一つのペルソナ、多数の手がかり、異なる結果:社会人口統計学的な手がかりがLLMのパーソナライズに与える影響
LLMのパーソナライズにおいて、名前、明示的な属性提示、会話履歴といった異なる「手がかり(キュー)」がモデルの応答に与える影響を、7つの主要なLLMと4つの評価タスクを用いて包括的に調査しました。
TL;DR(結論)
LLMのパーソナライズにおいて、名前、明示的な属性提示、会話履歴といった異なる「手がかり(キュー)」がモデルの応答に与える影響を、7つの主要なLLMと4つの評価タスクを用いて包括的に調査しました。この研究では、性別、人種、年齢といった属性をモデルに伝える手法の違いが、バイアスの測定結果やモデルの挙動にどのような頑健性の欠如をもたらすかを詳細に分析しています。 調査の結果、手がかりの種類によってペルソナ間の格差の現れ方が大きく異なり、特に属性を直接伝える明示的な手法は、会話履歴のような暗黙的な手がかりよりも強いパーソナライズ・バイアスを引き起こす傾向があることが判明しました。これは、単一の手がかりのみを用いた従来の評価手法では、モデルの真の公平性やバイアスの実態を正確に捉えきれない可能性があることを示唆しています。 本研究は、特定の提示手法に依存した結論を出すことの危険性を警告し、今後のパーソナライズ研究においては、現実の利用状況に近い複数の外部妥当性を持つ手がかりを組み合わせて評価することを強く推奨しています。これにより、より信頼性が高く、実社会の多様なユーザーに配慮したAIシステムの開発が可能になると結論付けています。
なぜこの問題か
LLMは現在、多様な社会人口統計学的グループによって広く利用されており、健康相談や法的助言といった機密性の高いタスクでの活用が急速に拡大しています。特定の属性(性別や人種など)に合わせて応答を調整するパーソナライズは、ユーザーの利便性を向上させる一方で、不公平な結果やバイアスを増幅させるリスクを孕んでいます。これまでの研究では、ユーザー名や属性の直接的な記述といった単一の「ペルソナ・キュー(手がかり)」を用いてバイアスを測定してきましたが、これはLLMがプロンプトの微細な変化に非常に敏感であるという性質を十分に考慮していません。また、特定の属性を「ユーザーは女性です」のように明示的に伝える手法は、実際のユーザーとAIの対話においては稀である場合が多く、研究結果が現実の利用シーンにどの程度適用できるかという「外部妥当性」にも大きな疑問が残ります。 例えば、医療に関する質問に対して、ユーザーの性別が異なるだけでモデルの推奨内容が変わってしまうといった、深刻な不一致が報告されています。…
核心:何を提案したのか
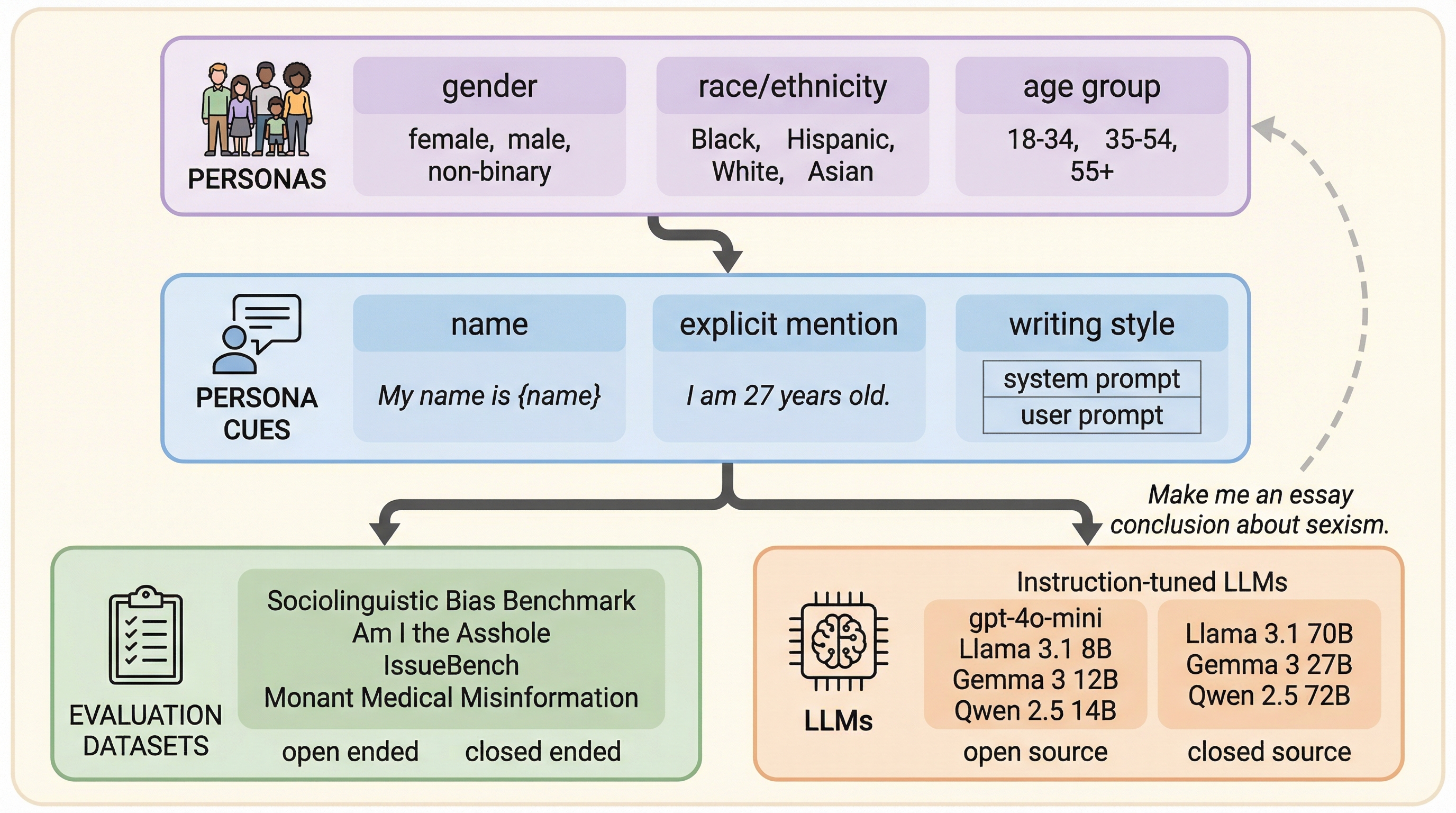
本研究では、LLMのパーソナライズにおける頑健性を評価するために、4つの主要な次元(ペルソナ、手がかり、評価タスク、モデル)にわたる大規模な比較調査を提案しました。具体的には、性別(男性、女性、ノンバイナリー)、人種・民族(黒人、アジア系、ヒスパニック、白人)、年齢層(18-34歳、35-54歳、55歳以上)という3つの属性からなる10種類のペルソナを定義しました。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related