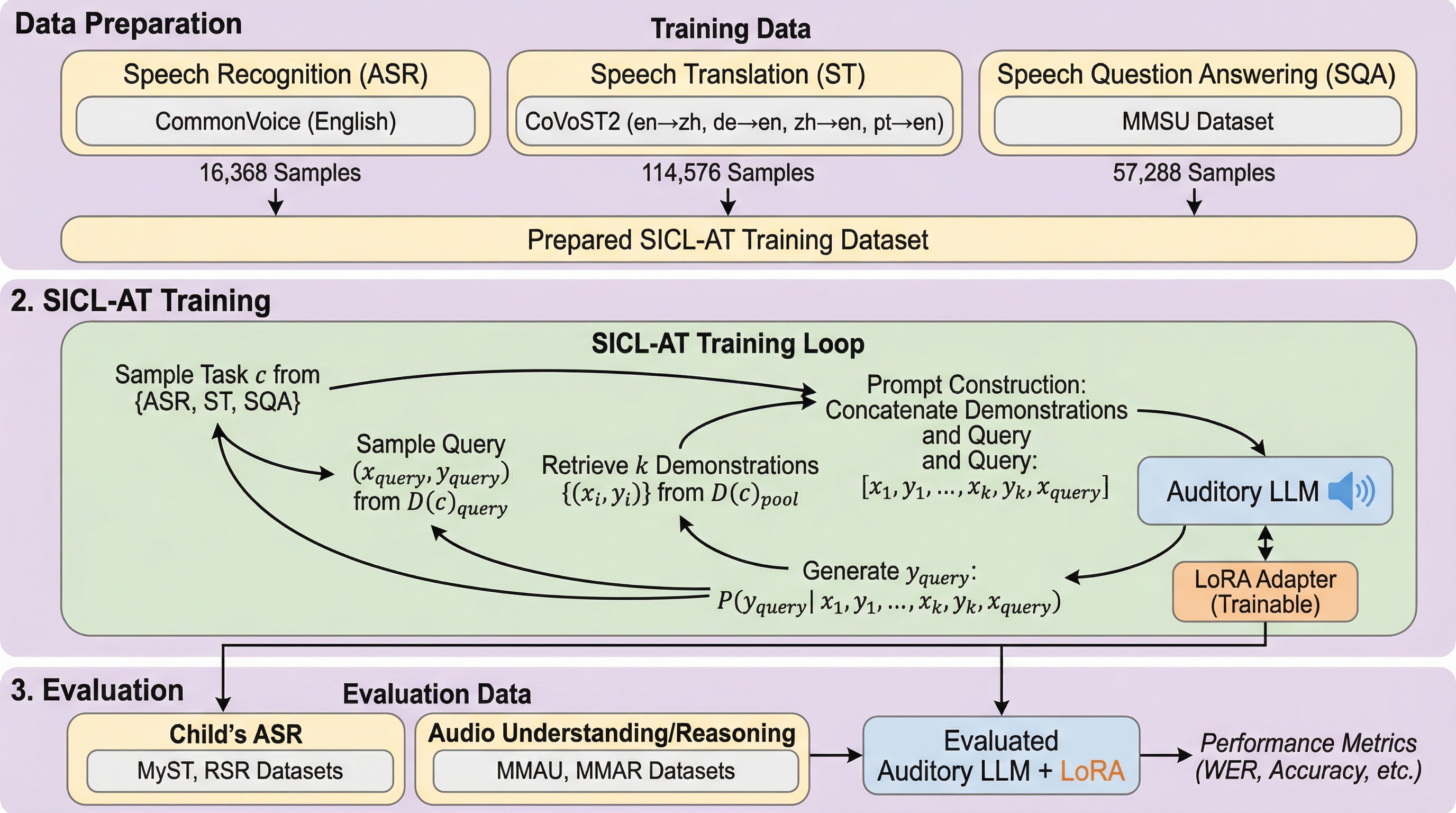
SICL-AT:聴覚LLMを低リソースタスクに適応させる新手法
聴覚大規模言語モデル(Auditory LLM)は、子供の音声認識や複雑な音声推論といったデータが乏しい低リソースタスクにおいて、直接的な微調整を行うと過学習や分布の不一致により性能が不安定になるという課題を抱えています。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
聴覚大規模言語モデル(Auditory LLM)は、子供の音声認識や複雑な音声推論といったデータが乏しい低リソースタスクにおいて、直接的な微調整を行うと過学習や分布の不一致により性能が不安定になるという課題を抱えています。
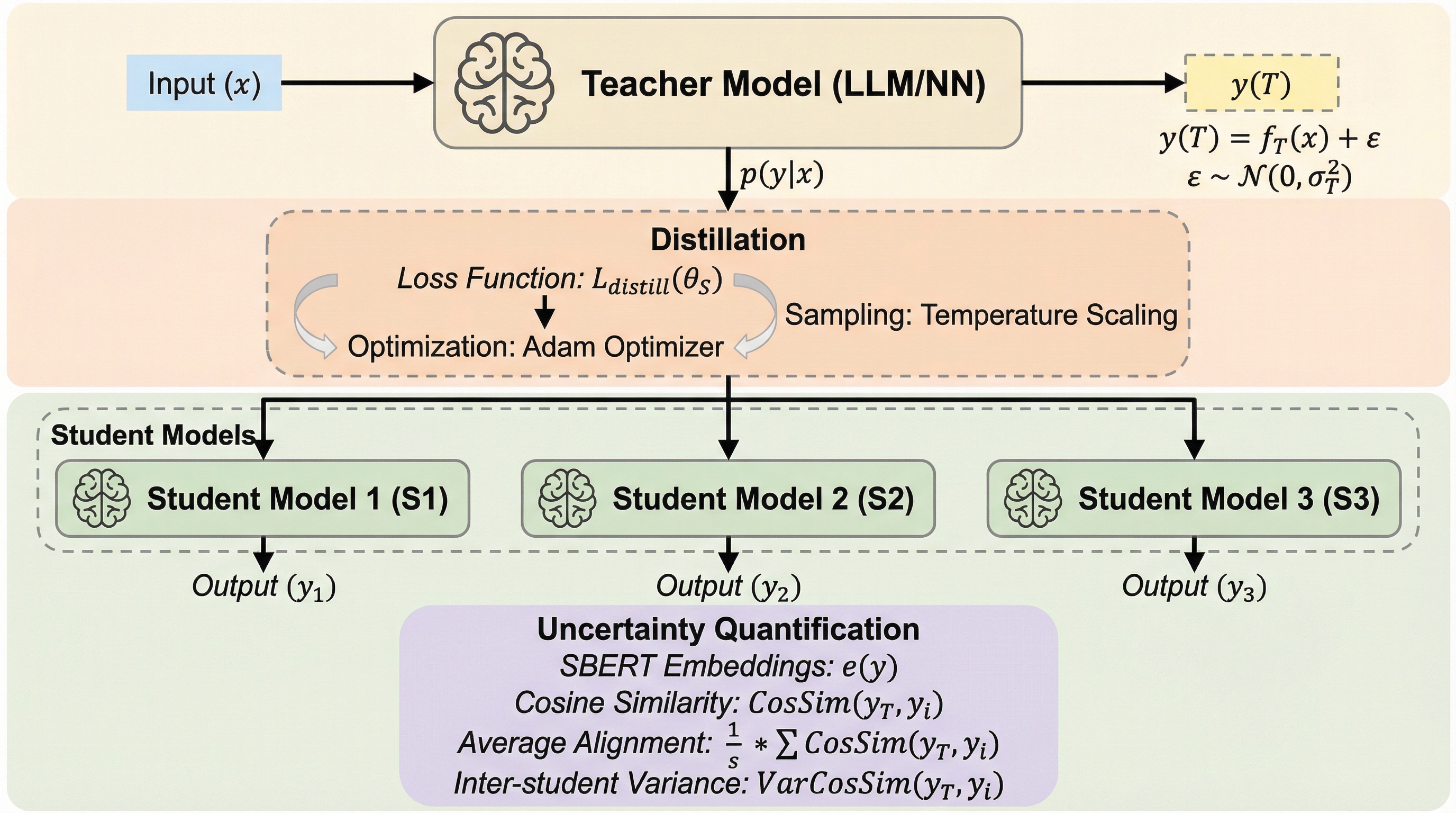
知識蒸留は教師モデルの挙動を生徒モデルへ継承させる手法だが、教師の出力や生徒の初期化、推論時のサンプリングといった確率的な要素が不確実性を生み出す。本研究では、標準的な蒸留が「生徒個体間のばらつき(inter-student uncertainty)」を放置する一方で、「生徒内部の予測の多様性(intra-student uncertainty)」を過度に抑制してしまうというミスマッチを明らかにした。 この不確実性の歪みを解消するために、複数の教師出力を平均化してノイズを低減する手法と、分散に基づいた重み付けを行う「分散を考慮した蒸留(variance-aware distillation)」という2つの戦略を提案した。線形回帰、ニューラルネットワーク、大規模言語モデル(LLM)を用いた検証により、提案手法が教師モデルの不確実性をより正確に反映し、モデルの安定性を向上させることを証明した。 実験の結果、提案手法はLLMにおけるハルシネーション(幻覚)を抑制し、教師モデルが持つ本来の表現力や多様性を生徒モデルに正しく継承させる効果があることが確認された。これにより、知識蒸留を単なる精度の模倣ではなく、不確実性の適切な変換プロセスとして再定義し、医療や法律、金融といった安全性が重視される分野においても信頼性の高い小型モデルの構築が可能となる。
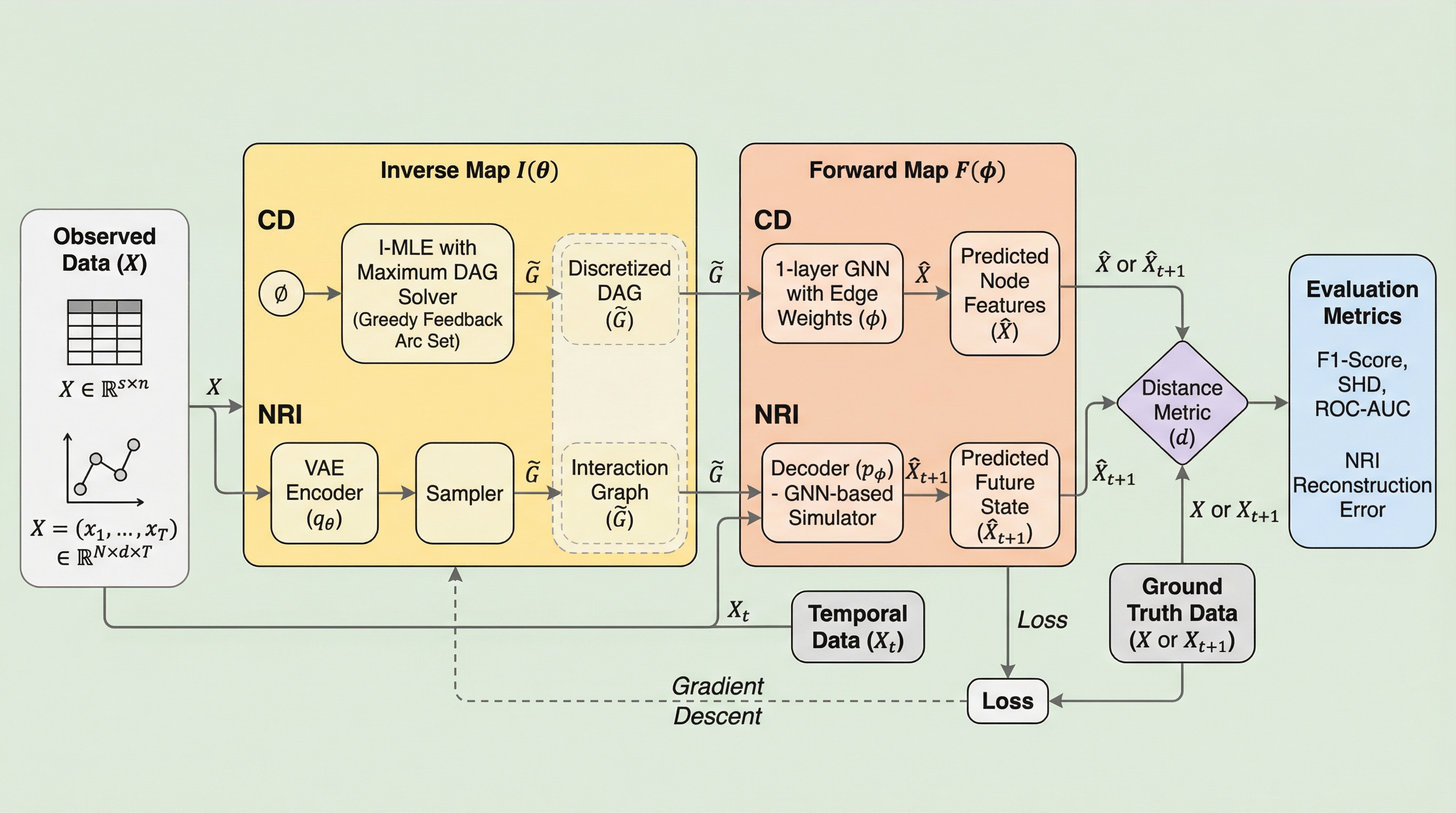
GraIPは、構造発見や因果探索、組み合わせ最適化といった多様なグラフ学習タスクを「逆問題」として統一的に定義し、観測データから潜在的なグラフ構造を復元することを目指す新しい概念フレームワークである。
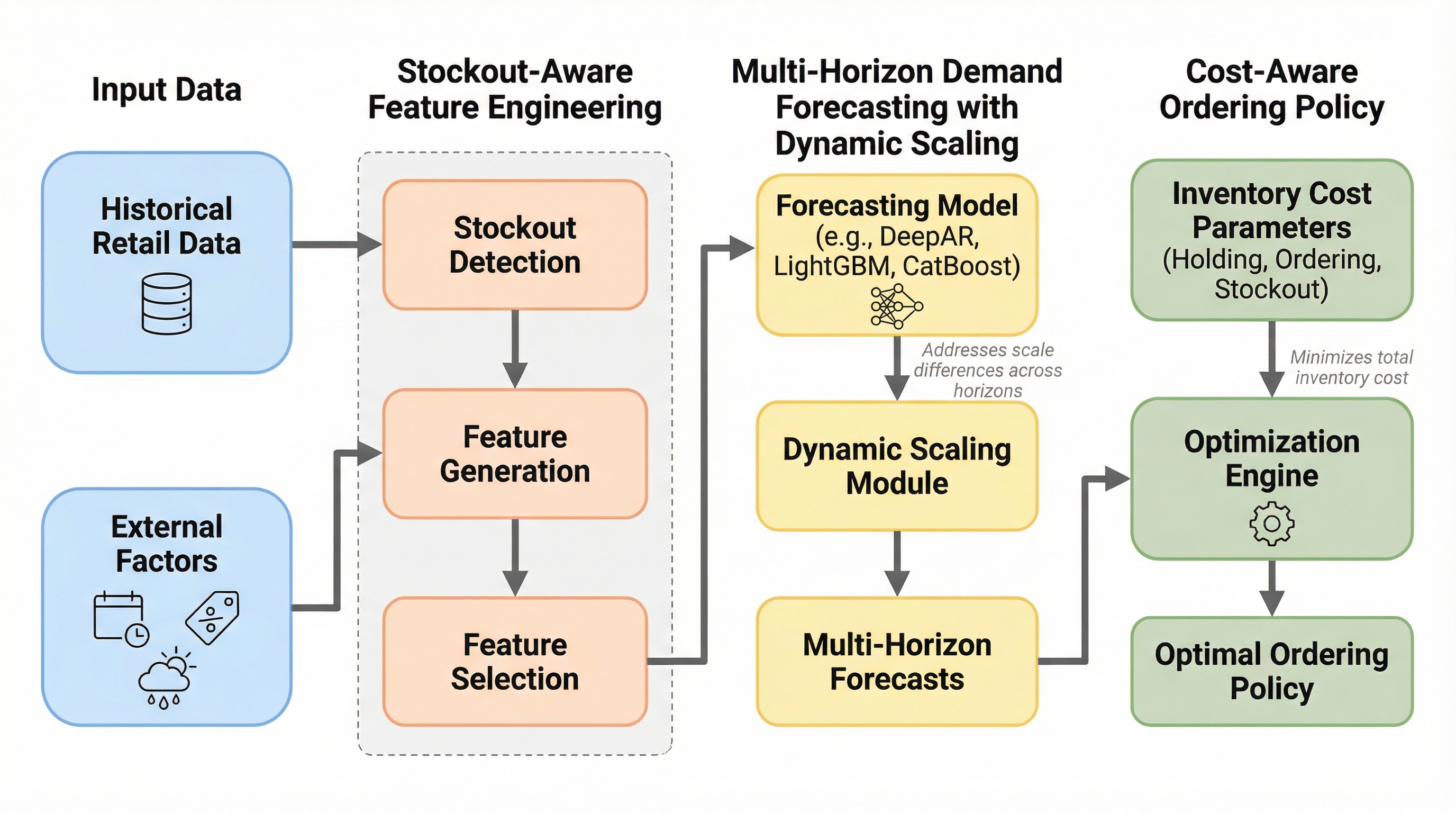
VN2在庫計画チャレンジで優勝した本手法は、需要予測と発注決定を分離した2段階のパイプラインを採用し、在庫切れによる需要の偏りを考慮した特徴量エンジニアリングと動的スケーリングを組み合わせています。
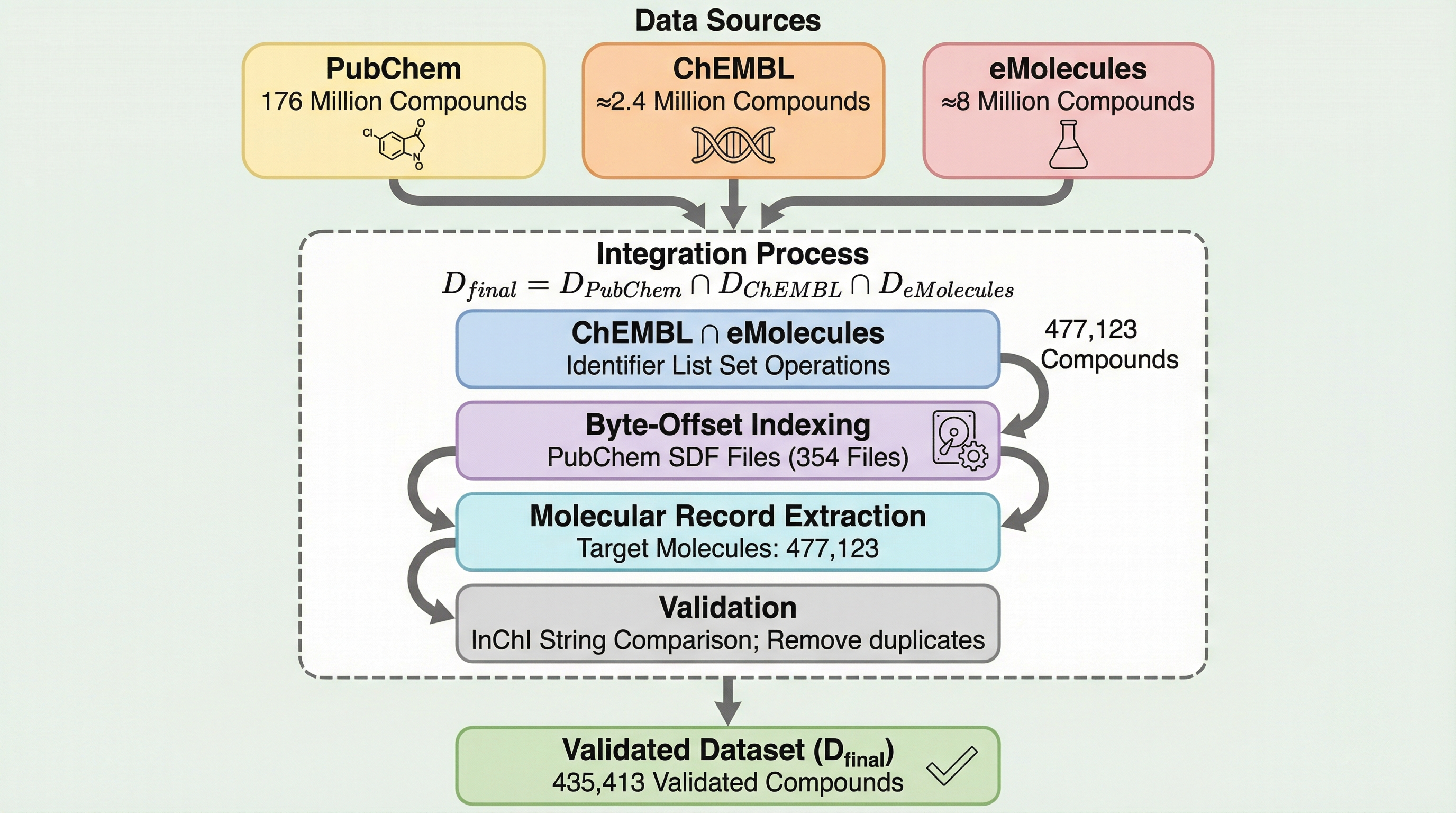
現代の創薬研究に不可欠な大規模化学データベースの統合において、従来の総当たり検索では100日以上を要していた計算時間を、バイトオフセットを用いたインデックス・アーキテクチャの導入によりわずか3.2時間へと劇的に短縮しました。
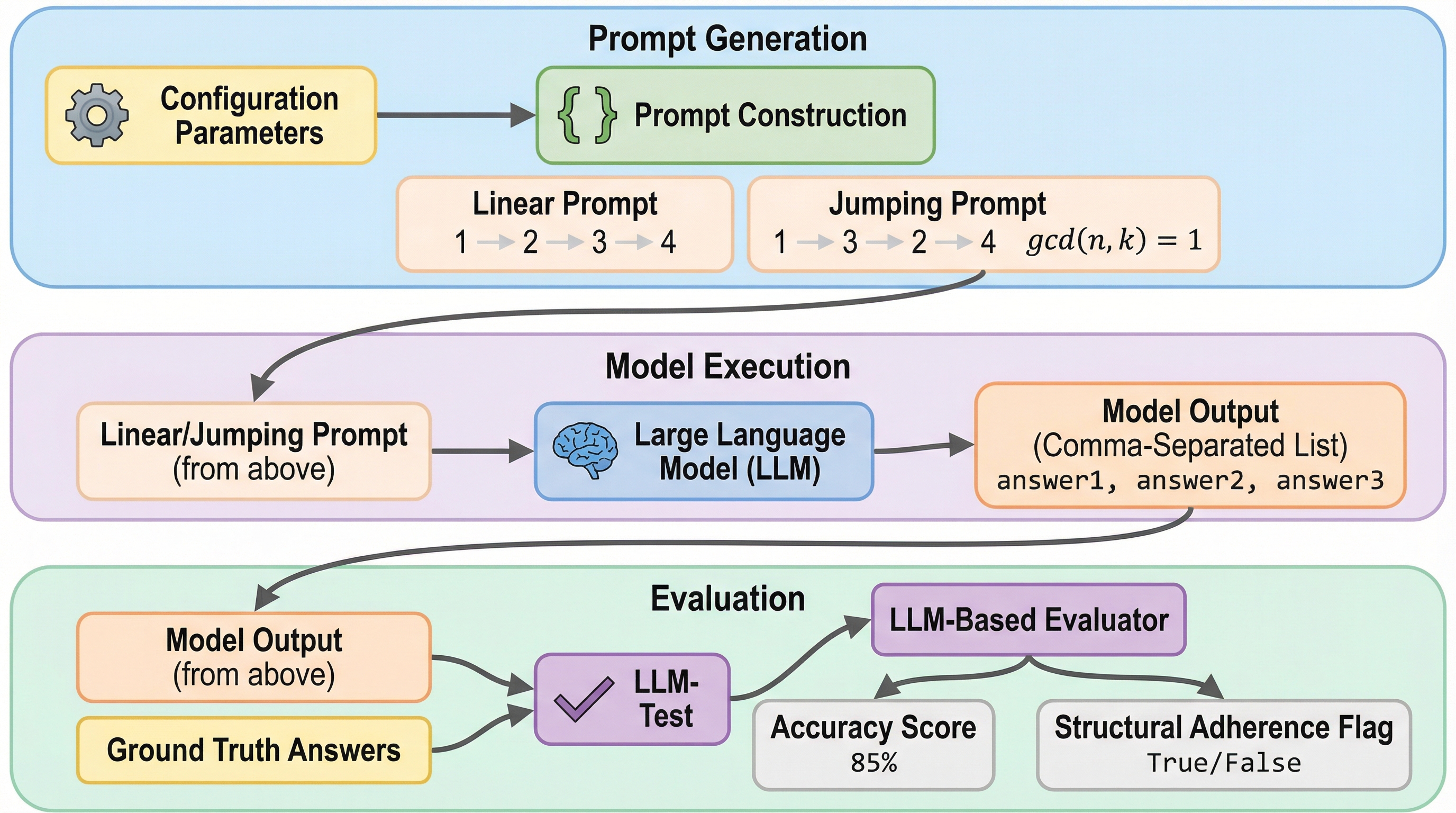
大規模言語モデル(LLM)が複雑な指示に従う能力を、タスクの難易度や内容から構造的な配置を切り離して精密に評価するための新しいベンチマークフレームワーク「RIFT」が提案されました。 テレビ番組のクイズを基にしたデータセットを用い、順番通りに回答する「線形プロンプト」と、指示に従って非連続な順序で回答を求める「ジャンププロンプト」の二つの構造でモデルの性能を比較検証しています。 最新の高性能モデルであっても、非連続な指示条件下では正解率が最大で72%も低下し、モデルが指示を論理的な推論スキルとしてではなく、単なる逐次的なパターンの継続として処理しているという構造的な脆弱性が明らかになりました。
本研究は、隠れ状態を持つシステムの動態を学習するため、予測状態表現(PSR)とテンソル分解の手法を統合し、一部の行動がフルランクであれば離散的な部分観測マルコフ決定過程(POMDP)のパラメータを推定できる新しい枠組みを提案している。
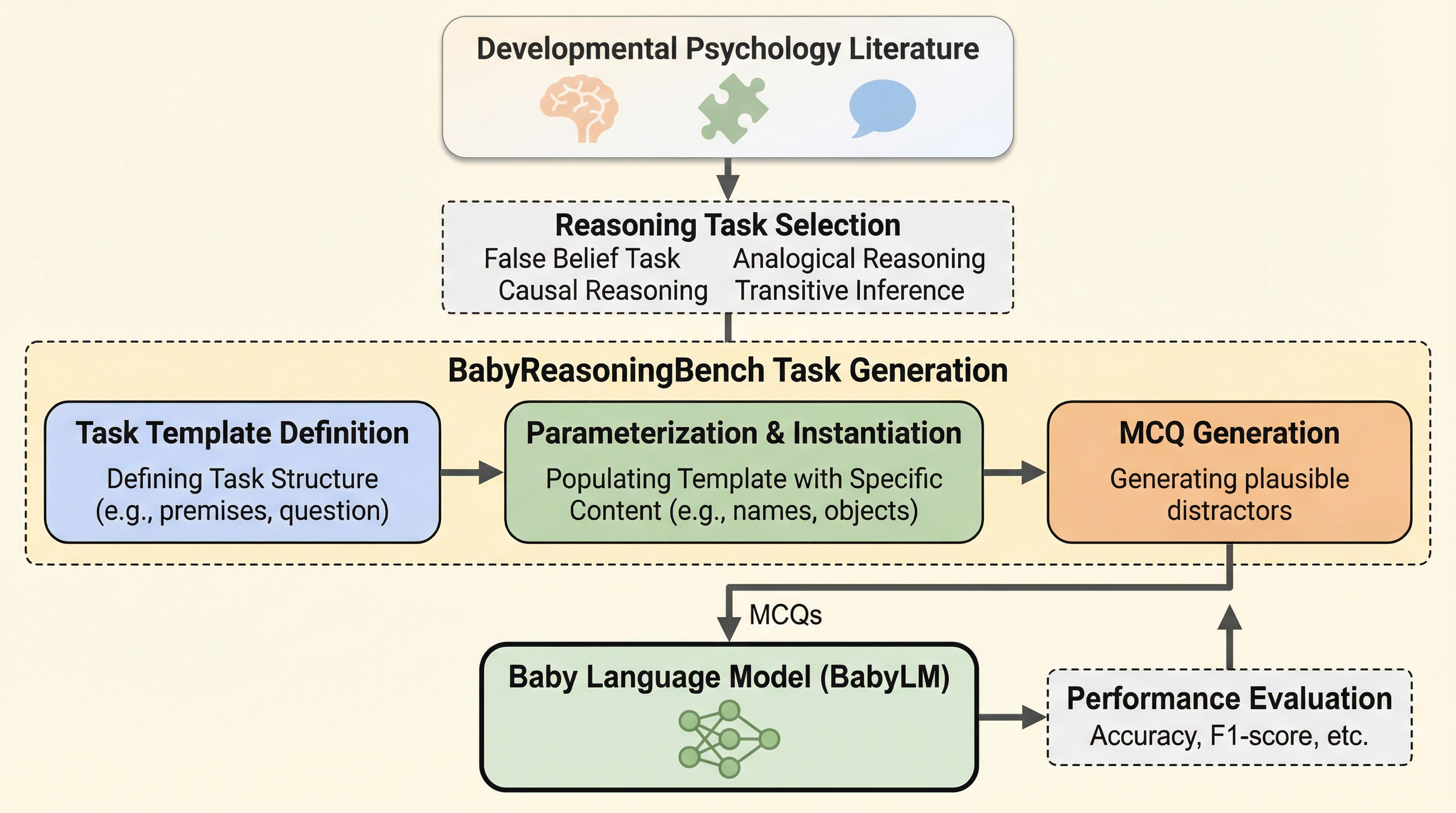
従来の言語モデル評価は成人の知識や複雑な指示への追従を前提としていましたが、本研究では乳幼児の認知発達の軌跡に着想を得た新しい評価指標「BABYREASONINGBENCH」を提案しました。 このベンチマークは、心の理論、類推、因果推論、基本的な推論プリミティブの4つの領域にわたる19のタスクで構成されており、子供向けの発話データなどで学習された「赤ちゃん言語モデル」の能力を精密に測定します。 実験の結果、学習データの規模を拡大することで物理的・因果的な推論能力は向上するものの、他者の信念の理解や語用論的な判断を要する課題は依然として困難であり、能力の出現には不均一なパターンがあることが明らかになりました。
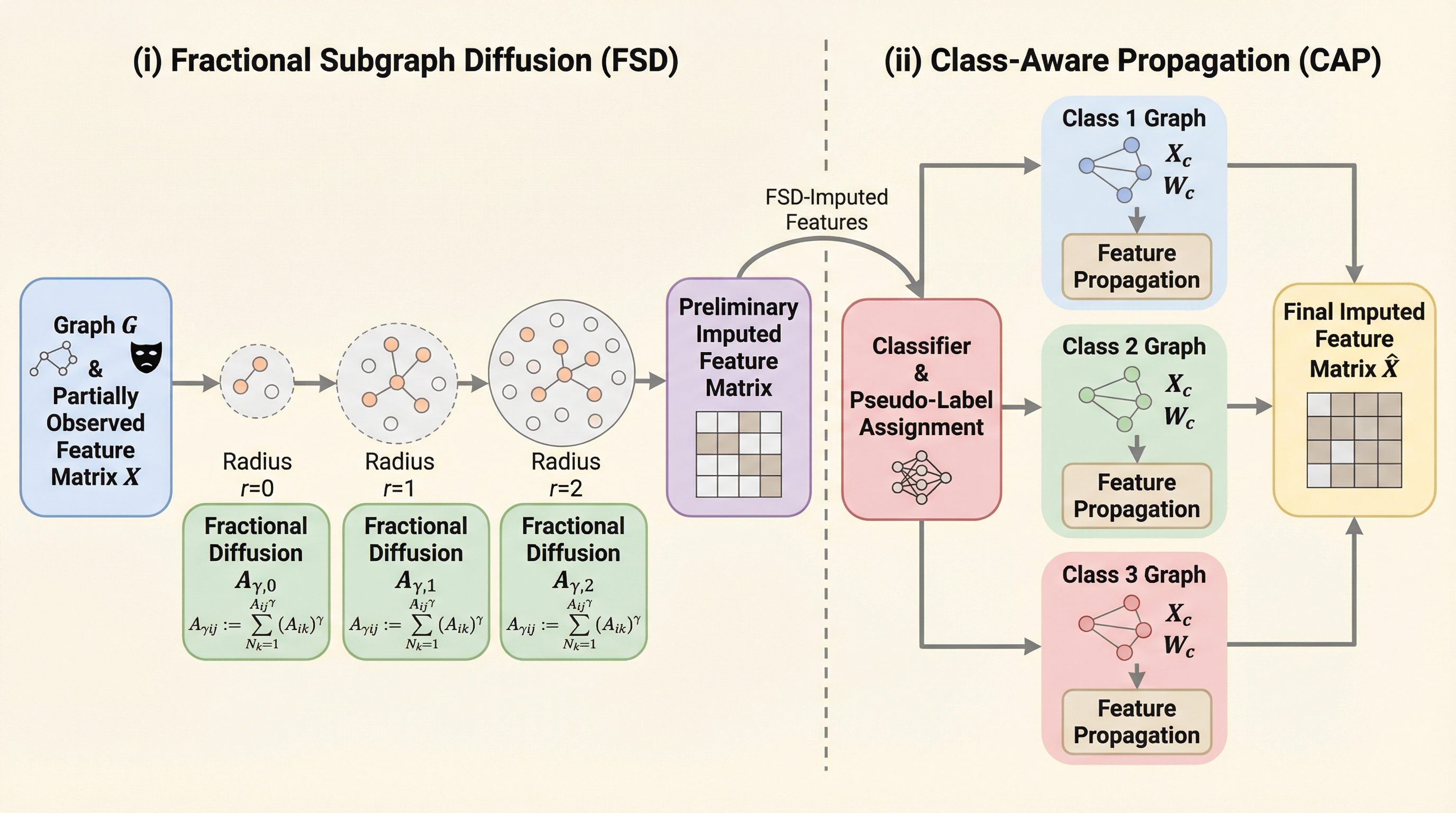
FSD-CAPは、ノード特徴量の99.5%が欠損しているという極限状態のグラフデータにおいて、全データが揃っている状態に匹敵する精度で特徴量を復元・補完する新しい学習フレームワークである。 局所的なグラフ構造に応じて情報の伝播強度を調整する「分数拡散オペレータ」と、観測済みノードから段階的に探索範囲を広げる「部分的サブグラフ拡張」を組み合わせることで、広域拡散による誤差の蓄積を抑えつつ、安定した特徴量推定を可能にしている。 さらに、推定された特徴量から得られる疑似ラベルと近傍のラベル一貫性(エントロピー)を利用した「クラス認識型伝播」を導入することで、クラス内の整合性を高め、ノード分類やリンク予測といった下流タスクにおいて既存手法を圧倒する性能を達成した。
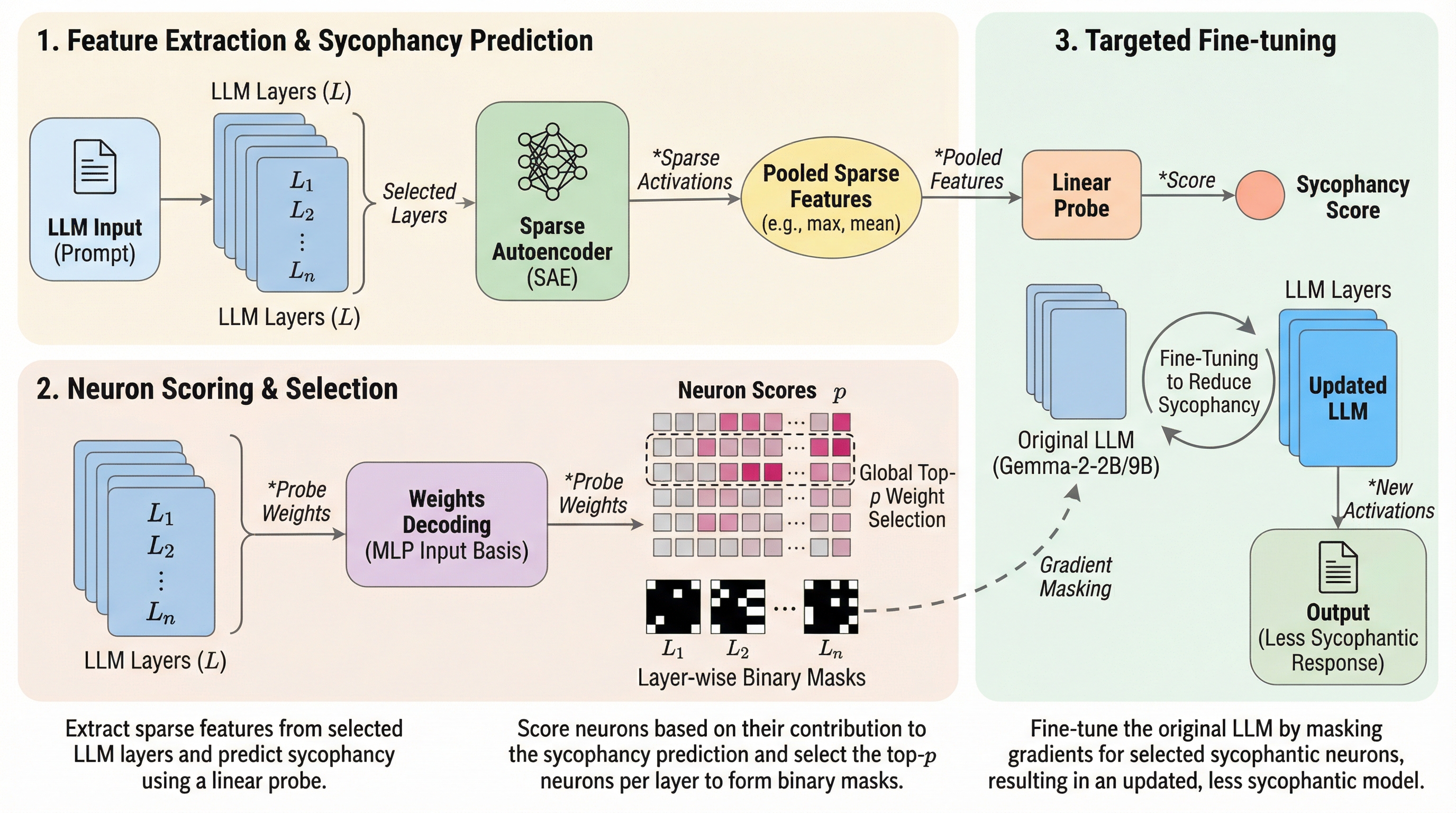
大規模言語モデルがユーザーの誤った意見や好みに不当に同調してしまう「追従性(Sycophancy)」という深刻な問題に対し、Sparse Autoencoders(SAE)と線形プローブを組み合わせることで、その挙動に直接的な責任を持つわずか約3%の特定のMLPニューロンを精密に特定し、外科的に修正する新しいアライメント手法を提案した。 Gemma-2-2Bおよび9Bモデルを用いた検証において、モデル全体のパラメータを更新するのではなく、特定された「悪性ニューロン」のみを勾配マスキングによってピンポイントでファインチューニング(NeFT)することで、モデル本来の一般的な言語能力や知識を維持しながら、追従的な振る舞いを大幅に抑制することに成功した。 Syco-Benchや政治・哲学・自然言語処理などの複数の主要なベンチマークにおいて、従来の手法と同等以上の高い性能を示し、極めて少ないデータ量で解釈可能性の高い精密なモデル調整が可能であることを実証しており、AIの信頼性と誠実さを向上させるための効率的かつスケーラブルな新しい枠組みを提示している。