VERGE:検証可能なLLM推論のための形式的洗練およびガイダンスエンジン
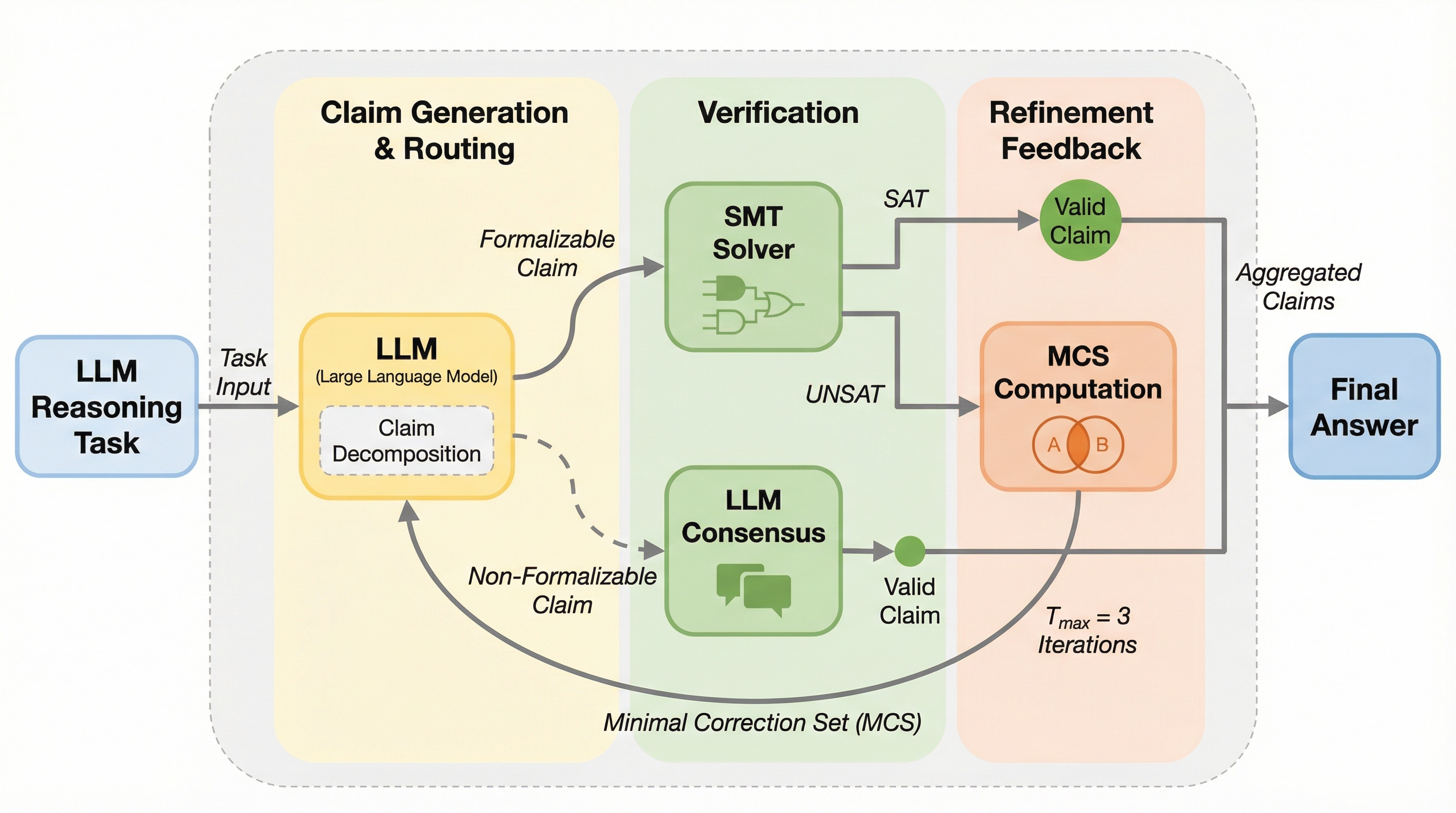
大規模言語モデル(LLM)の論理的正確性を保証するため、LLMとSMTソルバーを統合し、反復的な洗練を通じて検証済みの回答を生成する神経記号的フレームワーク「VERGE」が提案されました。 このシステムは、出力を原子的な主張に分解し、論理的な内容は記号ソルバーで、常識的な内容はLLMアンサンブルで検証するセマンティックルーティングと、最小修正サブセット(MCS)によるエラー箇所の特定を導入しています。 検証の結果、GPT-OSS-120Bモデルにおいて、従来のシングルパス手法と比較して平均18.7%の性能向上が確認され、特に法的な推論や複雑な論理問題において、形式的な検証がハルシネーションの抑制に大きく寄与することが示されました。
TL;DR(結論)
大規模言語モデル(LLM)の論理的正確性を保証するため、LLMとSMTソルバーを統合し、反復的な洗練を通じて検証済みの回答を生成する神経記号的フレームワーク「VERGE」が提案されました。 このシステムは、出力を原子的な主張に分解し、論理的な内容は記号ソルバーで、常識的な内容はLLMアンサンブルで検証するセマンティックルーティングと、最小修正サブセット(MCS)によるエラー箇所の特定を導入しています。 検証の結果、GPT-OSS-120Bモデルにおいて、従来のシングルパス手法と比較して平均18.7%の性能向上が確認され、特に法的な推論や複雑な論理問題において、形式的な検証がハルシネーションの抑制に大きく寄与することが示されました。
なぜこの問題か
大規模言語モデルは、数学的な問題解決やコード生成、論理推論など、多様なタスクにおいて驚異的な能力を示していますが、法務、医療、金融などの高い信頼性が求められる領域において、その論理的な正確性を保証することは依然として根本的な課題となっています。現在の主要なモデルは、論理的な演繹ではなく統計的な尤度最大化に依存して動作しているため、証明可能な正確性を保証するメカニズムを欠いており、ハルシネーションや内部矛盾を引き起こしやすいという性質があります。既存の検証戦略として、自己整合性やプロセス監視、自己洗練などが提案されていますが、これらはあくまでヒューリスティックな手法であり、形式的な保証を与えるものではありません。また、複数のエージェントによる討論フレームワークも、単に合意を形成するだけであり、その合意内容が真実であることを意味するわけではないという問題があります。 モデルが自身の推論を批判する自己修正手法も、推論過程と最終的な出力が一致しない「忠実性の欠如」により、かえって性能を低下させることが報告されています。さらに、自然言語と形式論理の間には「セマンティック・ギャップ(意味的な溝)」が存在します。…
核心:何を提案したのか
本研究では、LLMとSatisfiability Modulo Theories(SMT)ソルバーを組み合わせた神経記号的フレームワーク「VERGE」を提案しています。VERGEの核心は、LLMが生成した回答を原子的な主張に分解し、それらを自動的に一階述語論理へと形式化して、自動定理証明器を用いて論理的な一貫性を検証する点にあります。このフレームワークには、主に3つの革新的な機能が含まれています。第一に、形式的な意味等価性チェックを用いたマルチモデル合意形成です。これは、候補となる形式化の間の論理レベルでの整合性を確認することで、表面的な構文の類似性に依存しない堅牢な合意を実現します。 第二に、セマンティックルーティングです。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related