Floresが間違ってBloomzするとき:機械翻訳評価における言語方向間の汚染
大規模言語モデル(LLM)の評価において、学習データにテストセットが混入する「データ汚染」が深刻な問題となっており、特に多言語翻訳では、ある言語方向の学習が未学習の言語方向にまで影響を及ぼす「方向間汚染」が発生していることが明らかになった。
TL;DR(結論)
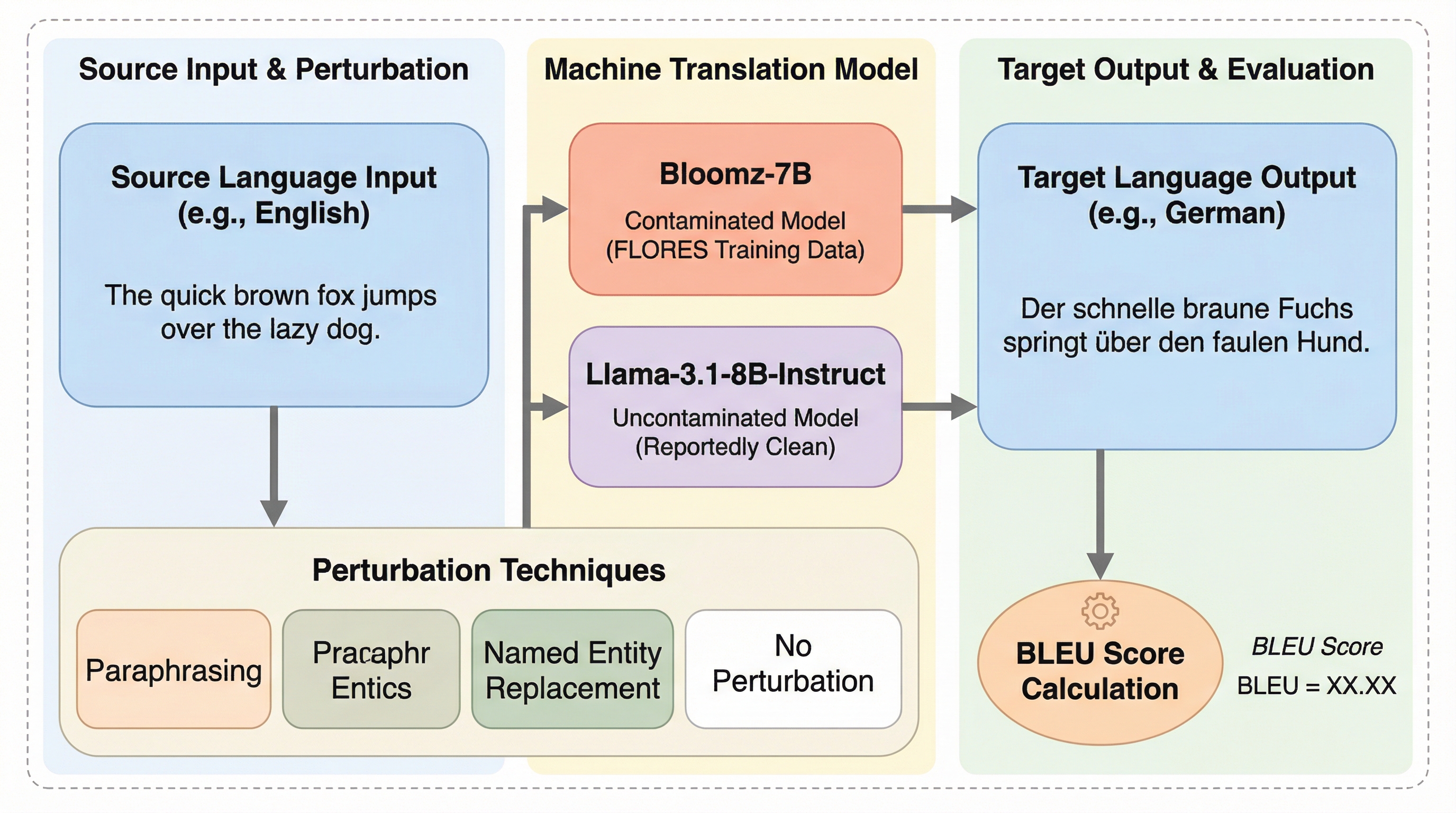
大規模言語モデル(LLM)の評価において、学習データにテストセットが混入する「データ汚染」が深刻な問題となっており、特に多言語翻訳では、ある言語方向の学習が未学習の言語方向にまで影響を及ぼす「方向間汚染」が発生していることが明らかになった。 本研究では、FLORES-200ベンチマークを用いて、意図的に汚染されたBloomzとクリーンなLlamaを比較した結果、モデルがターゲット側の文章を暗記することで、見たことのない翻訳方向でも異常に高いスコアを出す現象を確認し、ソース側の言い換えや摂動を与えてもこの暗記の呼び出しを完全には防げないことを示した。 汚染を検知する有効な手法として、ソース文中の固有名詞(エンティティ)を置き換える手法を提案し、これにより暗記に基づく異常なスコア上昇を特定できることを実証するとともに、ファインチューニング実験を通じて、特定の言語ペアの学習がターゲット言語を共有する他の翻訳方向に汚染を広げるメカニズムを解明した。
なぜこの問題か
大規模言語モデル(LLM)の性能を正確に評価することは、現在のAI研究における最優先事項の一つである。しかし、LLMの学習には数十億から数兆トークンという膨大なデータが使用されるため、公開されている評価用ベンチマークが意図せず学習データに含まれてしまう「データ汚染」が頻発している。この汚染が発生すると、モデルは未知の課題を解く「汎化」ではなく、単に学習時のデータを思い出す「暗記」によって高いスコアを出してしまい、真の能力が隠蔽されてしまう。 特に多言語設定においては、この問題はさらに複雑化する。多言語モデルは複数の言語を同時に扱うため、ある言語での汚染が、モデルが直接学習していないはずの他の言語にまで波及する可能性がある。例えば、英語からフランス語への翻訳データを学習した際に、そのターゲット側であるフランス語の文章を暗記してしまうと、中国語からフランス語への翻訳といった、学習していないはずの方向でも暗記した文章を出力してスコアが不当に高くなる現象が懸念される。 本研究が焦点を当てるFLORES-200は、数百の言語をカバーし、すべての言語間で文が対応している「多方向並列」という構造を持つ。…
核心:何を提案したのか
本研究は、機械翻訳を診断タスクとして利用し、ターゲット言語が共通する学習済みの翻訳方向から、未学習の翻訳方向へとスコアの上昇が波及する「方向間汚染(cross-direction contamination)」という概念を提唱し、その実態を調査した。具体的には、FLORES-200ベンチマークを学習データに含んでいることが公表されている「Bloomz-7B1」と、クリーンな対照群としての「Llama-3.1-8B-Instruct」を用い、両者の挙動を詳細に比較分析した。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related