ベトナム語・バナ語翻訳のための文指向データ拡張とTransformerベースのアーキテクチャの活用
ベトナムの少数民族であるバナ族の言語を保護し、デジタル化を促進するため、限られた学習データでも高精度な翻訳を可能にするニューラル機械翻訳(NMT)技術が開発されました。 本研究では、既存の並列コーパスのみを活用し、複雑な前処理や追加データを必要としない「マルチタスク学習データ拡張(MTL DA)」と「文境界拡張」という2つの柔軟な手法を提案しています。 これらの手法は、バナ語特有の複雑な語彙構造やベトナム語との文法的な差異に起因する誤訳を大幅に改善し、文化遺産の継承と世代間コミュニケーションの活性化に大きく貢献する実用的な成果を示しました。
TL;DR(結論)
ベトナムの少数民族であるバナ族の言語を保護し、デジタル化を促進するため、限られた学習データでも高精度な翻訳を可能にするニューラル機械翻訳(NMT)技術が開発されました。 本研究では、既存の並列コーパスのみを活用し、複雑な前処理や追加データを必要としない「マルチタスク学習データ拡張(MTL DA)」と「文境界拡張」という2つの柔軟な手法を提案しています。 これらの手法は、バナ語特有の複雑な語彙構造やベトナム語との文法的な差異に起因する誤訳を大幅に改善し、文化遺産の継承と世代間コミュニケーションの活性化に大きく貢献する実用的な成果を示しました。
なぜこの問題か
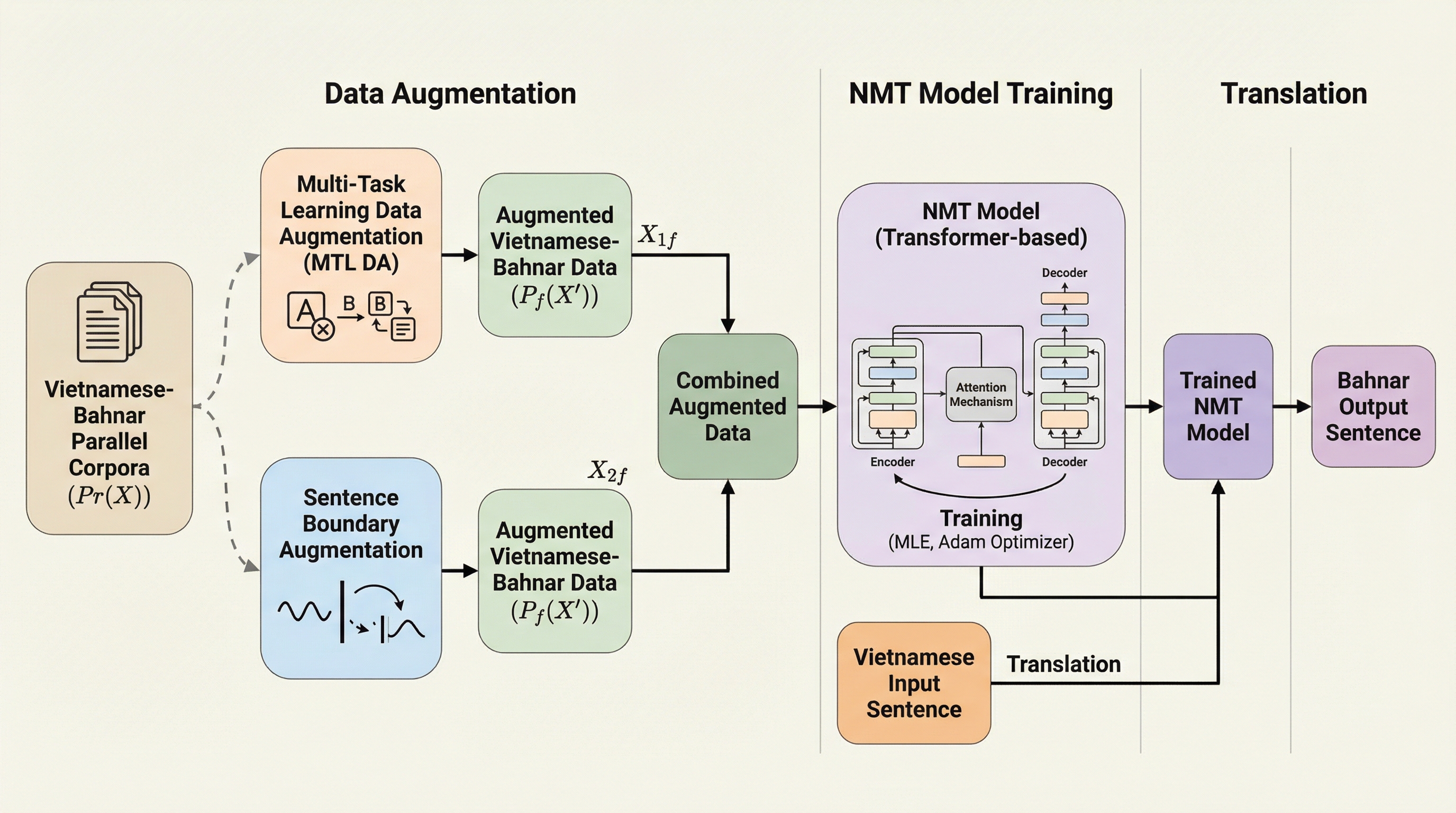
バナ族(Ba-Na)はベトナムの多様な民族構成において独自の地位を占める少数民族であり、彼らが受け継いできたバナ語は極めて高い文化的・歴史的価値を有しています。ベトナム政府は現在、バナ族が社会、文化、教育、科学の各分野に完全に参加できるよう積極的に取り組んでおり、その一環として重要な文書をバナ語に翻訳するプロジェクトを推進しています。しかし、バナ語は「低リソース言語」に分類されており、機械翻訳システムを構築するために必要な大規模な並列データが圧倒的に不足しているという深刻な課題があります。従来の統計的機械翻訳(SMT)は、単語の整列やフレーズをコーパスから直接学習するデータ駆動型のアプローチでしたが、長距離の単語依存関係をモデル化できないという限界がありました。近年のディープラーニングの台頭により、ニューラル機械翻訳(NMT)が主流となりましたが、NMTは学習データの量にその性能が大きく依存します。バナ語のようなリソースの少ない言語では、翻訳の品質が著しく低下し、正確性や流暢さが損なわれる傾向があります。 また、バナ語は言語学的にも非常に複雑な構造を持っています。…
核心:何を提案したのか
本研究では、ベトナム語からバナ語へのドメイン固有の翻訳タスクにおいて、最先端のNMT技術と2つの革新的なデータ拡張(DA)戦略を導入しました。提案された手法の最大の特徴は、追加の並列コーパスを取得したり、複雑な前処理ステップを踏んだり、あるいは追加のシステムを訓練したりする必要がないという点にあります。これにより、計算リソースやデータが限られている環境でも、効率的に翻訳精度を向上させることが可能になります。提案された1つ目の手法は「マルチタスク学習データ拡張(MTL DA)」です。これは、自然言語処理のためのシンプルなデータ拡張フレームワークであるEDA(Easy Data Augmentation)の概念をベースにしつつ、マルチタスク学習の知見を取り入れたものです。この手法は、エンコーダーの機能を強化することを目的として、人工的なターゲット文を生成します。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related