、限られたデータセットでBF16に近い推論性能を実現することが可能である。
TL;DR(結論)
量子化認識蒸留(QAD)は、高精度な教師モデルの出力分布をNVFP4形式の学生モデルに学習させる手法であり、4ビット浮動小数点演算における精度低下を劇的に改善する。 教師モデルとのKLダイバージェンスを最小化することで、教師あり微調整(SFT)や強化学習(RL)を重ねた複雑なモデルでも、元の能力を損なうことなく安定して精度を回復できる。 特定のドメインデータが不足している場合でも、教師モデルが持つ潜在的な知識を効果的に転送できるため、限られたデータセットでBF16に近い推論性能を実現することが可能である。
なぜこの問題か
大規模言語モデル(LLM)の急速な拡大に伴い、推論時や学習時における計算コスト、メモリ需要、およびエネルギー消費を削減するために、より効率的な数値フォーマットが求められている。 8ビット浮動小数点フォーマット(FP8)は、すでにLLMの加速学習において一般的なデータ型として定着しているが、さらなる効率化を目指す次なるステップとして、4ビット浮動小数点(FP4)が注目されている。 特にNVFP4フォーマットは、従来のFP8と比較して算術スループットを2倍から3倍に向上させ、メモリ使用量を約半分に削減できる可能性を秘めている。 NVFP4は、MXFP4形式を拡張したものであり、ブロックサイズを32から16に縮小し、2段階のスケーリング(各ブロックのE4M3スケールとテンソルごとのFP32スケール)を導入することで、INT4やMXFP4よりも優れた精度を示すことが報告されている。 しかし、非常に巨大なLLMでは学習後量子化(PTQ)のみで十分な精度が得られる場合もあるが、比較的小規模なLLMや、特定のタスクに特化したモデルでは、PTQによる精度の低下が無視できないレベルで発生するという課題がある。…
核心:何を提案したのか
本報告では、NVFP4量子化されたLLMおよび視覚言語モデル(VLM)の推論精度を回復させるための手法として、量子化認識蒸留(QAD)を提案している。 QADは、元のフル精度(BF16など)のモデルを「教師」とし、量子化されたモデルを「学生」として、教師モデルの出力分布を学生モデルに模倣させる手法である。 この手法の最大の特徴は、タスク固有の損失関数(例えば言語モデリングにおける次トークン予測のクロスエントロピー損失)を使用するのではなく、教師と学生の間のKLダイバージェンス損失を最小化することに焦点を当てている点にある。 QADは、従来のQATと比較して、量子化モデルを元の高精度モデルの出力分布により忠実に整列させることができる。 特に、SFTやRL、モデルマージを経て構築されたモデルにおいて、QADは訓練の安定性を保ちながら、BF16に近い精度まで回復させることが可能である。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related