検証可能なドットから報酬の連鎖へ:オープンエンド生成の強化学習における検証可能な参照ベース報酬の活用
数学やコード生成で成果を上げた「検証可能な報酬(RLVR)」を、正解が一つではないオープンエンドな文章生成タスクに拡張するため、参照回答から抽出した順序付き言語信号「報酬の連鎖」を利用する新手法「RLVRR」を提案しました。
TL;DR(結論)
数学やコード生成で成果を上げた「検証可能な報酬(RLVR)」を、正解が一つではないオープンエンドな文章生成タスクに拡張するため、参照回答から抽出した順序付き言語信号「報酬の連鎖」を利用する新手法「RLVRR」を提案しました。 報酬を「核となる概念を保持するコンテンツ」と「Pythonコードで形式を検証するスタイル」に分解し、キーワードの出現順序を評価する最長共通部分列(LCS)を用いることで、従来の報酬モデルが抱えていたハッキングや高コストの問題を解決しています。 10以上のベンチマークで、10倍のデータを用いた教師あり微調整や最新の報酬モデルを凌駕する性能を示し、構造化された推論と自由な文章生成の学習を一つの枠組みで統合できる高い汎用性と効率性を実証しました。
なぜこの問題か
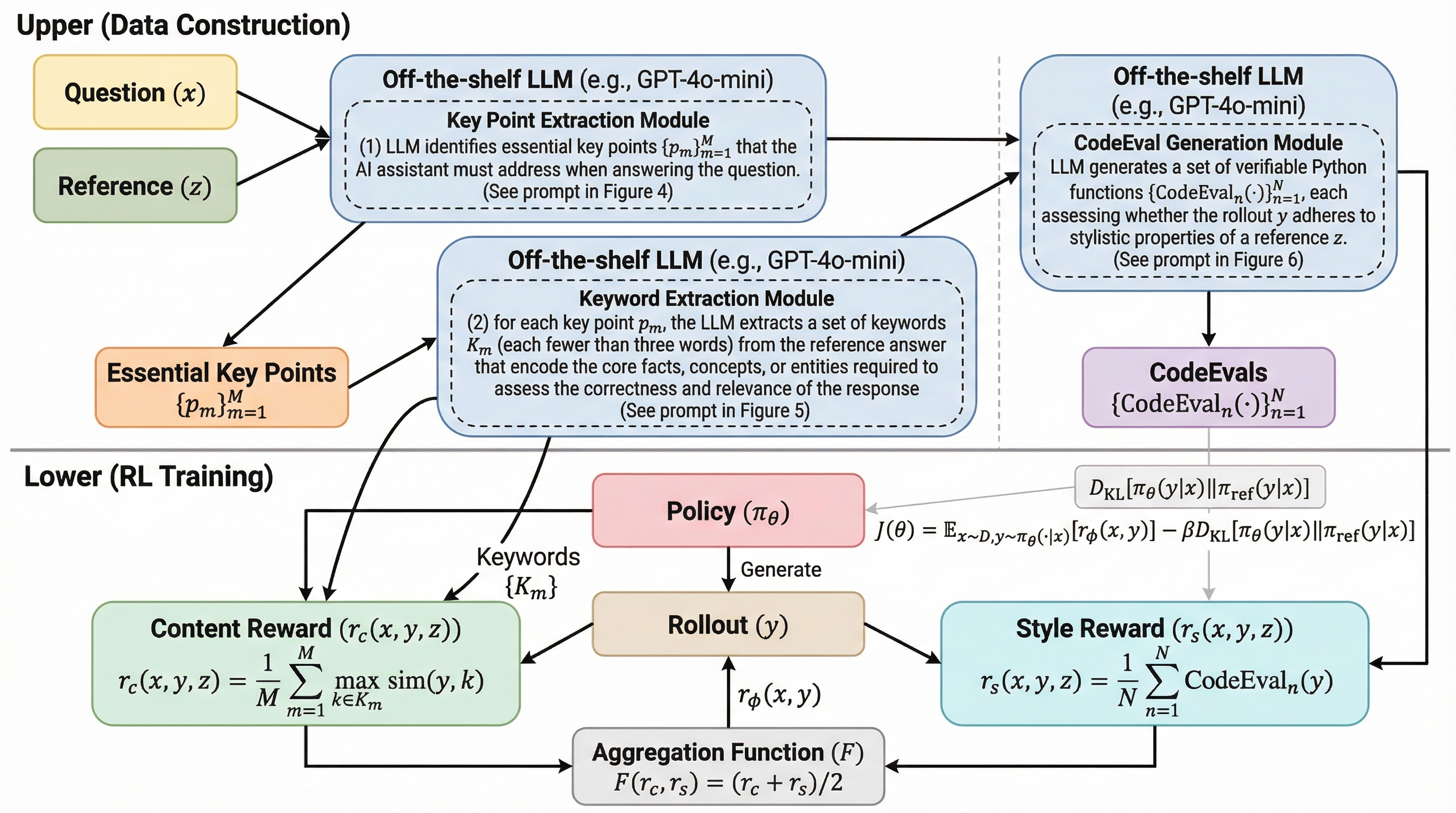
大規模言語モデルの性能向上において、数学やプログラミングのような推論タスクでは、最終的な答えの正誤を自動判定する「検証可能な報酬を用いた強化学習(RLVR)」が極めて有効であることが証明されています。この手法は、思考の連鎖の各ステップを細かく監視するのではなく、最終的な「検証可能なドット(一点の正解)」のみをチェックすることで、モデルが自由な探索を通じて正しい推論経路を自律的に発見することを可能にします。しかし、この成功したパラダイムを、自由記述形式のオープンエンドな文章生成タスクにそのまま適用することは困難でした。なぜなら、文章生成には数学のような唯一無二の明確な正解が存在せず、信頼性の高い検証を単一の指標に集約することができないからです。 オープンエンドな生成タスクにおいて、高品質な回答は通常、複数のコンテンツ要件を同時に満たす必要があります。例えば、安全性に関する指示に従う場合、リスクの説明、有害な要求の拒否、関連する規則の引用、そして代替案の提示といった複数の要素が求められます。…
核心:何を提案したのか
本研究では、従来のRLVRをオープンエンド生成へと拡張する新しいフレームワーク「RLVRR(検証可能な参照ベース報酬を用いた強化学習)」を提案しています。この手法の核心は、単一の「検証可能なドット」に依存するのではなく、高品質な参照回答から抽出された「報酬の連鎖(Reward Chain)」と呼ばれる順序付きの検証可能な言語信号を利用する点にあります。これは、数学的推論が正解から規則を導き出すのと同様に、参照回答から標準化された検証チェックリストを作成し、それを強化学習の探索における錨(アンカー)として機能させるという革新的な発想に基づいています。 RLVRRは、報酬の設計を「コンテンツ(内容)」と「スタイル(形式)」という二つの相補的な次元に分解することで、監視の信頼性と効率性を両立させています。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related