知識蒸留において不確実性はどのように伝播されるのか?
知識蒸留は教師モデルの挙動を生徒モデルへ継承させる手法だが、教師の出力や生徒の初期化、推論時のサンプリングといった確率的な要素が不確実性を生み出す。本研究では、標準的な蒸留が「生徒個体間のばらつき(inter-student uncertainty)」を放置する一方で、「生徒内部の予測の多様性(intra-student uncertainty)」を過度に抑制してしまうというミスマッチを明らかにした。 この不確実性の歪みを解消するために、複数の教師出力を平均化してノイズを低減する手法と、分散に基づいた重み付けを行う「分散を考慮した蒸留(variance-aware distillation)」という2つの戦略を提案した。線形回帰、ニューラルネットワーク、大規模言語モデル(LLM)を用いた検証により、提案手法が教師モデルの不確実性をより正確に反映し、モデルの安定性を向上させることを証明した。 実験の結果、提案手法はLLMにおけるハルシネーション(幻覚)を抑制し、教師モデルが持つ本来の表現力や多様性を生徒モデルに正しく継承させる効果があることが確認された。これにより、知識蒸留を単なる精度の模倣ではなく、不確実性の適切な変換プロセスとして再定義し、医療や法律、金融といった安全性が重視される分野においても信頼性の高い小型モデルの構築が可能となる。
TL;DR(結論)
知識蒸留は教師モデルの挙動を生徒モデルへ継承させる手法だが、教師の出力や生徒の初期化、推論時のサンプリングといった確率的な要素が不確実性を生み出す。本研究では、標準的な蒸留が「生徒個体間のばらつき(inter-student uncertainty)」を放置する一方で、「生徒内部の予測の多様性(intra-student uncertainty)」を過度に抑制してしまうというミスマッチを明らかにした。 この不確実性の歪みを解消するために、複数の教師出力を平均化してノイズを低減する手法と、分散に基づいた重み付けを行う「分散を考慮した蒸留(variance-aware distillation)」という2つの戦略を提案した。線形回帰、ニューラルネットワーク、大規模言語モデル(LLM)を用いた検証により、提案手法が教師モデルの不確実性をより正確に反映し、モデルの安定性を向上させることを証明した。 実験の結果、提案手法はLLMにおけるハルシネーション(幻覚)を抑制し、教師モデルが持つ本来の表現力や多様性を生徒モデルに正しく継承させる効果があることが確認された。これにより、知識蒸留を単なる精度の模倣ではなく、不確実性の適切な変換プロセスとして再定義し、医療や法律、金融といった安全性が重視される分野においても信頼性の高い小型モデルの構築が可能となる。
なぜこの問題か
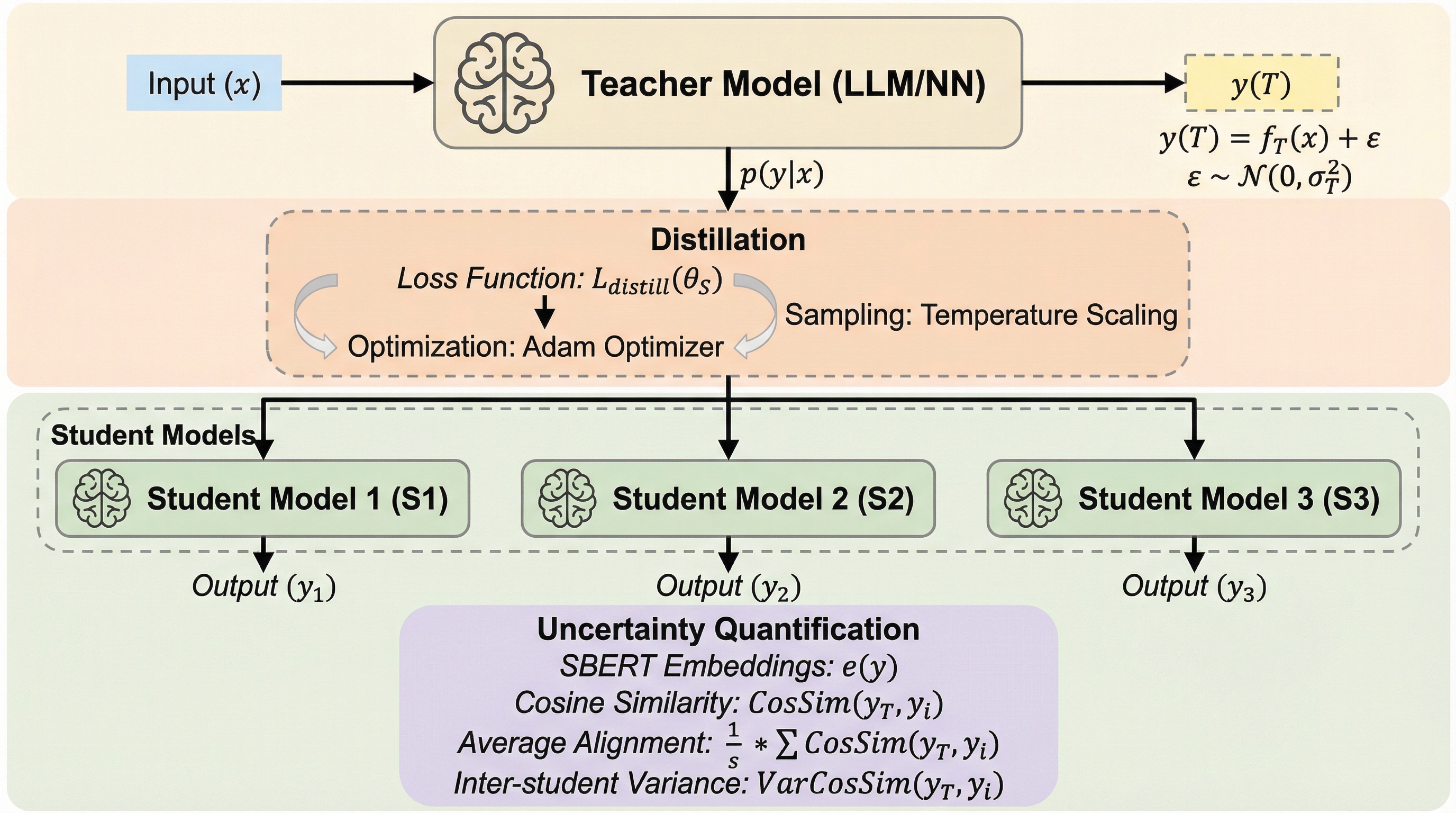
知識蒸留は、高い能力を持つ教師モデルの挙動を、より効率的で軽量な生徒モデルへと転移させるための極めて重要な技術である。この技術はモデルの圧縮やドメイン適応、さらには金融、医療、法律といった専門分野における知識の統合など、幅広い領域で実用化されている。これまでの研究の多くは、生徒モデルがいかに教師モデルの精度を維持しつつ計算資源を節約できるかという点に焦点を当ててきた。しかし、蒸留プロセスそのものが持つ「確率的な性質」が、学習される内容をどのように歪めてしまうかについては、これまで十分に解明されていなかった。 蒸留のパイプラインには、複数の不確実性の源泉が存在する。まず、教師モデルの出力は、サンプリングや温度設定、あるいは入力に含まれる曖昧さによって変動する。次に、生徒モデルの学習はランダムな初期化や非凸な最適化のダイナミクスに依存し、さらに推論時にも確率的な挙動を示すことがある。このように、蒸留は本質的に不確実性を伴うプロセスであるにもかかわらず、これらを単一の点推定として処理してしまうと、教師モデルが持っていた豊かな表現力や不確実性の情報が失われるリスクがある。…
核心:何を提案したのか
本研究の核心は、知識蒸留を単なる挙動の模倣ではなく「不確実性の変換プロセス」として再定義し、その伝播メカニズムを定式化した点にある。具体的には、不確実性を2つの側面から明確に区別して定義した。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related