指示追従の解体:大規模言語モデルの指示遵守能力を詳細に評価するための新しいベンチマーク
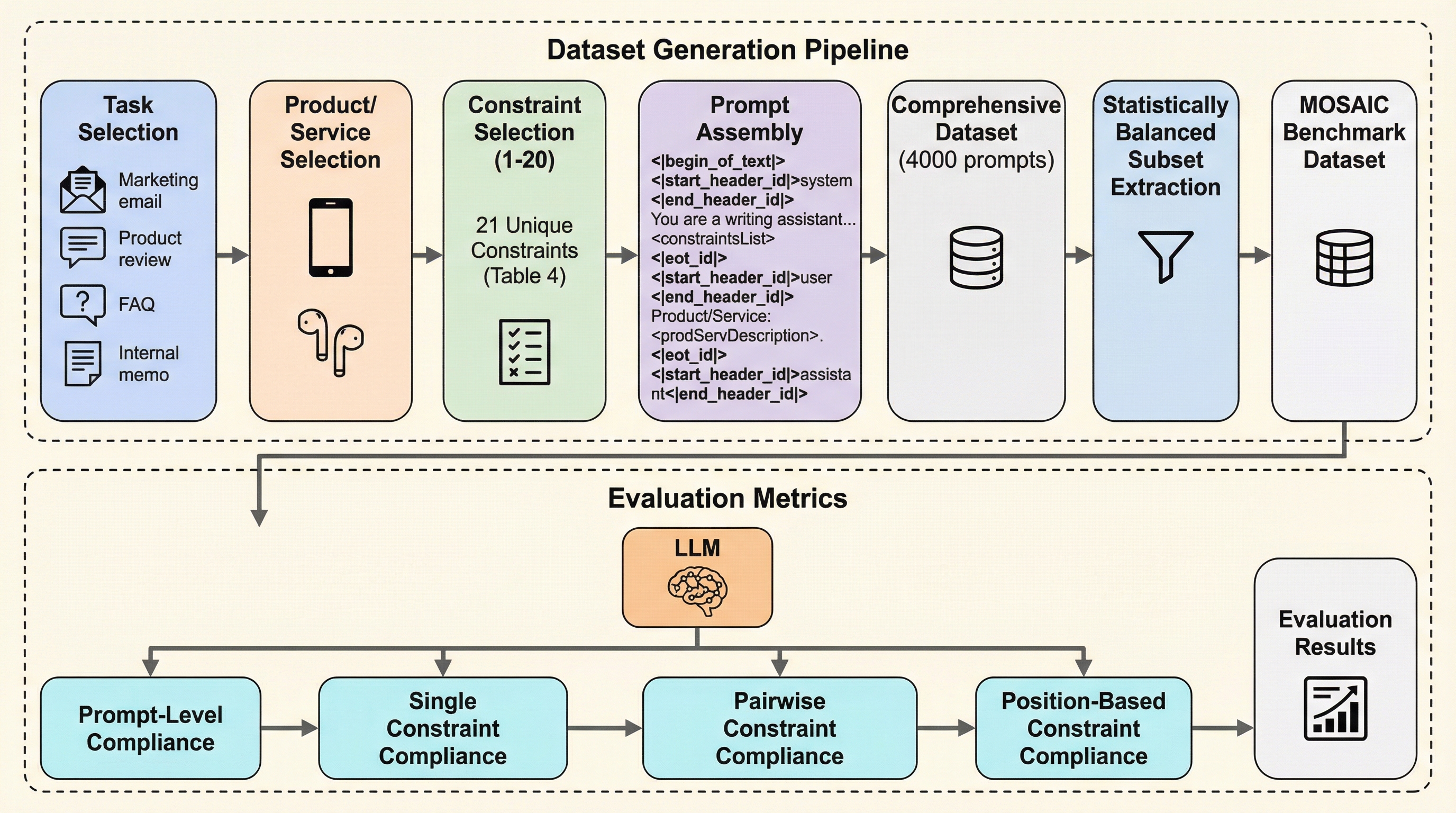
大規模言語モデル(LLM)が複雑な指示をどの程度正確に守れるかを詳細に評価するため、新しいベンチマーク「MOSAIC」が開発されました。このフレームワークは、最大20個の実用的な制約を動的に組み合わせてデータセットを生成し、タスクの成否と指示の遵守能力を切り離して評価できる点が特徴です。
TL;DR(結論)
大規模言語モデル(LLM)が複雑な指示をどの程度正確に守れるかを詳細に評価するため、新しいベンチマーク「MOSAIC」が開発されました。このフレームワークは、最大20個の実用的な制約を動的に組み合わせてデータセットを生成し、タスクの成否と指示の遵守能力を切り離して評価できる点が特徴です。 5つの主要なLLMを評価した結果、指示の遵守能力は単一の能力ではなく、制約の種類や数、提示される順番によって大きく変動することが明らかになりました。特に、指示の提示順によるバイアスや、特定の制約同士の相乗効果および競合関係が、モデルの失敗を診断する重要な指標となることが示されています。 本研究は、従来のベンチマークが抱えていた「実用性の欠如」や「データ漏洩」といった課題を解決し、より信頼性の高いLLM開発のための詳細な洞察を提供します。
なぜこの問題か
現在、大規模言語モデルはエージェント型のパイプラインや情報処理システムにおいて、重要な構成要素として利用されています。これらのシステムでは、モデルが単にタスクをこなすだけでなく、入力プロンプトに含まれる一連の標準的な指示や制約に厳密に従うことが求められます。しかし、既存の評価手法にはいくつかの重大な欠陥が存在しており、現実世界のアプリケーションにおける信頼性を十分に測定できていないのが現状です。 第一の課題は、既存のベンチマークで使用される制約が、現実の利用シーンから乖離している点です。例えば「大文字の単語を特定の回数出現させる」といった制約は、測定は容易ですが実用的な意味は乏しいと言えます。第二に、多くのベンチマークでは「タスクの解決能力」と「指示の遵守能力」が混同されています。要約の質が高くても、文字数制限を守れなければシステムとしては不合格ですが、従来の評価ではこれらを分離して分析することが困難でした。これは、モデルが正確な回答を出しつつ指示に違反する場合や、逆に指示には従っているが内容が不正確である場合を区別できないことを意味します。 第三の課題として、一度に評価される制約の数が非常に少ないことが挙げられます。…
核心:何を提案したのか
本論文では、LLMの指示遵守能力を粒度細かく独立して分析するためのモジュール型フレームワーク「MOSAIC(MOdular Synthetic Assessment of Instruction Compliance)」を提案しています。MOSAICは、動的に生成されるデータセットを用いることで、最大20個のアプリケーション指向の生成制約を組み合わせた評価を可能にします。このアプローチの核心は「モジュール性」にあり、特定のタスクと制約を切り離して管理することで、モデル固有の指示追従能力を純粋に測定できる点にあります。 評価に用いられる制約は、以下の5つのカテゴリに分類される計21種類で構成されています。 1.…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related