形態統語的特徴との統計的アライメントによるサブワードトークン化の形態論的妥当性の評価
サブワードトークン化の形態論的な妥当性を評価するために、人間が作成した正解の分割データに依存することなく、形態統語的特徴との統計的なアライメントを活用する画期的な新しい評価指標を提案した。具体的には、統計的機械翻訳の手法であるIBM Model 1を応用し、トークナイザーが生成したサブワードと、UniMorphなどのリソースから得られる形態的特徴を確率的に紐付け、その結びつきの強さをスコア化することで、多言語におけるトークナイザーの品質を客観的に測定することを可能にした。大規模な実験の結果、この提案指標は従来の形態素境界の再現率と極めて強い相関を示すことが確認され、特に形態的に複雑な構造を持つ言語において、高品質な正解データが不足している状況下でも、トークナイザーの形態論的な質を評価するための信頼できる代替手段となることを実証した。
TL;DR(結論)
サブワードトークン化の形態論的な妥当性を評価するために、人間が作成した正解の分割データに依存することなく、形態統語的特徴との統計的なアライメントを活用する画期的な新しい評価指標を提案した。具体的には、統計的機械翻訳の手法であるIBM Model 1を応用し、トークナイザーが生成したサブワードと、UniMorphなどのリソースから得られる形態的特徴を確率的に紐付け、その結びつきの強さをスコア化することで、多言語におけるトークナイザーの品質を客観的に測定することを可能にした。大規模な実験の結果、この提案指標は従来の形態素境界の再現率と極めて強い相関を示すことが確認され、特に形態的に複雑な構造を持つ言語において、高品質な正解データが不足している状況下でも、トークナイザーの形態論的な質を評価するための信頼できる代替手段となることを実証した。
なぜこの問題か
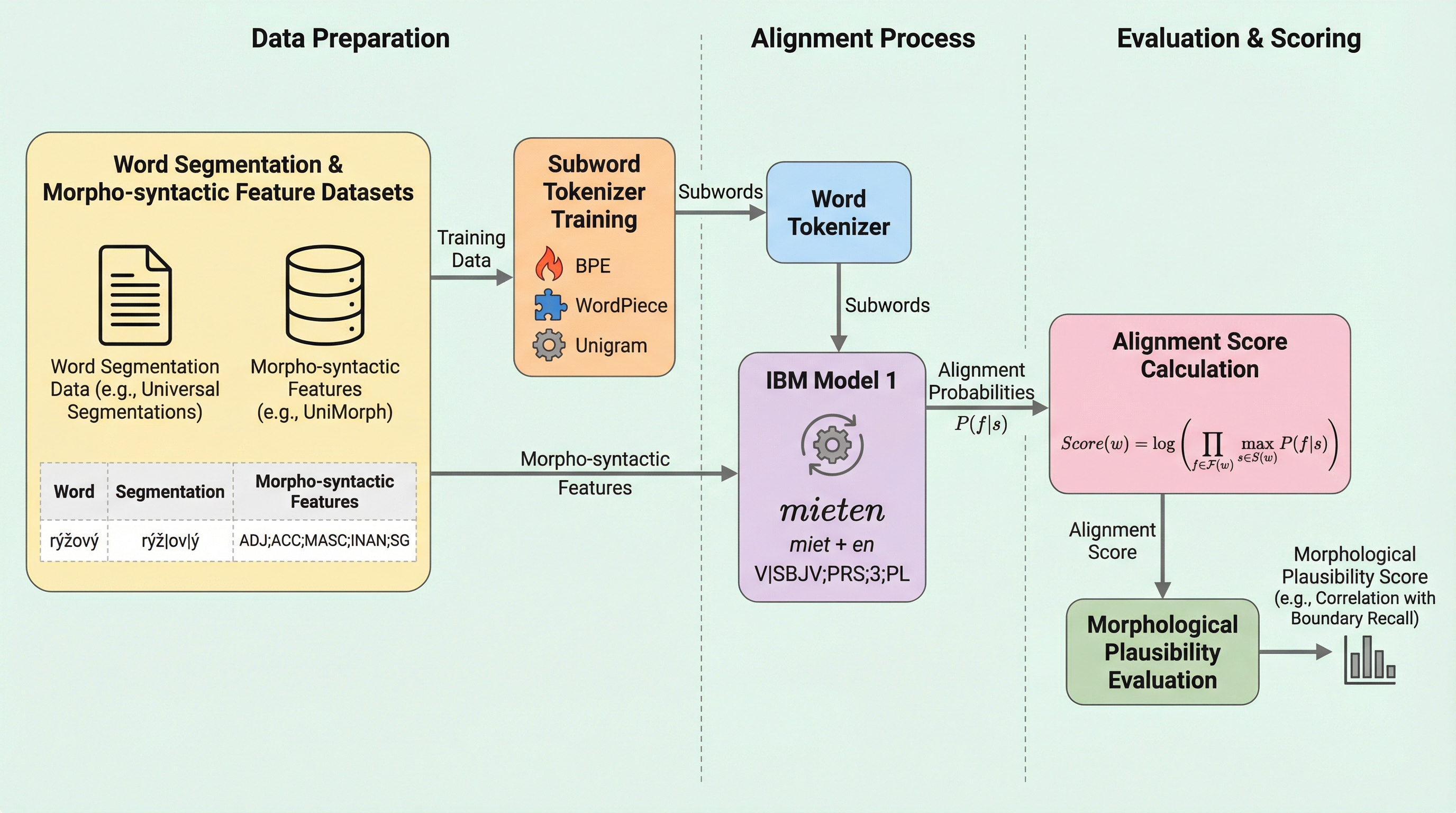
我々は、サブワード分割の形態論的妥当性を評価するための新しい指標を提案する。多くの言語で入手不可能であったり品質が不均一であったりする正解分割データを必要とする、一般的に用いられる形態素境界や検索のF値とは異なり、本手法は形態統語的特徴を利用する。これらは、ユニバーサル・ディペンデンシーズやユニモーフなどのリソースにおいて、より広範な言語で利用可能である。この指標は、IBMモデル1を通じてサブワードと形態論的特徴を確率的に対応付けることで機能する。実験の結果、本指標は従来の形態素境界の再現率と良好な相関を示しつつ、異なる形態体系を持つ言語間でもより広く適用可能であることが示された。 現代の自然言語処理システムにおいて、サブワードトークン化はテキストを処理可能な単位に分割するための極めて重要な前処理ステップとなっている。しかし、トークナイザーが形態論的にどれほど妥当な分割を行っているかを正確に評価することは、依然として解決すべき大きな課題である。従来の評価手法では、言語学者が作成した正解の形態素分割データ、いわゆるゴールドスタンダードとの比較に基づいた、境界の再現率やF1スコアが一般的に用いられてきた。…
核心:何を提案したのか
本研究では、正解の分割データを一切必要とせず、代わりに形態統語的特徴を利用してサブワードトークン化の形態論的妥当性を評価する、新しい統計的アライメント指標を提案した。この手法の根底にあるのは、「適切に分割されたサブワードは、特定の文法機能や形態的特徴を一貫して表現する単位であるはずだ」という直感的な原理である。具体的には、Universal DependenciesやUniMorphといった既存の言語リソースから得られる形態統語的特徴を最大限に活用する。UniMorphは、169もの広範な言語に対して、言語に依存しない共通のスキーマで形態的特徴を提供している。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related