ファインチューニングされた拡散言語モデルに対するメンバーシップ推論攻撃
拡散型言語モデル(DLM)は双方向の文脈を利用する特性を持つが、学習データの記憶に伴うプライバシー漏洩リスク、特に特定のデータが学習に含まれるかを判定するメンバーシップ推論攻撃(MIA)への耐性は未解明であった。
TL;DR(結論)
拡散型言語モデル(DLM)は双方向の文脈を利用する特性を持つが、学習データの記憶に伴うプライバシー漏洩リスク、特に特定のデータが学習に含まれるかを判定するメンバーシップ推論攻撃(MIA)への耐性は未解明であった。本研究は、DLMの多様なマスク構成が攻撃の機会を指数関数的に増加させることに着目し、段階的なマスク密度と符号ベースの統計量を組み合わせることで、ノイズに埋もれた微弱な記憶信号を頑健に抽出する新手法「SAMA」を提案した。実験の結果、SAMAは既存手法と比較してAUCを相対的に30%向上させ、低い誤検知率において最大8倍の精度改善を達成しており、DLMが微調整時に学習データを記憶しやすいという深刻な脆弱性を抱えていることを明らかにした。
なぜこの問題か
現在、大規模言語モデル(LLM)の主流は、次のトークンを順番に予測する自己回帰型モデル(ARM)であるが、これに代わる有望な選択肢として拡散型言語モデル(DLM)が急速に台頭している。DLMは、ランダムにマスクされたトークンを双方向の文脈から復元するように学習されるモデルであり、スケーラビリティの高さや、自己回帰型モデルが抱える「逆転の呪い」などの制限を克服できる可能性から注目を集めている。GoogleのGemini Diffusionなどの産業界での展開も、このパラダイムの重要性を裏付けている。しかし、LLMが学習データを記憶してしまうことによるプライバシーリスクは、これまで主に自己回帰型モデルにおいて研究されてきた。特定のデータサンプルがモデルの訓練セットに含まれていたかどうかを判断するメンバーシップ推論攻撃(MIA)は、こうしたリスクを定量化するための主要なベンチマークであるが、DLM特有のアーキテクチャや学習メカニズムがプライバシーにどのような影響を与えるかは、これまでほとんど解明されていなかった。…
核心:何を提案したのか
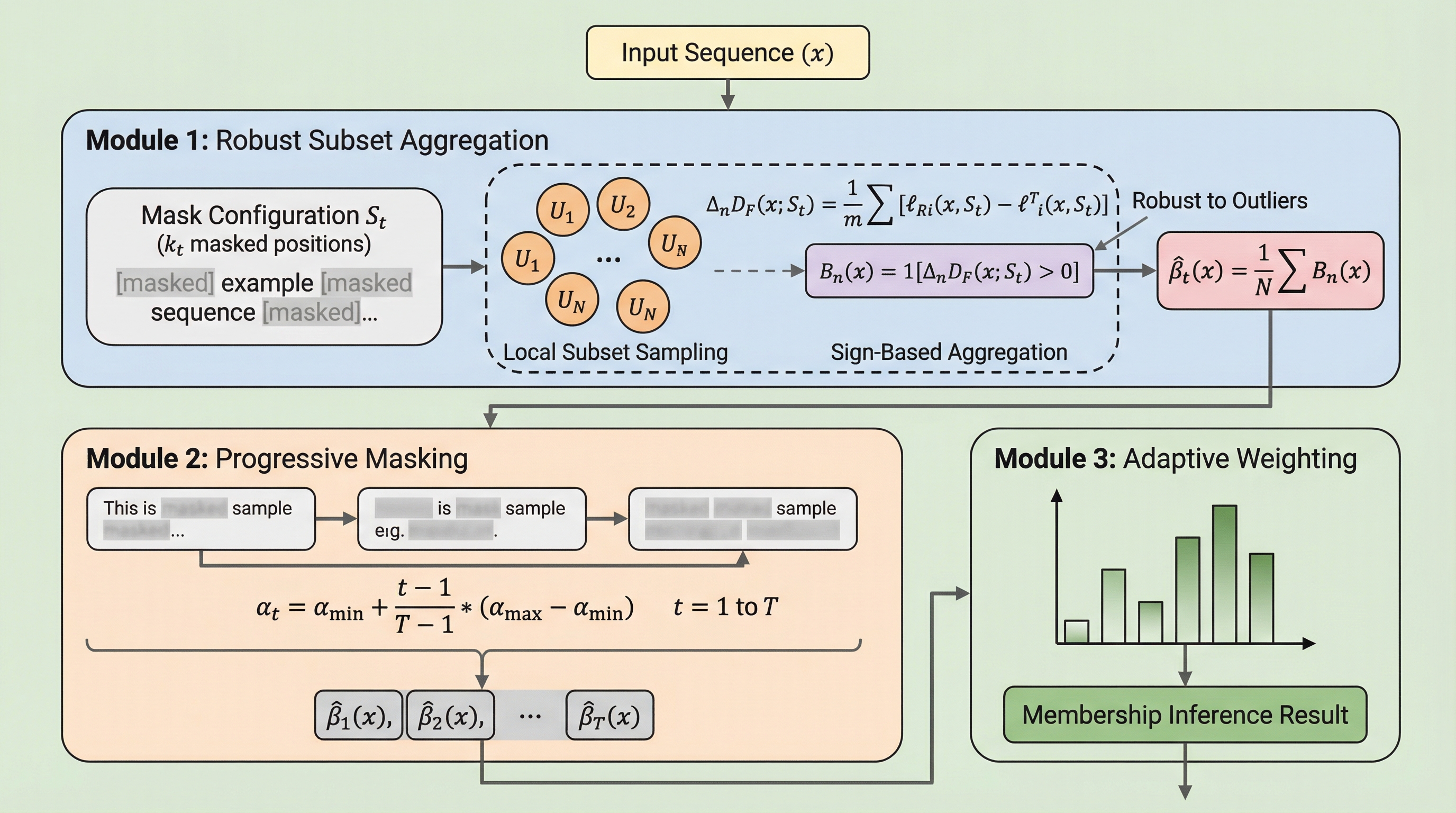
本研究では、DLMの独自のアーキテクチャ特性を突く新しいメンバーシップ推論攻撃フレームワーク「SAMA(Subset-Aggregated Membership Attack)」を提案した。SAMAの核心的なアイデアは、DLMが持つ「多様なマスク構成を試せる」という利点を最大限に活用し、ノイズの多い信号の中から一貫した記憶のパターンを浮かび上がらせることにある。自己回帰型モデルに対する攻撃が、固定された一つの予測順序から得られる単一の信号に依存せざるを得ないのに対し、SAMAは独立した多数のマスク構成を通じてモデルを「尋問」することができる。これにより、特定のトークン間の関係性が記憶されている箇所を特定できる確率が飛躍的に高まる。 具体的にSAMAは、以下の3つの主要な要素で構成されている。第一に、トークンのサブセットをランダムにサンプリングして集計する「頑健なサブセット集計」である。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related