モダリティ・ギャップの解消はグループ単位の意味を整合させる
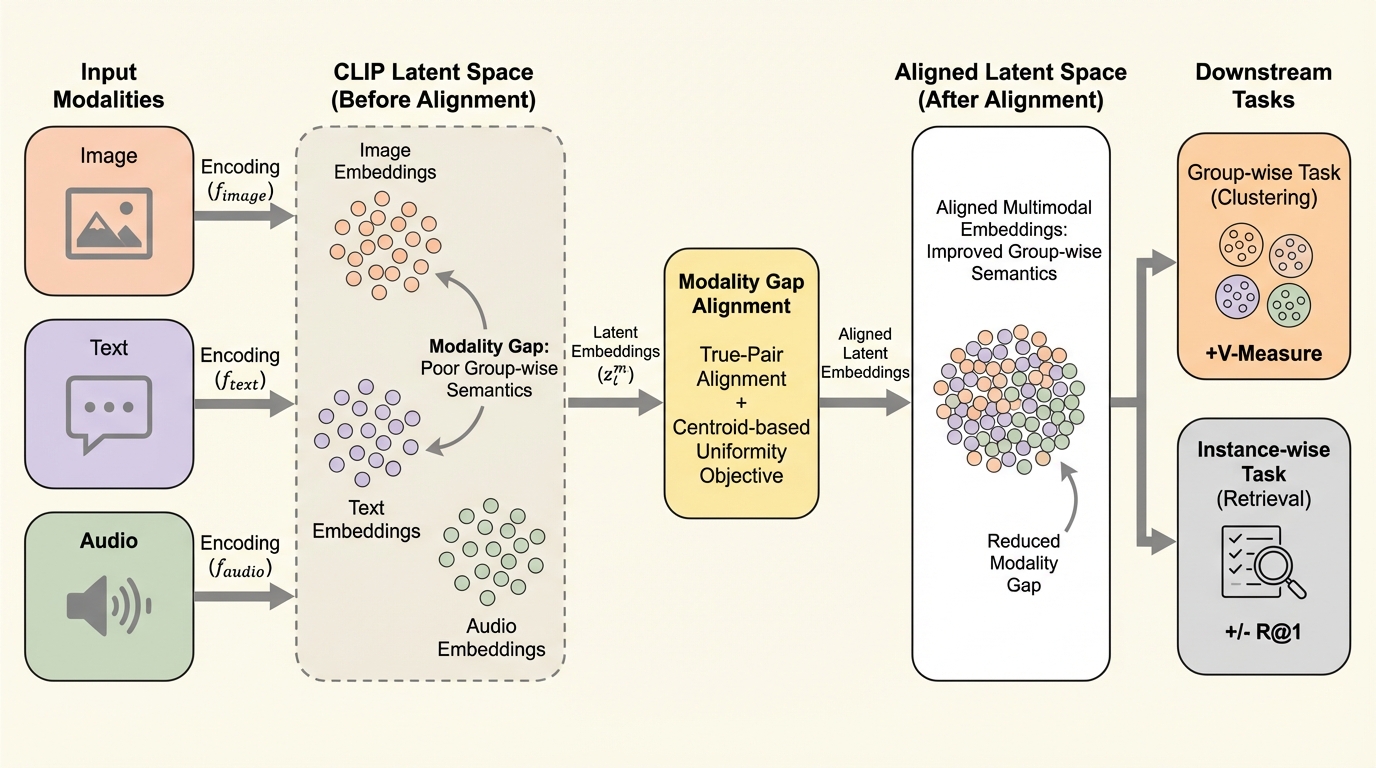
マルチモーダル学習の標準手法であるCLIPにおいて、異なるデータ形式(画像やテキスト等)が潜在空間内で分離してしまう「モダリティ・ギャップ」が、クラスタリングなどのグループ単位のタスク性能を著しく低下させていることを解明した。
TL;DR(結論)
マルチモーダル学習の標準手法であるCLIPにおいて、異なるデータ形式(画像やテキスト等)が潜在空間内で分離してしまう「モダリティ・ギャップ」が、クラスタリングなどのグループ単位のタスク性能を著しく低下させていることを解明した。 この問題を解決するため、正のペアを直接整列させる損失と、データの平均値(セントロイド)を空間全体に均一に分散させる損失を組み合わせた新しい目的関数を提案し、検索精度を維持したままギャップを効果的に解消することに成功した。 複数のデータセットを用いた検証により、提案手法はモダリティ間の絶対的な距離を縮小し、意味的に一貫性のある潜在空間を構築することで、特にグループ単位のセマンティクスを扱うタスクにおいて従来手法を上回る性能を実証した。
なぜこの問題か
マルチモーダル学習において、CLIPに代表される対照学習モデルは、異なる種類のデータ間で共有の潜在空間を構築するための重要な技術として位置づけられている。この手法の本来の目的は、意味的に関連のある表現を近くに配置し、関連のないものを遠ざけることにある。しかし、実際には学習された潜在空間において、画像やテキストといった各モダリティが独自のクラスターを形成し、完全に融合しない「モダリティ・ギャップ」と呼ばれる構造的な不一致が生じることが知られている。この現象は、データが潜在空間内で断片化され、意味的な整合性が損なわれる原因となっている。 これまで、このモダリティ・ギャップが実用上のタスクにどのような影響を与えるかについては、研究者の間でも意見が分かれていた。特に、画像検索やテキスト検索のような「インスタンス単位」のタスクにおいては、このギャップが性能に与える影響は比較的小さいと考えられてきた。検索タスクは相対的なランキングに基づいて正解を導き出すため、各モダリティが分離していても、正しいペアが他の候補よりも相対的に近い位置にあれば目的を達成できるからである。…
核心:何を提案したのか
本研究では、マルチモーダルな潜在空間におけるモダリティ・ギャップを一貫して減少させ、意味的な整合性を高めるための新しい目的関数を提案している。この手法の最大の特徴は、モデルのアーキテクチャを複雑に変更したり、学習後に特別な補正処理を行ったりすることなく、損失関数を工夫するだけでギャップを解消できる点にある。また、画像とテキストのペアだけでなく、音声を含む三つ以上のモダリティが存在する一般的なケースにも容易に拡張できる汎用性を備えている。 提案された損失関数は、主に二つの新しい要素で構成されている。一つ目は「真ペア整列損失(LATP)」である。これは、異なるモダリティ間での正のペア(例えば、特定の画像とその内容を説明するテキスト)の間のユークリッド距離を直接的に最小化するものである。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related