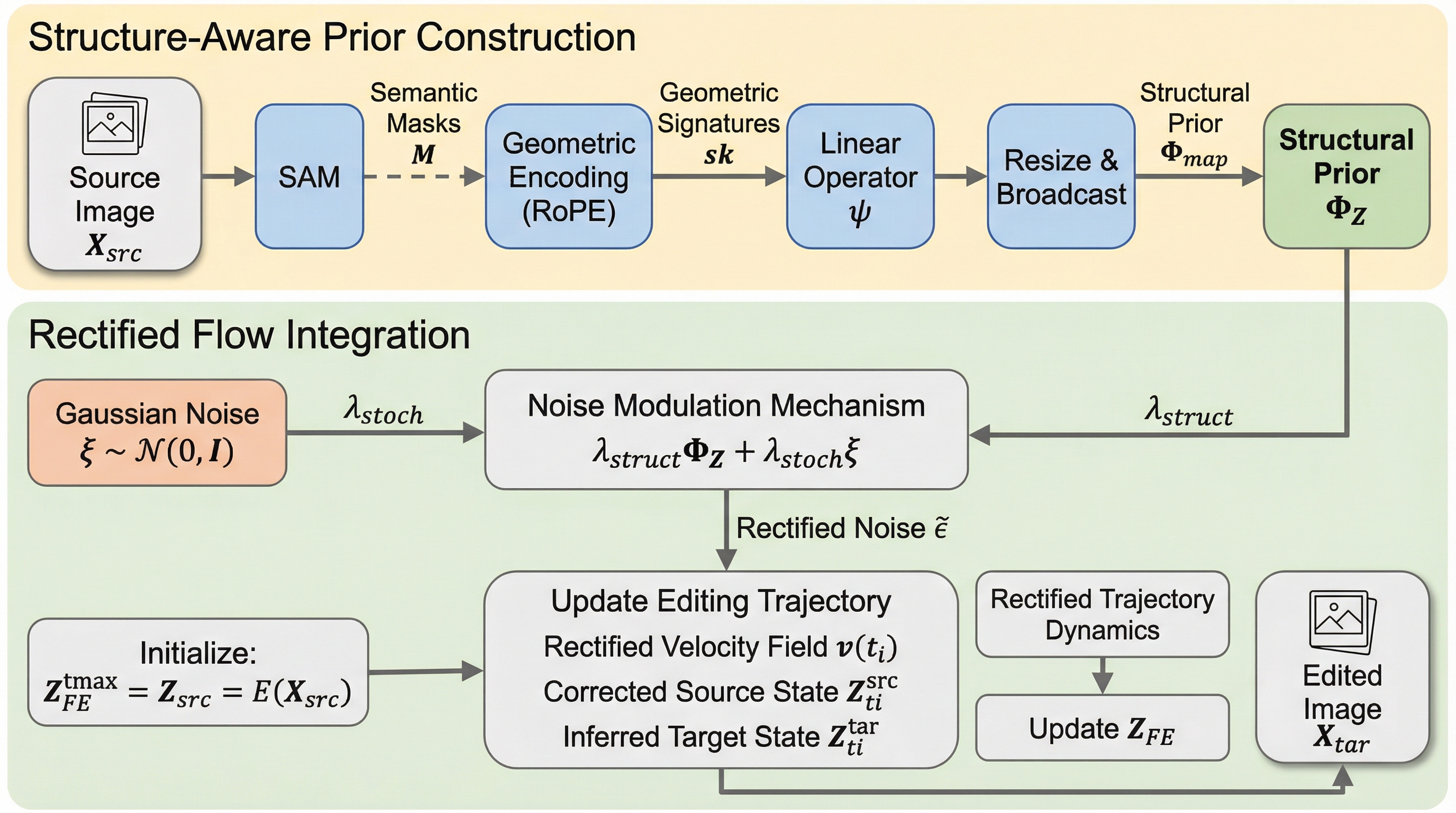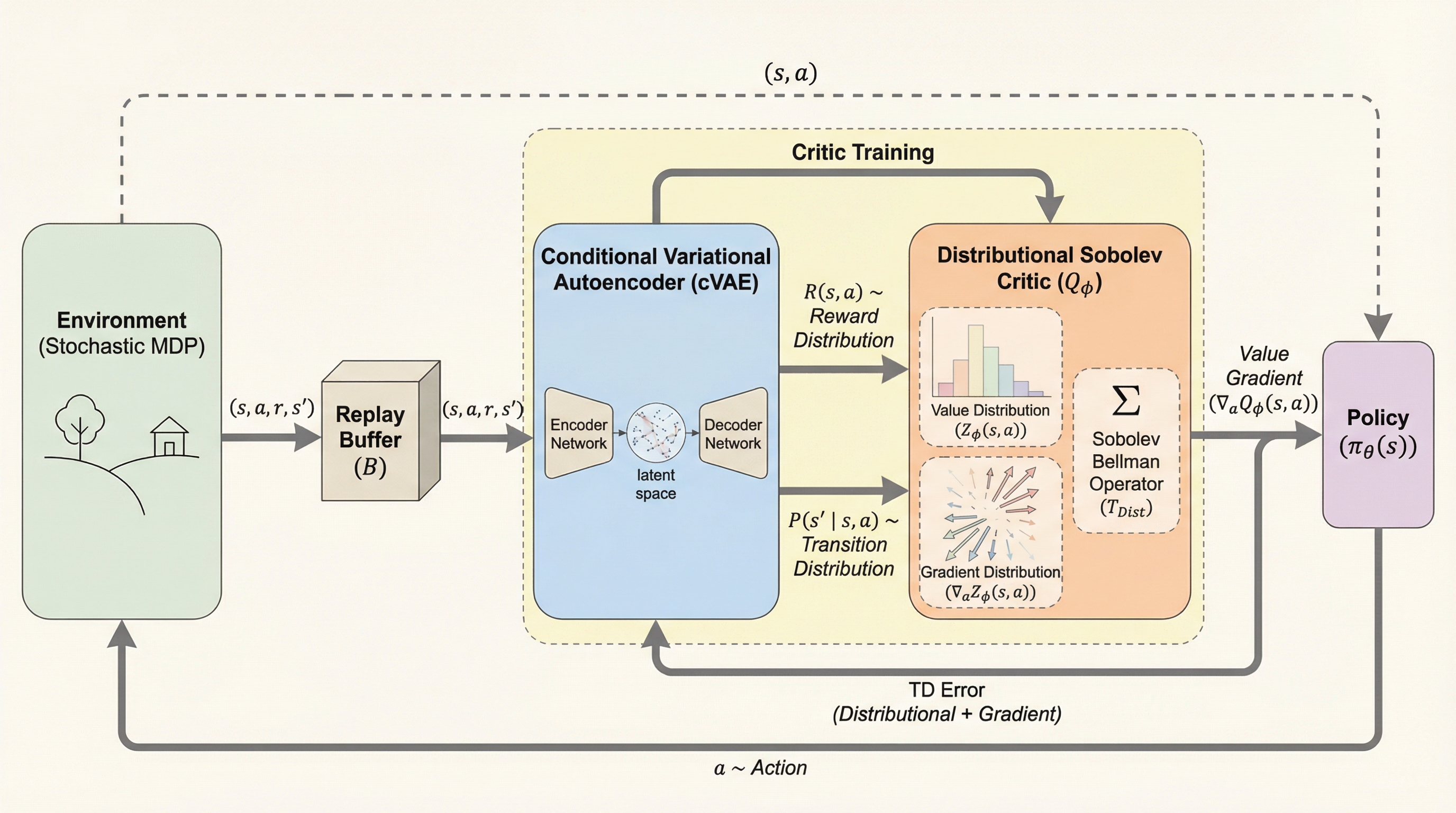
確率的環境における分布型価値勾配法:分布型ソボレフ学習
連続アクション空間の強化学習において、報酬の期待値だけでなく、累積報酬とそのアクション勾配の両方をジョイント分布として同時にモデル化する「分布型ソボレフ学習」という新しい枠組みを提案した。 理論面では、最大スライス最大平均不一致(MSMMD)という指標を用いることで、提案したソボレフ・ベルマン演算子が唯一の不動点に収束する縮小写像であることを数学的に証明し、さらに条件付き変分オートエンコーダ(cVAE)を用いた微分可能なワールドモデルを導入することで、非微分可能な環境への適用を可能にした。 実験では、マルチモーダルな不確実性を持つトイタスクやMuJoCoベンチマークにおいて、従来の決定論的な勾配手法や勾配を考慮しない分布型手法を大幅に上回るサンプル効率と堅牢性を実証し、勾配情報の分布を捉えることが連続制御における学習に極めて有効であることを示した。