K-Myriad: 教師なし並列エージェントによる強化学習のジャンプスタート
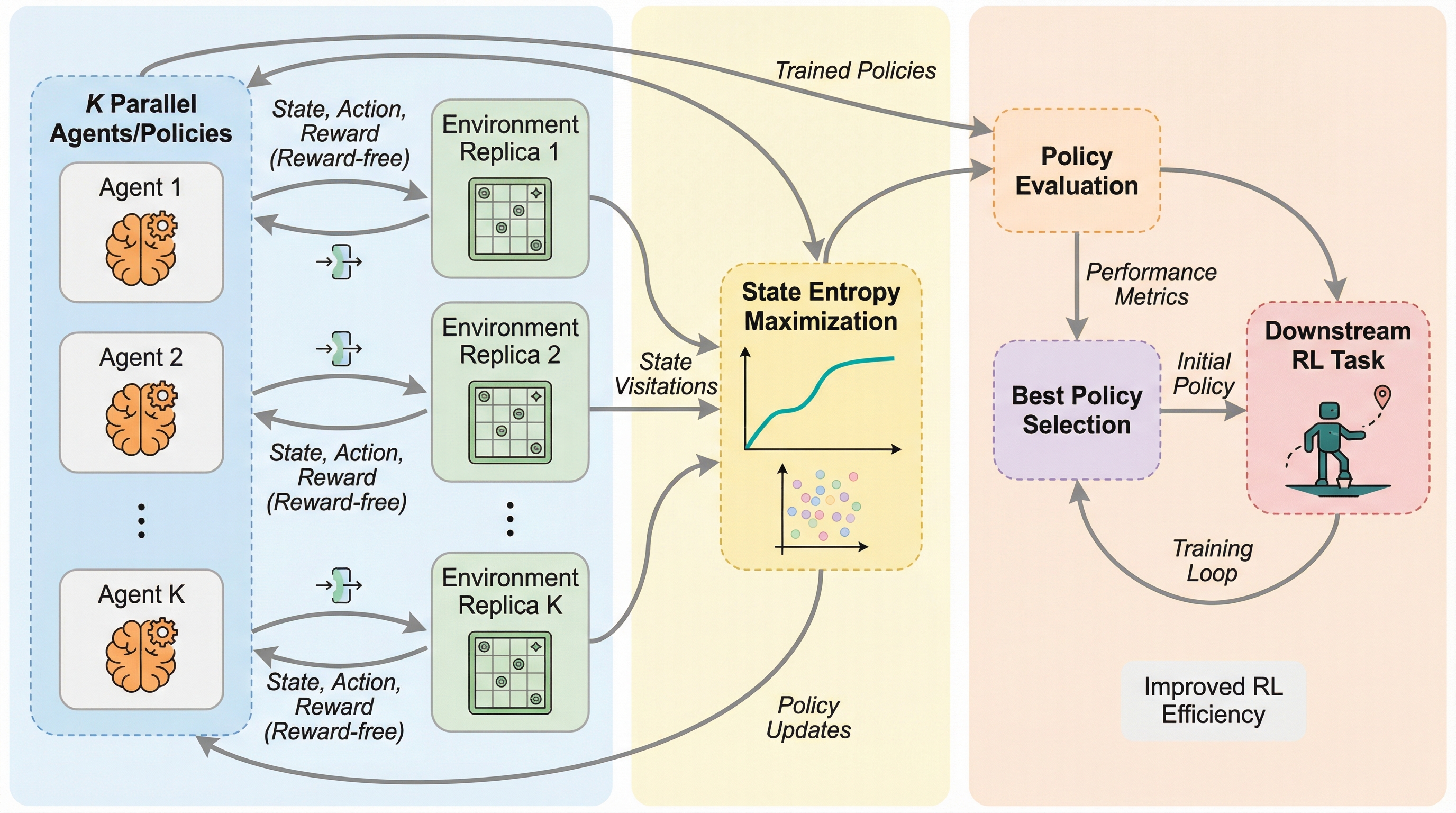
K-Myriadは、大規模な並列環境において複数のエージェントを教師なしで学習させ、集合的な状態エントロピーを最大化することで強化学習の初期探索を効率化する新しい手法である。共有のネットワーク基盤と独立した複数の政策ヘッドを組み合わせたスケーラブルなアーキテクチャにより、高次元の連続制御タスクにおいて多様な専門的探索戦略を同時に構築することが可能である。事前学習された多様な政策集団を初期値として利用することで、未知の報酬タスクにおける学習効率を大幅に向上させ、ランダムな初期化や単一の汎用的政策を超える性能を発揮することを実証した。この手法は、並列計算リソースを単なる高速化の手段としてだけでなく、探索の質を向上させるための戦略的な資産として活用する道を開くものである。
TL;DR(結論)
K-Myriadは、大規模な並列環境において複数のエージェントを教師なしで学習させ、集合的な状態エントロピーを最大化することで強化学習の初期探索を効率化する新しい手法である。共有のネットワーク基盤と独立した複数の政策ヘッドを組み合わせたスケーラブルなアーキテクチャにより、高次元の連続制御タスクにおいて多様な専門的探索戦略を同時に構築することが可能である。事前学習された多様な政策集団を初期値として利用することで、未知の報酬タスクにおける学習効率を大幅に向上させ、ランダムな初期化や単一の汎用的政策を超える性能を発揮することを実証した。この手法は、並列計算リソースを単なる高速化の手段としてだけでなく、探索の質を向上させるための戦略的な資産として活用する道を開くものである。
なぜこの問題か
強化学習(RL)は、大規模言語モデルの微調整や複雑な推論タスクにおいて目覚ましい成果を上げているが、依然としてサンプルの収集効率が極めて低いという深刻な課題を抱えている。この問題を解決するために、環境の独立したコピーを同時に実行して経験収集を加速させる大規模な並列計算が一般的に用いられている。しかし、現在の並列化手法の多くは、単一の政策のトレーニングを高速化するために複数のワーカーが同一のサンプリング分布からデータを集めるという設計にとどまっている。このような設計は、並列化が持つ「多様な探索戦略を同時に展開できる」という潜在的な利点を十分に活用できていない。強化学習の非効率性の根本原因の一つは探索の難しさにあり、特に報酬が稀少な環境ではエージェントが意味のある経験を積むまでに膨大な時間を要する。 最近の研究では、ロールアウトの長さを伸ばすよりも並列環境の数を増やす方が、計算リソースをより有効に活用できることが示されている。これは、並列環境においてリセットを避けつつ多様な探索を行うことが、固定された開始状態分布から長い軌跡をサンプリングするよりも有益であるためだと推測される。…
核心:何を提案したのか
本研究では、大規模な並列マルコフ決定過程(PMDP)において、複数の政策からなる集団が集合的に状態エントロピーを最大化する、スケーラブルで教師なしのアルゴリズム「K-Myriad」を提案した。K-Myriadの主な目的は、環境内の広範な状態をカバーする多様な専門的探索戦略のポートフォリオを育成することである。これにより、強化学習の初期段階において、どのような報酬関数が与えられたとしても、そのタスクに適合した行動を既に持っている政策をコレクションの中から見つけ出すことが可能になる。K-Myriadは、最大50個の独立した政策ヘッドを持つ単一のニューラルネットワークアーキテクチャを採用しており、数百から数千の環境コピーと同時に対話しながら学習を進めることができる。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related