フィッシングURL検出のためのLeast-to-Most推論の抽出
フィッシングURL検出において、複雑な問題を段階的なサブ問題に分解して解く「Least-to-Most」プロンプティングと、確信度を数値化して推論を制御する独自の「回答感度」メカニズムを組み合わせた新しいフレームワークを提案した。
TL;DR(結論)
フィッシングURL検出において、複雑な問題を段階的なサブ問題に分解して解く「Least-to-Most」プロンプティングと、確信度を数値化して推論を制御する独自の「回答感度」メカニズムを組み合わせた新しいフレームワークを提案した。 この手法は、URLの構造を詳細に分析するプロセスを反復的に実行することで、従来のワンショット手法を上回る精度を達成し、特に初期段階で誤判定されたURLを論理的な推論を通じて正解へと導く自己修正能力を実証した。 検証の結果、Gemini 2.5-Flash等の最新モデルにおいて、大量のラベル付きデータを必要とする専用の教師あり学習モデルであるURLTranに肉薄する高い検出性能を確認し、セキュリティ分野における大規模言語モデルの解釈性と実用性の両立を証明した。
なぜこの問題か
フィッシング攻撃は、現代のサイバーセキュリティにおける最も一般的かつ深刻な脅威の一つであり、多くの重大なデータ漏洩事件における主要な侵入口として機能し続けている。これに対抗するため、従来はブラックリスト方式や機械学習、深層学習を用いた様々な検出手法が開発されてきた。しかし、Google Safe BrowsingやPhishTankに代表されるブラックリスト方式は、攻撃者が次々と生成する新しいURL、いわゆるゼロデイ攻撃に対して更新速度が追いつかず、急速に変化する脅威を食い止めるには限界がある。一方で、URLの文字列のみを解析するURLTranのような最新の深層学習モデルは非常に高い精度を誇るが、なぜそのURLが有害であると判断されたのかという根拠を人間に理解できる形で示す「解釈性」に欠けているという課題があった。 近年、大規模言語モデル(LLM)がその高度な推論能力を活かし、フィッシング検出の分野でも有望な結果を残し始めている。…
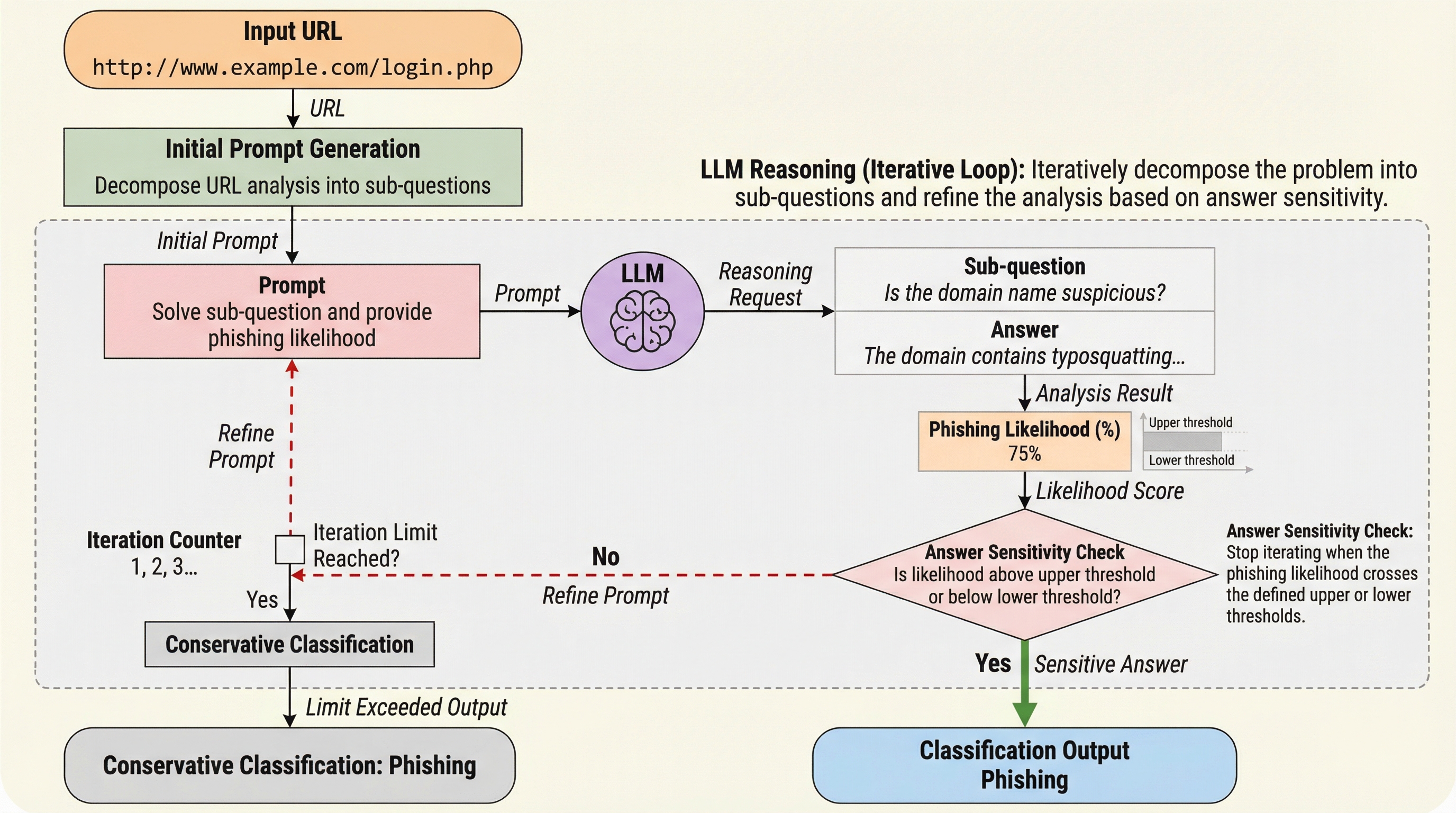
核心:何を提案したのか
本研究の核心は、フィッシングURL検出に「Least-to-Most」プロンプティングという手法を適用し、さらに独自の「回答感度(answer sensitivity)」メカニズムを導入して推論を制御する枠組みを提案した点にある。Least-to-Mostプロンプティングとは、複雑な問題を一度に解こうとするのではなく、まず解決に必要な小さなサブ問題を生成し、それを一つずつ順番に解いていくことで最終的な結論を導き出す手法である。本研究では、この手法をURL解析に特化させ、LLMに対して「このURLがフィッシングかどうかを判断するために必要なサブ問題を一つ作成し、それだけに答えなさい」と指示する。これにより、モデルはURLの構成要素であるドメイン、ディレクトリ、ファイル名などを一つずつ詳細に吟味することを強制される。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related