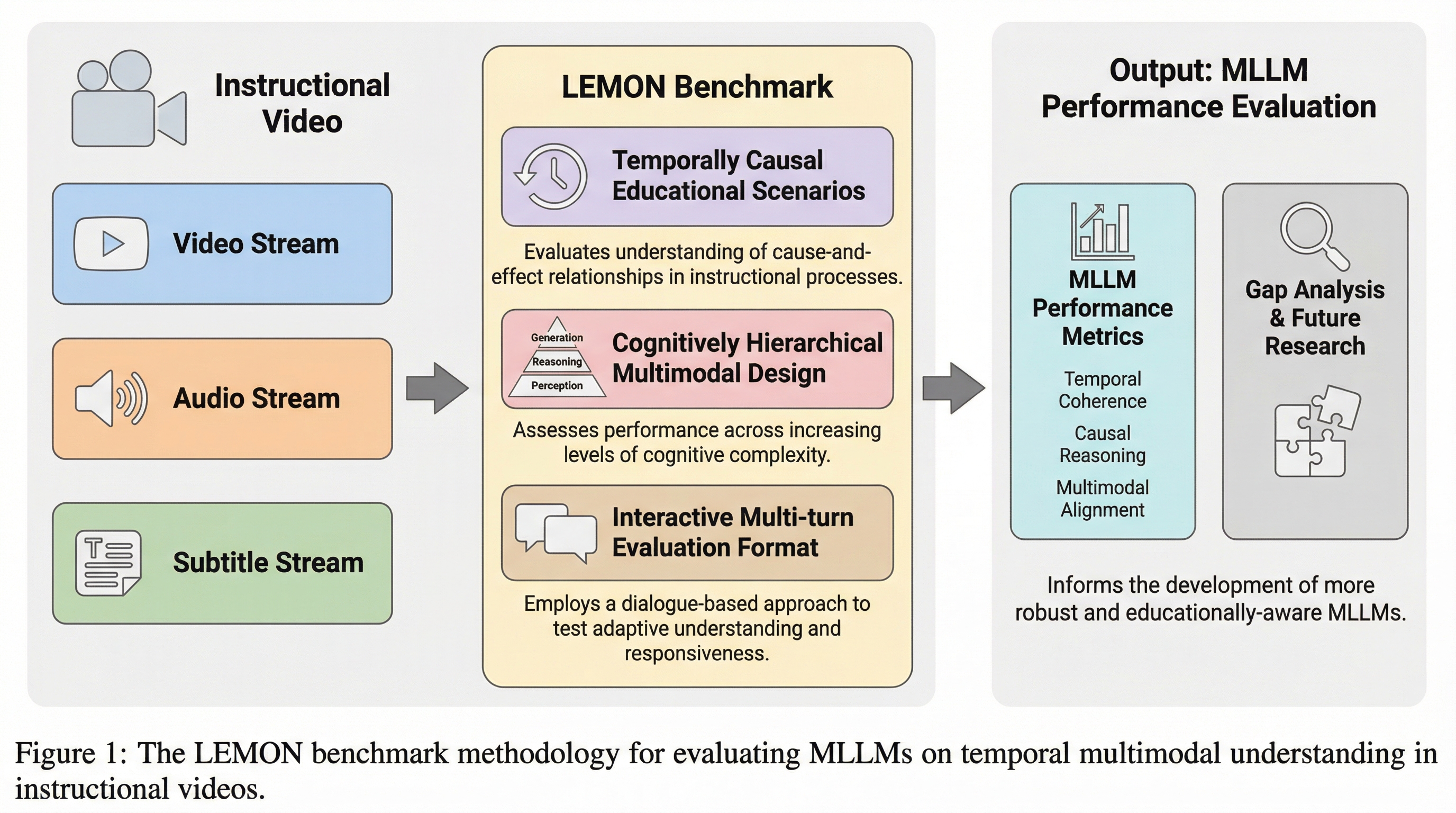
LEMON:MLLMは教育ビデオにおける時間的なマルチモーダル理解をどれほどうまく行えるか?
教育ビデオにおける時間的なマルチモーダル理解を精密に評価するため、数学や人工知能などのSTEM分野の講義を対象とした新しいベンチマーク「LEMON」が提案されました。このデータセットは、5つの学問分野と29のコースから収集された2,277のビデオセグメントと、4,181の高品質な問題ペアで構成されており、視覚、音声、テキストの3つのモダリティが密接に連携した高度な推論を要求します。実験の結果、GPT-5やQwen3-Omniといった最新のマルチモーダル大規模言語モデルであっても、時間的な推論や教育的な意図の予測において大きな課題があることが明らかになり、実世界での複雑なコンテンツ理解能力には依然として大きな乖離があることが示されました。