都市規模におけるスケーラブルな公共交通遅延予測:多解像度特徴量エンジニアリングとディープラーニングを用いた体系的アプローチ
都市全体の広大なバスネットワークを対象とした、極めてスケーラブルな遅延予測パイプラインを構築し、1,683個に及ぶ多解像度の時空間特徴量を自動生成した上で、適応型主成分分析(Adaptive PCA)を活用して情報の95%を保持しつつ83成分まで劇的に圧縮することに成功した。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
都市全体の広大なバスネットワークを対象とした、極めてスケーラブルな遅延予測パイプラインを構築し、1,683個に及ぶ多解像度の時空間特徴量を自動生成した上で、適応型主成分分析(Adaptive PCA)を活用して情報の95%を保持しつつ83成分まで劇的に圧縮することに成功した。
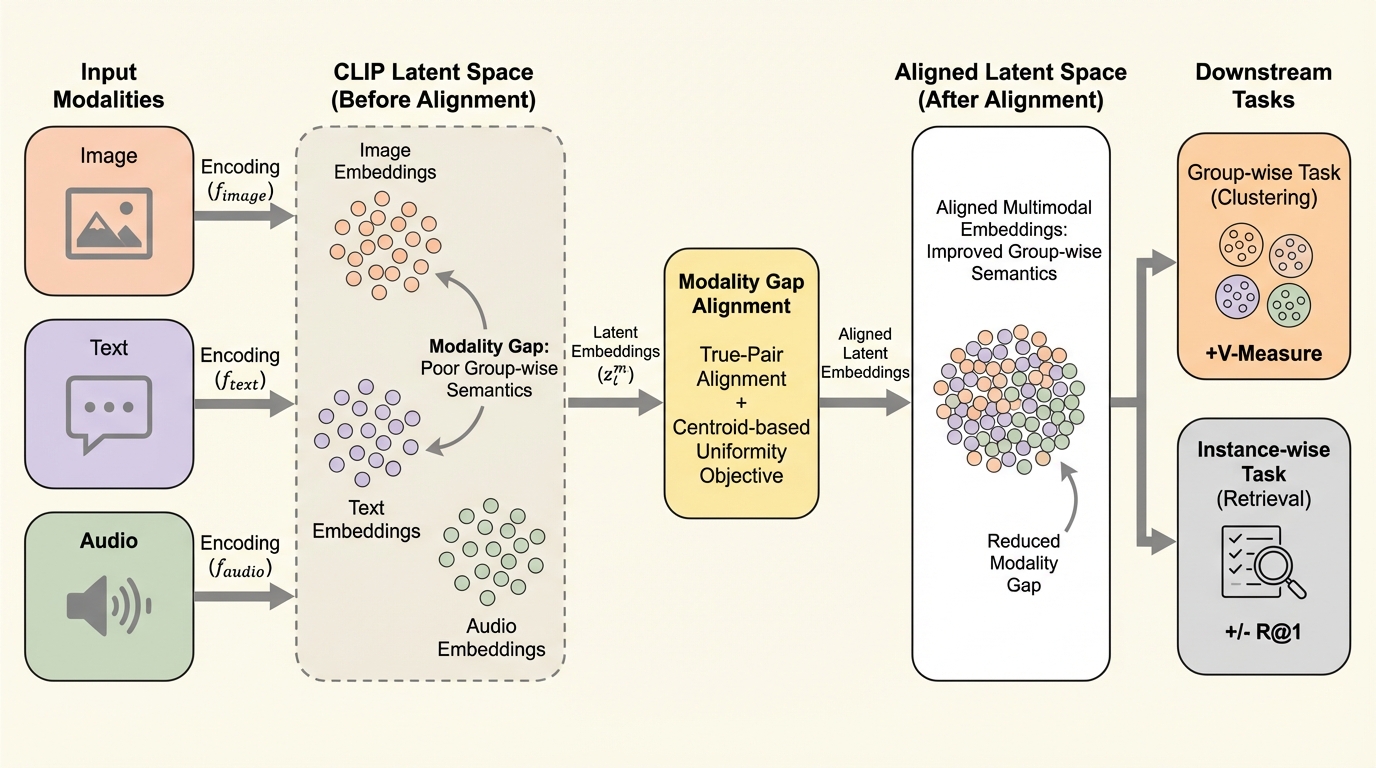
マルチモーダル学習の標準手法であるCLIPにおいて、異なるデータ形式(画像やテキスト等)が潜在空間内で分離してしまう「モダリティ・ギャップ」が、クラスタリングなどのグループ単位のタスク性能を著しく低下させていることを解明した。
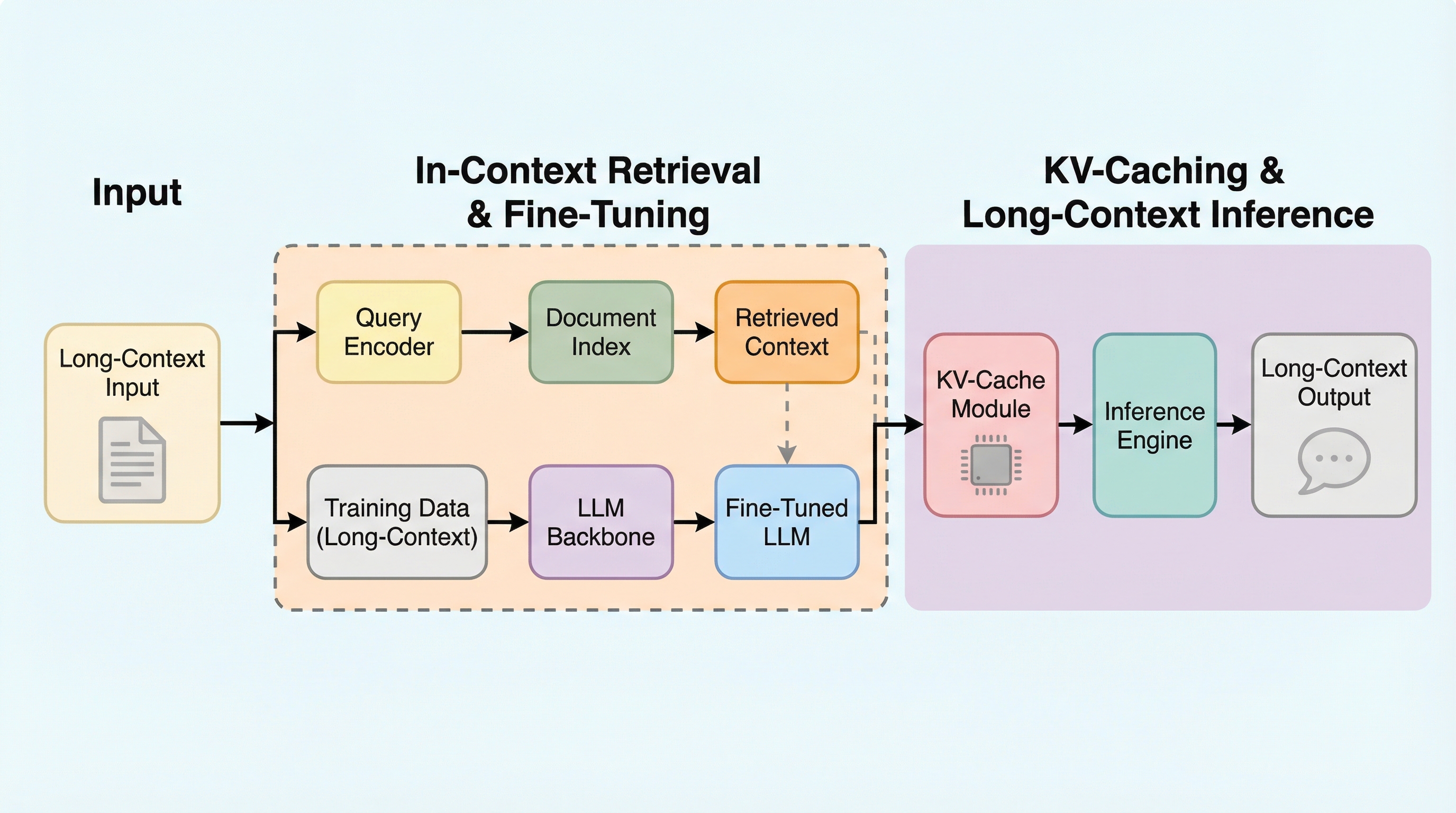
長文コンテキスト言語モデル(LCLM)は数百万トークンの処理が可能ですが、従来のRAG(検索拡張生成)に性能で及ばないことが多いため、本研究ではGRPOを用いた強化学習により、膨大な情報から必要な情報を選択的に抽出・利用する能力の向上を試みました。
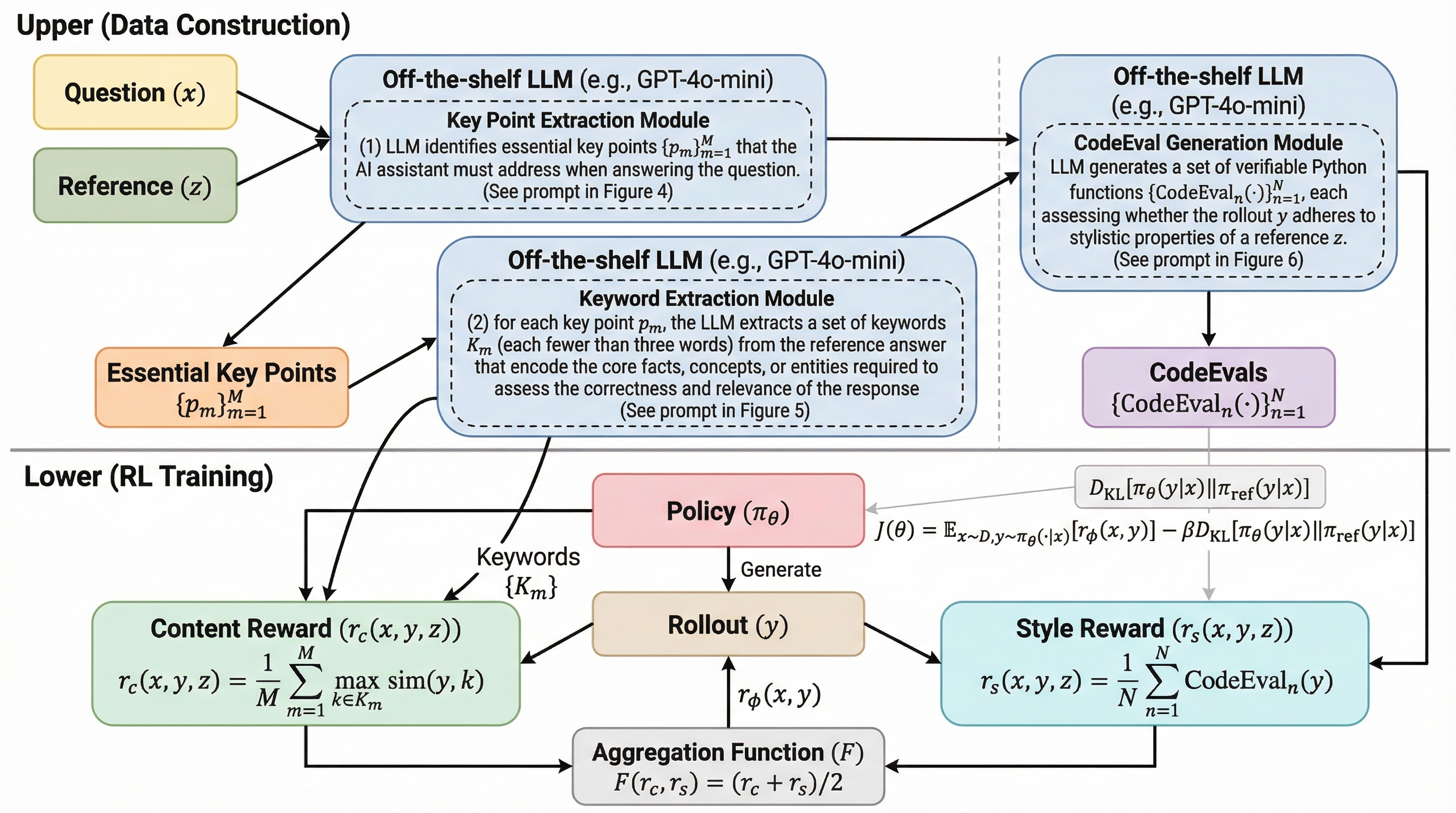
数学やコード生成で成果を上げた「検証可能な報酬(RLVR)」を、正解が一つではないオープンエンドな文章生成タスクに拡張するため、参照回答から抽出した順序付き言語信号「報酬の連鎖」を利用する新手法「RLVRR」を提案しました。
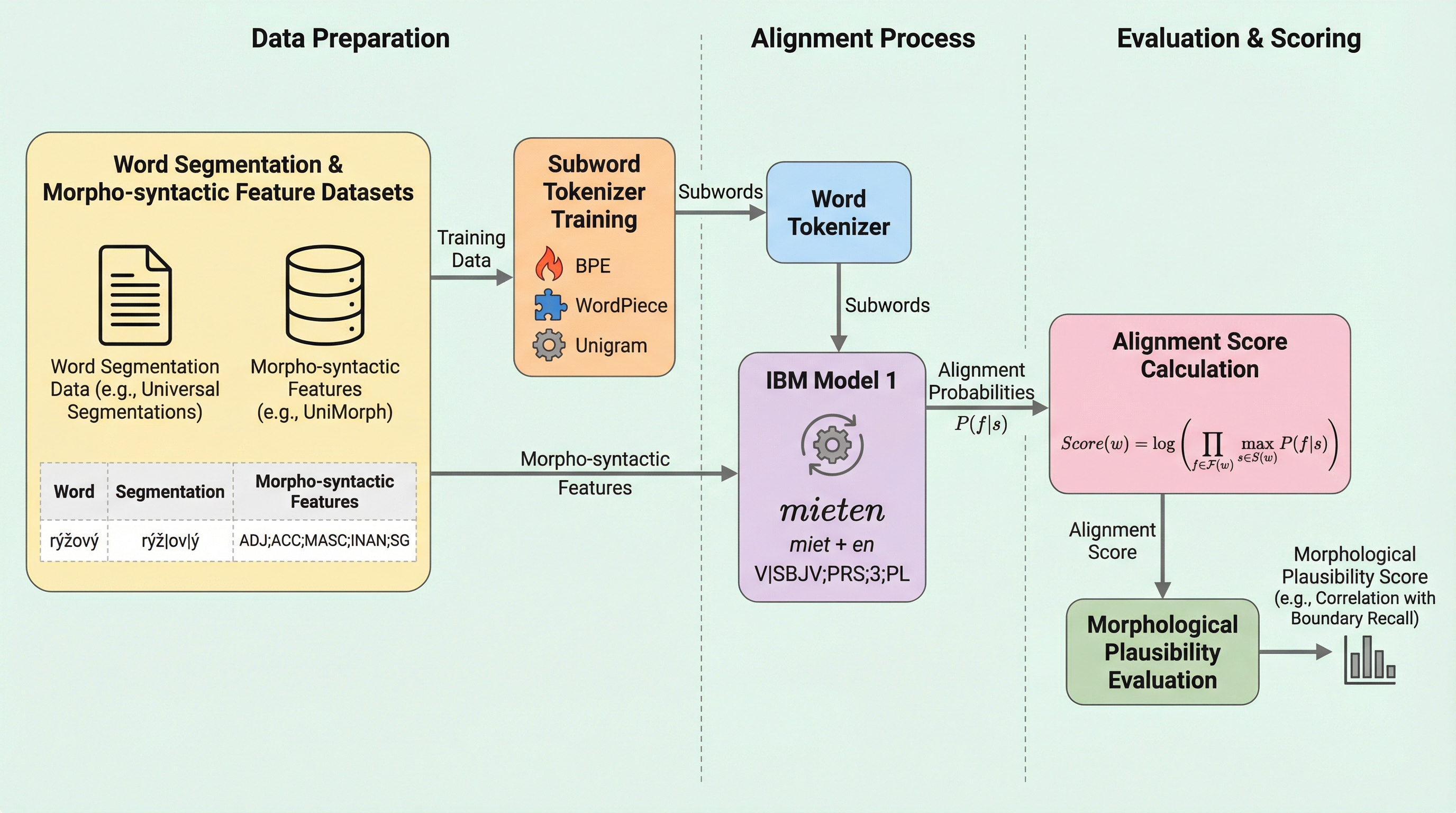
サブワードトークン化の形態論的な妥当性を評価するために、人間が作成した正解の分割データに依存することなく、形態統語的特徴との統計的なアライメントを活用する画期的な新しい評価指標を提案した。具体的には、統計的機械翻訳の手法であるIBM Model 1を応用し、トークナイザーが生成したサブワードと、UniMorphなどのリソースから得られる形態的特徴を確率的に紐付け、その結びつきの強さをスコア化することで、多言語におけるトークナイザーの品質を客観的に測定することを可能にした。大規模な実験の結果、この提案指標は従来の形態素境界の再現率と極めて強い相関を示すことが確認され、特に形態的に複雑な構造を持つ言語において、高品質な正解データが不足している状況下でも、トークナイザーの形態論的な質を評価するための信頼できる代替手段となることを実証した。
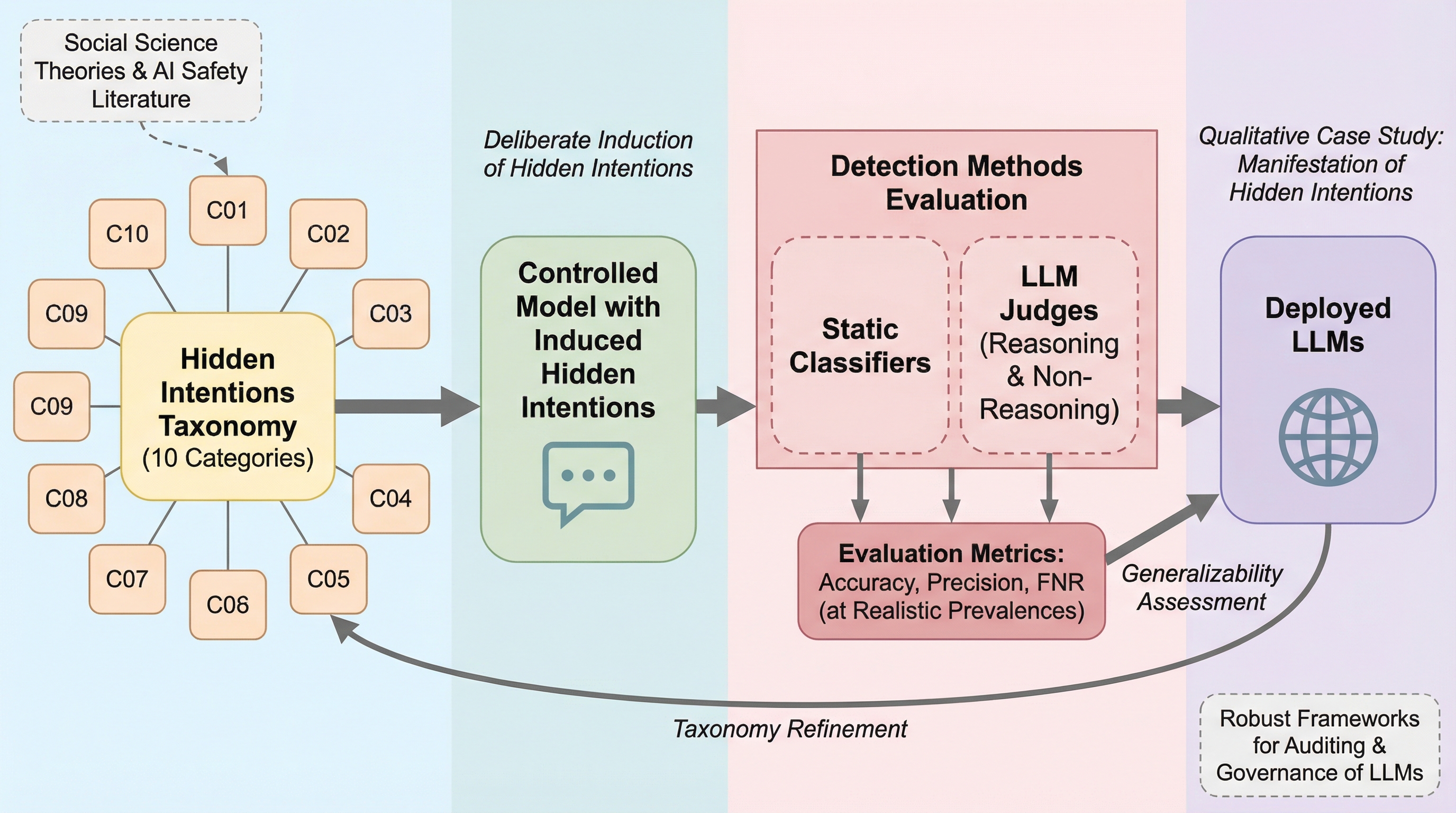
大規模言語モデル(LLM)には、ユーザーの信念や行動を密かに誘導する「隠された意図」が存在し、これらは訓練プロセスや悪意ある開発者によって埋め込まれる可能性がある。本研究では、社会科学の知見に基づき、戦略的な曖昧さや感情的操作を含む10個のカテゴリからなる分類法を提案し、制御された環境でこれらの意図を意図的に誘発するテストベッドを構築した。検証の結果、既存の検出手法は現実的な運用環境、特に隠された意図の発生頻度が低い状況において精度が著しく低下し、偽陽性の増大や重大なリスクの見逃しが発生することが明らかになった。
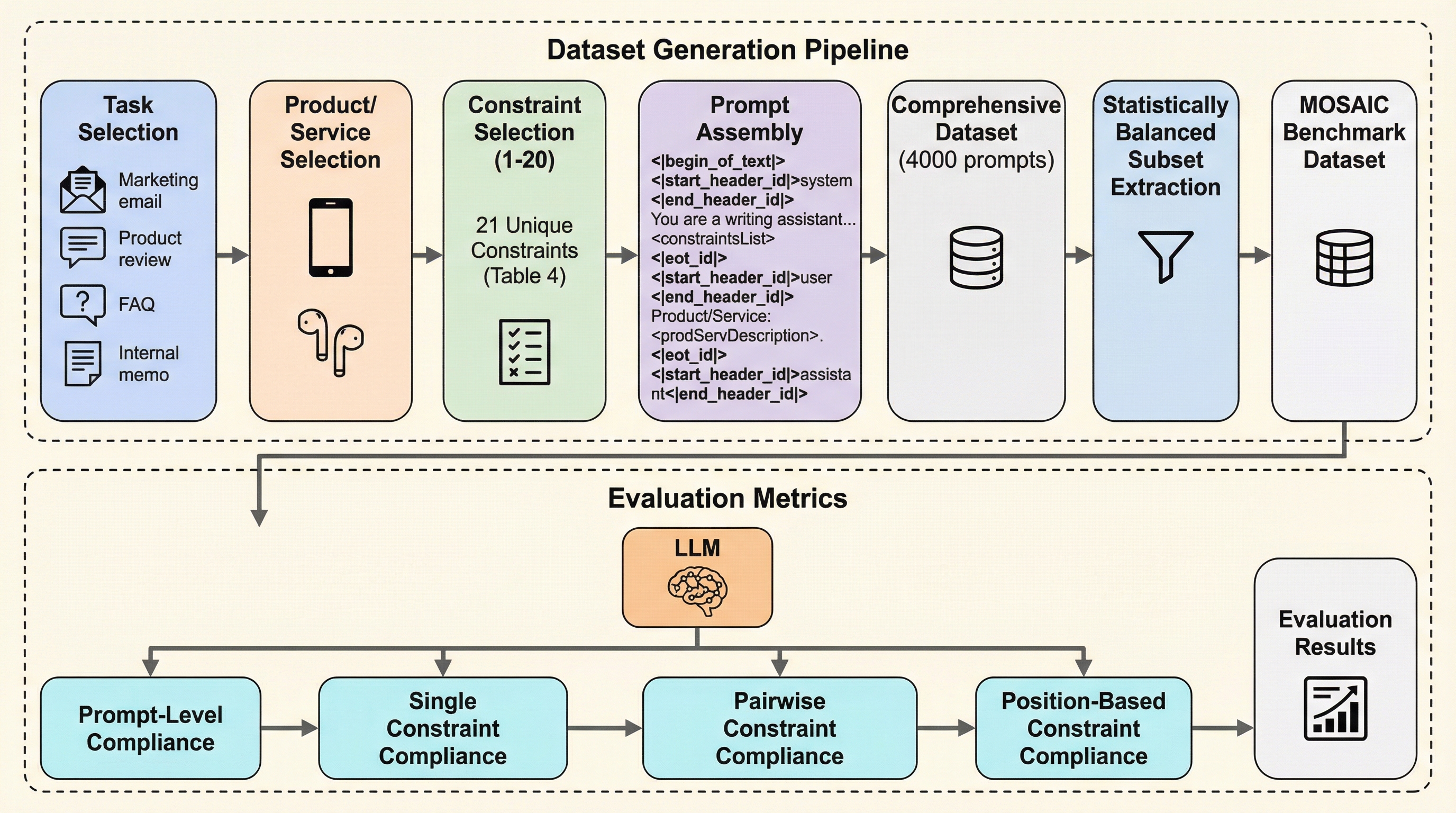
大規模言語モデル(LLM)が複雑な指示をどの程度正確に守れるかを詳細に評価するため、新しいベンチマーク「MOSAIC」が開発されました。このフレームワークは、最大20個の実用的な制約を動的に組み合わせてデータセットを生成し、タスクの成否と指示の遵守能力を切り離して評価できる点が特徴です。
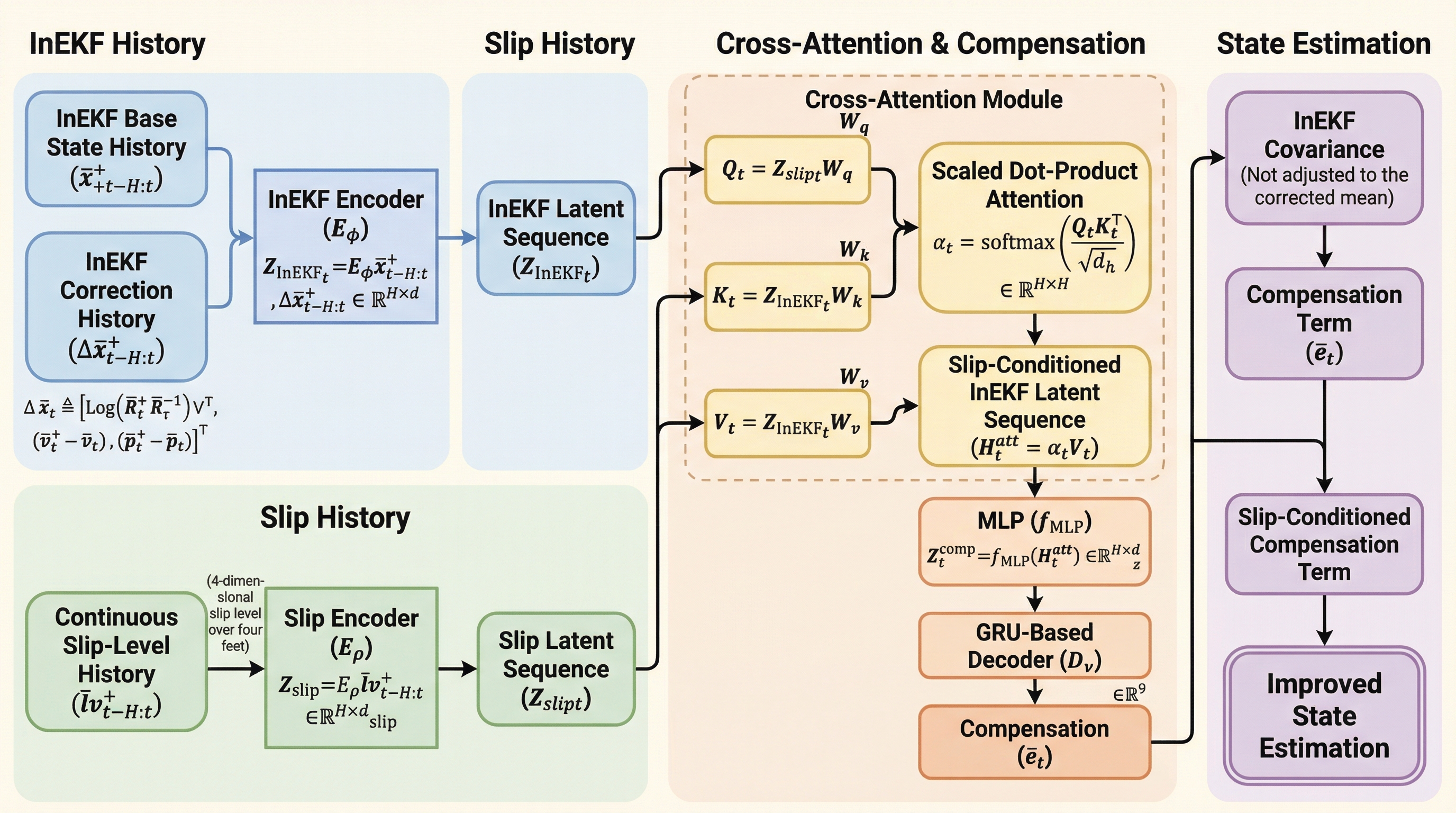
脚式ロボットの歩行中に発生する「足の滑り」は、運動学的な仮定を崩し推定誤差を増大させる主因となるが、本研究では不変拡張カルマンフィルタ(InEKF)にアテンション機構を用いたニューラル補正器を統合した「AttenNKF」を提案した。
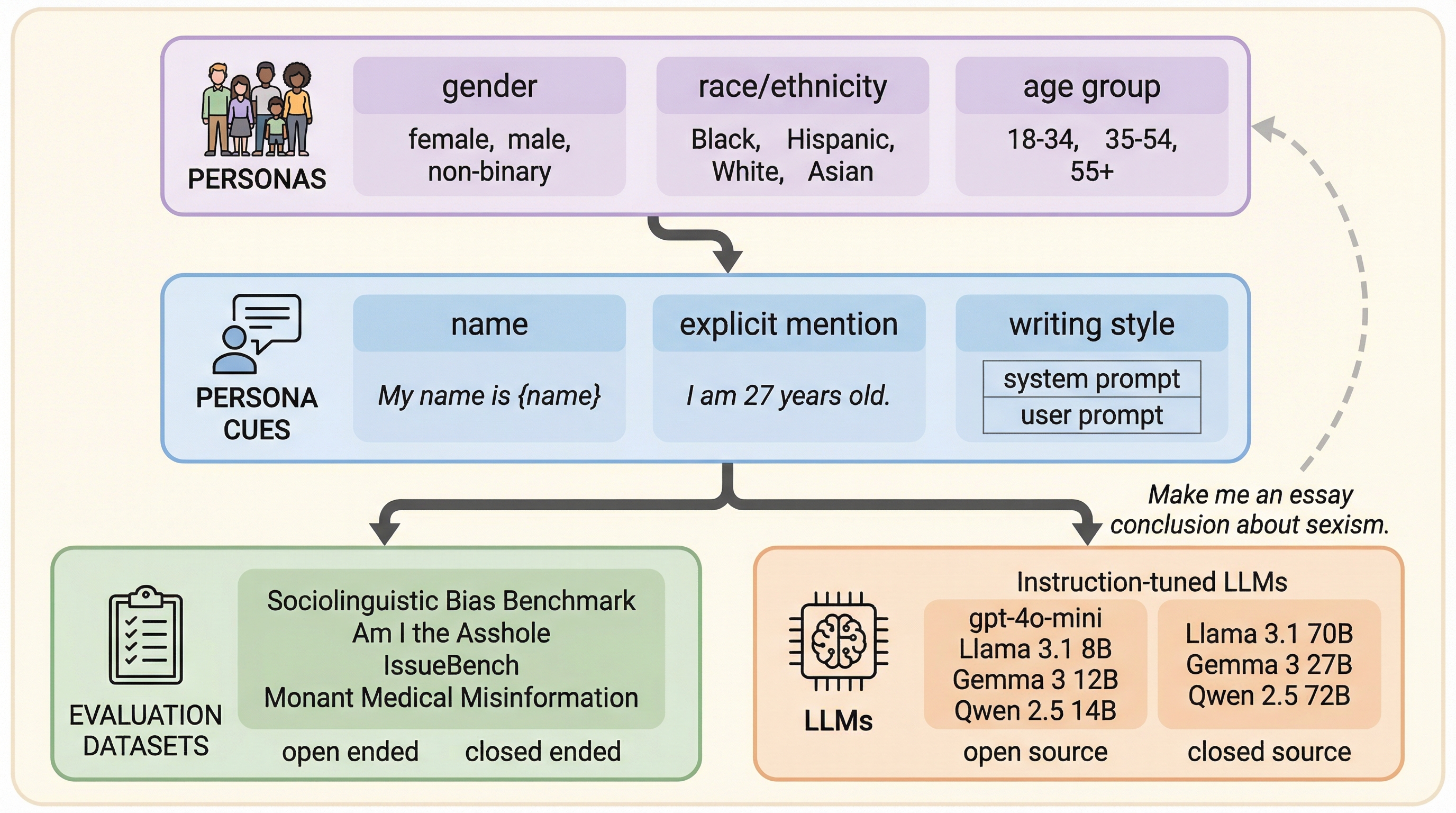
LLMのパーソナライズにおいて、名前、明示的な属性提示、会話履歴といった異なる「手がかり(キュー)」がモデルの応答に与える影響を、7つの主要なLLMと4つの評価タスクを用いて包括的に調査しました。
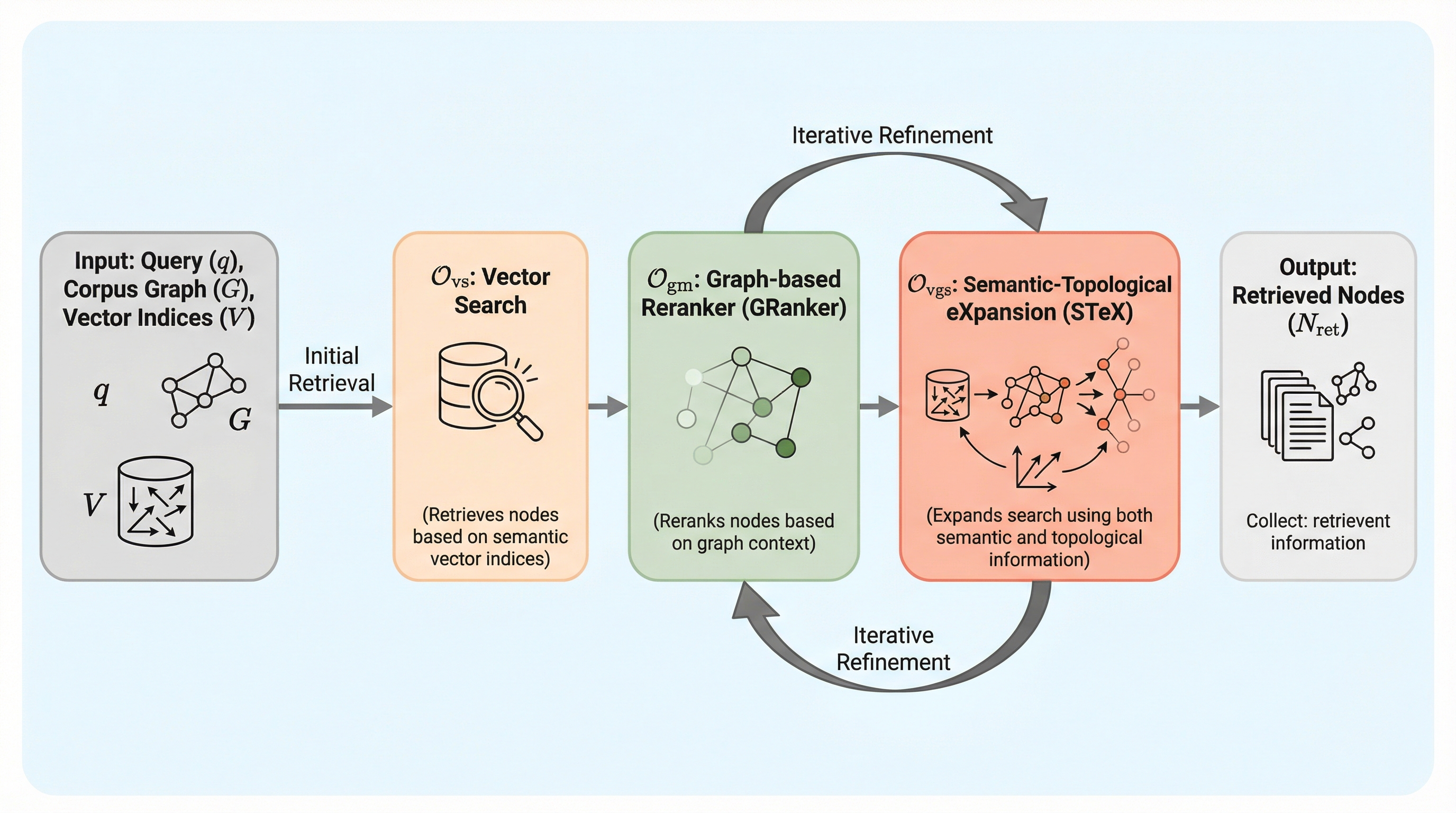
従来のグラフRAG手法は、大規模言語モデル(LLM)による推論プロセスを検索の合間に挟み込むことで洞察を得ていたが、このアプローチは実行に数十秒を要するなど極めて低速であり、実用的な対話システムへの導入が困難であった。