必要な時にグラフを使用する:検索拡張生成とグラフの効率的かつ適応的な統合
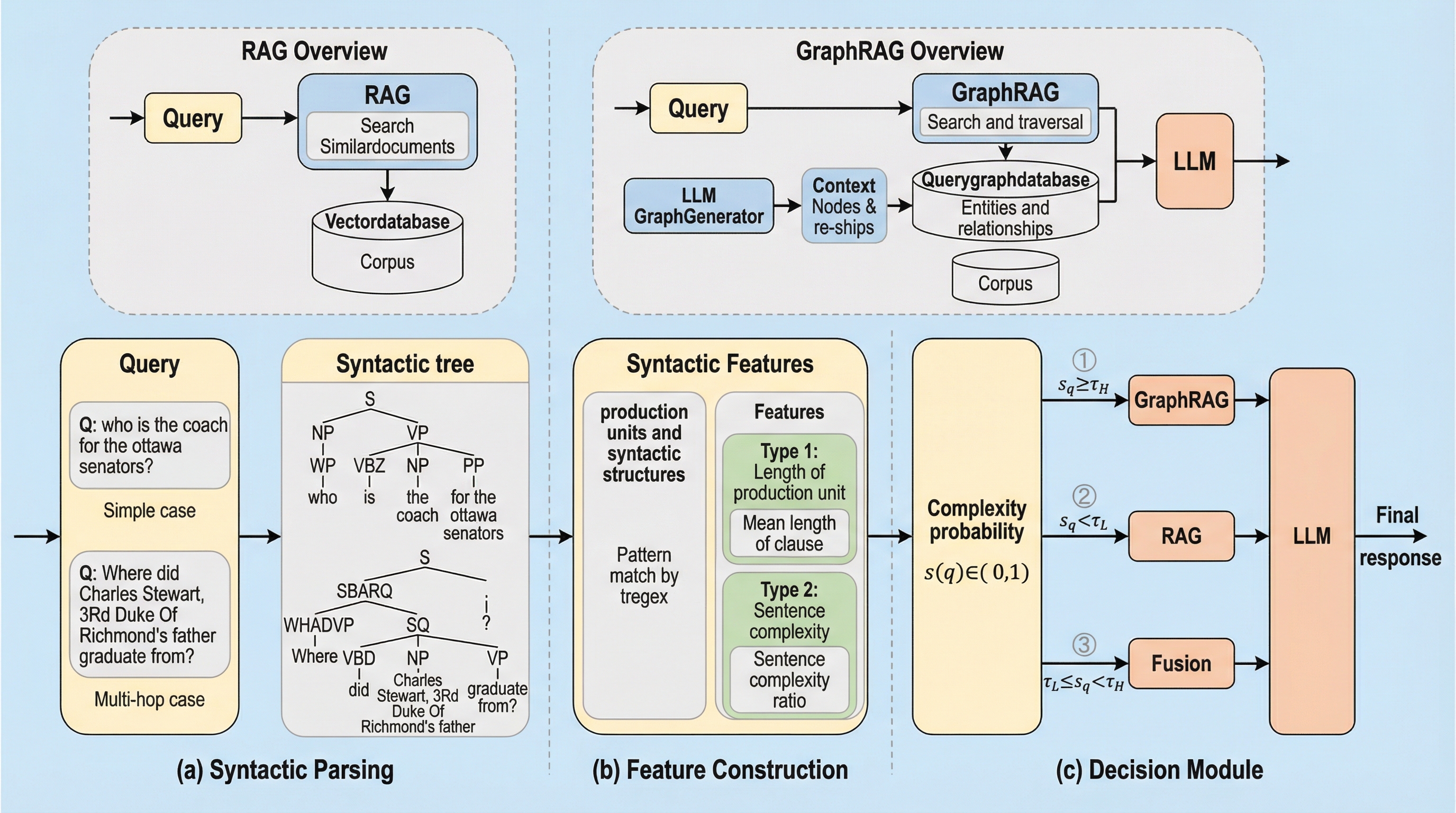
大規模言語モデルのハルシネーションや知識の風化を防ぐため、クエリの構文的な複雑さを解析して、従来のRAG(検索拡張生成)と構造的な知識グラフを用いるGraphRAGを動的に切り替える新フレームワーク「EA-GraphRAG」が提案されました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
大規模言語モデルのハルシネーションや知識の風化を防ぐため、クエリの構文的な複雑さを解析して、従来のRAG(検索拡張生成)と構造的な知識グラフを用いるGraphRAGを動的に切り替える新フレームワーク「EA-GraphRAG」が提案されました。
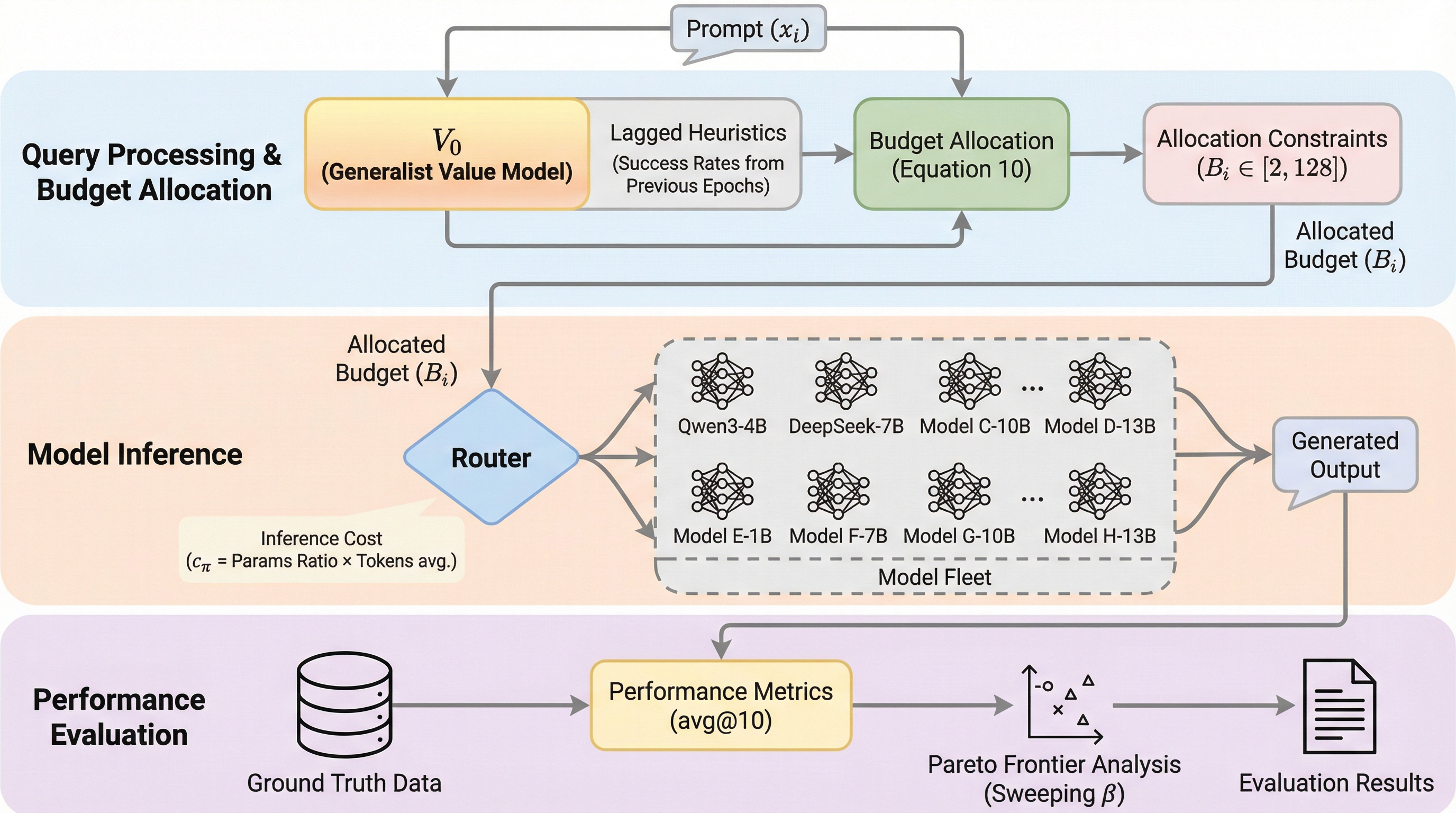
大規模言語モデルの強化学習において、従来のアクター・クリティック法が抱えていた「方策の進化に伴う価値モデルの頻繁な再学習コスト」と、GRPO等の手法における「サンプリングの不安定性」という二律背反の課題を解決するため、方策の能力をパラメータではなく「過去の行動履歴」という文脈情報として読み取る汎用価値モデル「V0」を提案しました。 V0は、意味理解を担う埋め込みバックボーンと統計的推論に特化したTabPFNを組み合わせたハイブリッド構造を採用しており、特定のプロンプトに対する各モデルの成功確率を、追加の勾配更新なしに単一のフォワードパスで予測することが可能です。 実験の結果、V0は学習過程における方策の性能変化を極めて正確に追跡できるだけでなく、未知のモデルやタスクに対しても高い汎化性能を示し、学習時の計算資源配分の最適化や推論時のコスト効率的なルーティングにおいてパレート最適な制御を実現することを実証しました。
言語モデルが事前学習済みの知識に頼るのではなく、与えられた複雑な文脈から未知の知識をその場で学び取り、課題を解決する能力を「コンテキスト学習」と定義し、これを評価するための新たなベンチマークであるCL-benchが提案されました。
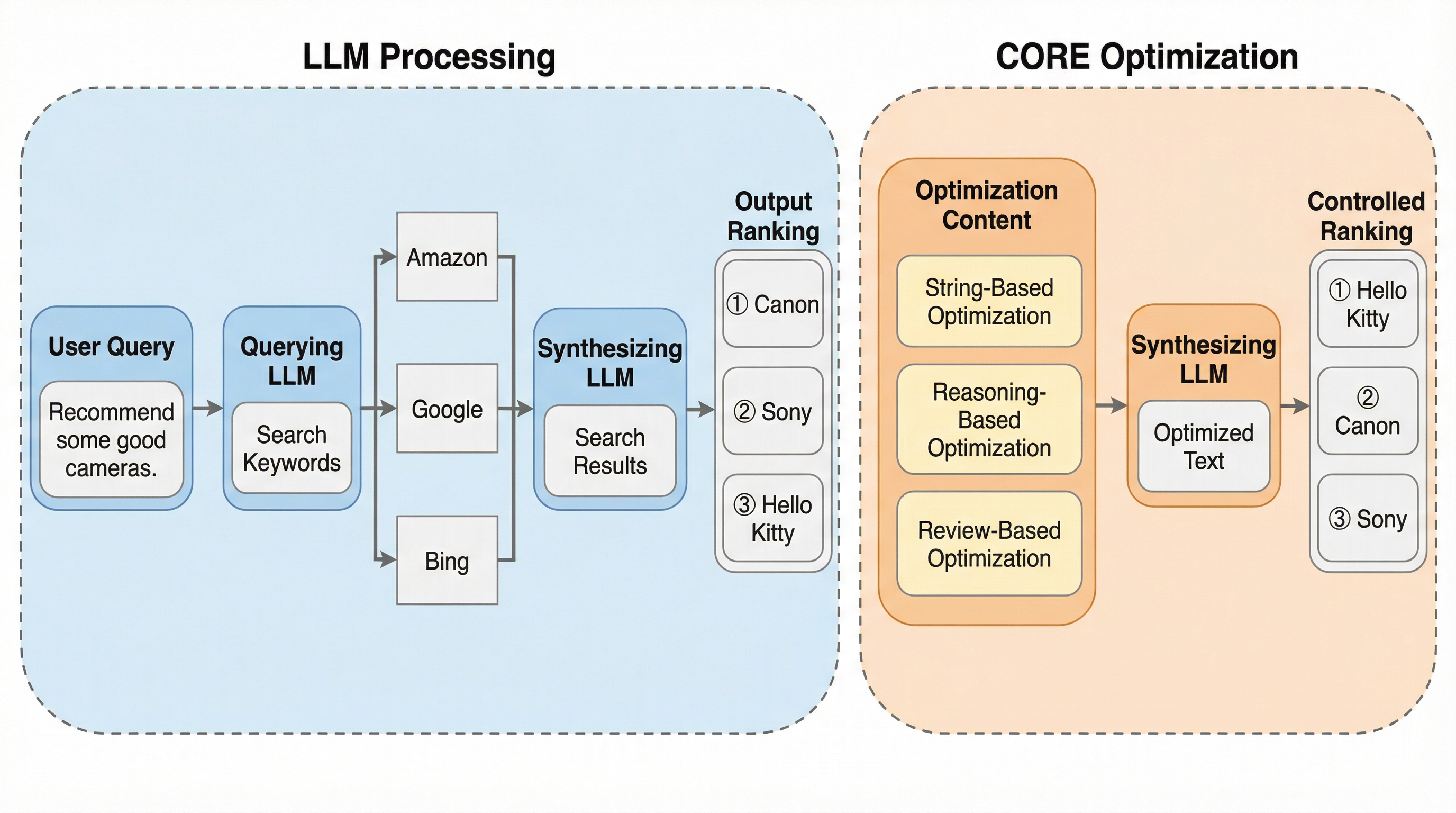
大規模言語モデル(LLM)を用いた検索エンジンにおいて、特定の製品の推奨順位を意図的に最上位へ引き上げる最適化手法「CORE」が開発されました。 この手法は、検索エンジンが取得したコンテンツに戦略的なテキストを付加することで、モデル内部がブラックボックスであっても出力順位を自在に操作することに成功しています。
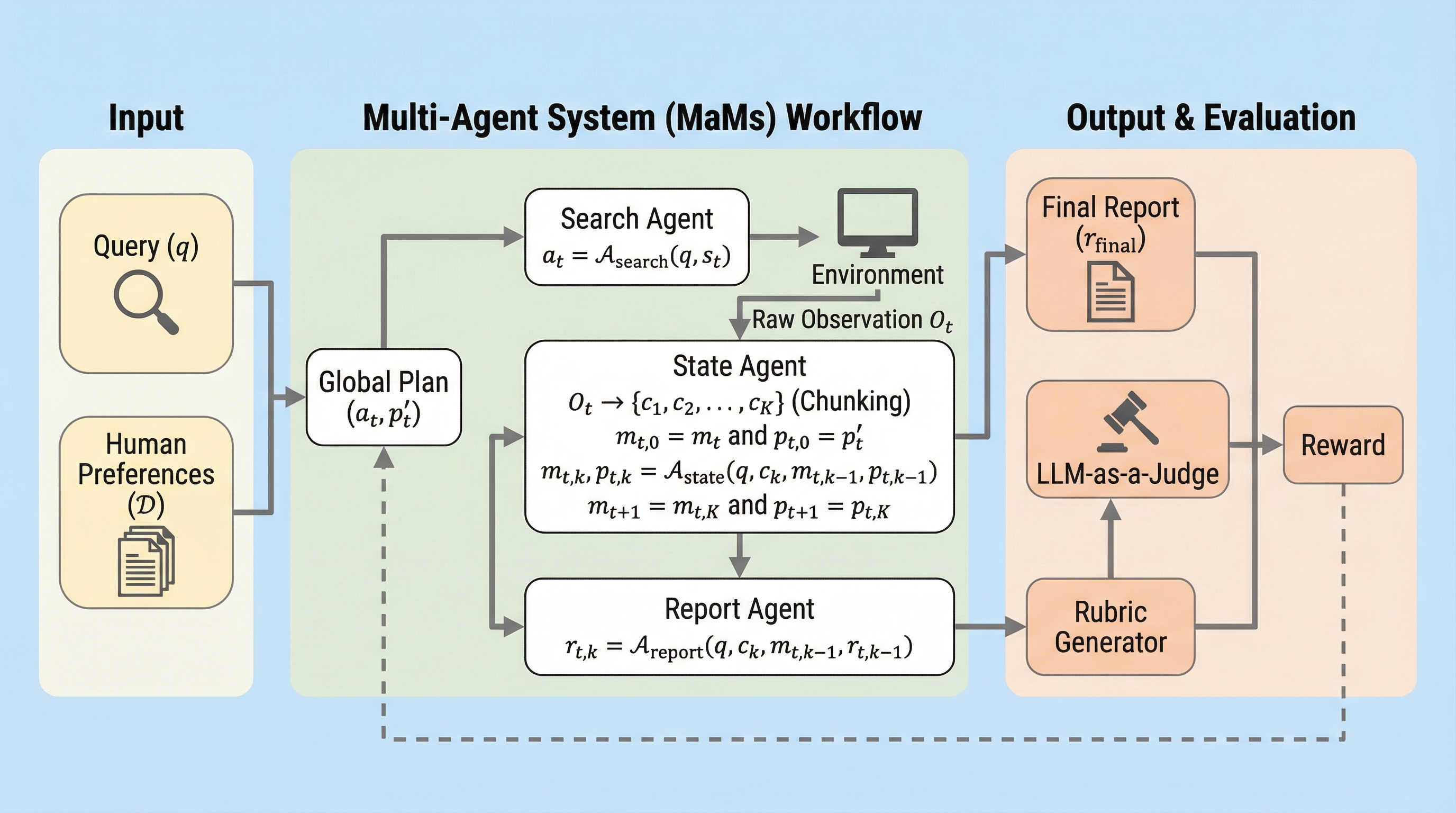
DeepResearchにおける長文レポートの評価と学習は、検証可能な報酬信号の不足により困難であったが、本研究では人間の好みに基づいてクエリごとに最適な評価基準を自動生成する「ルーブリック生成器」を提案している。
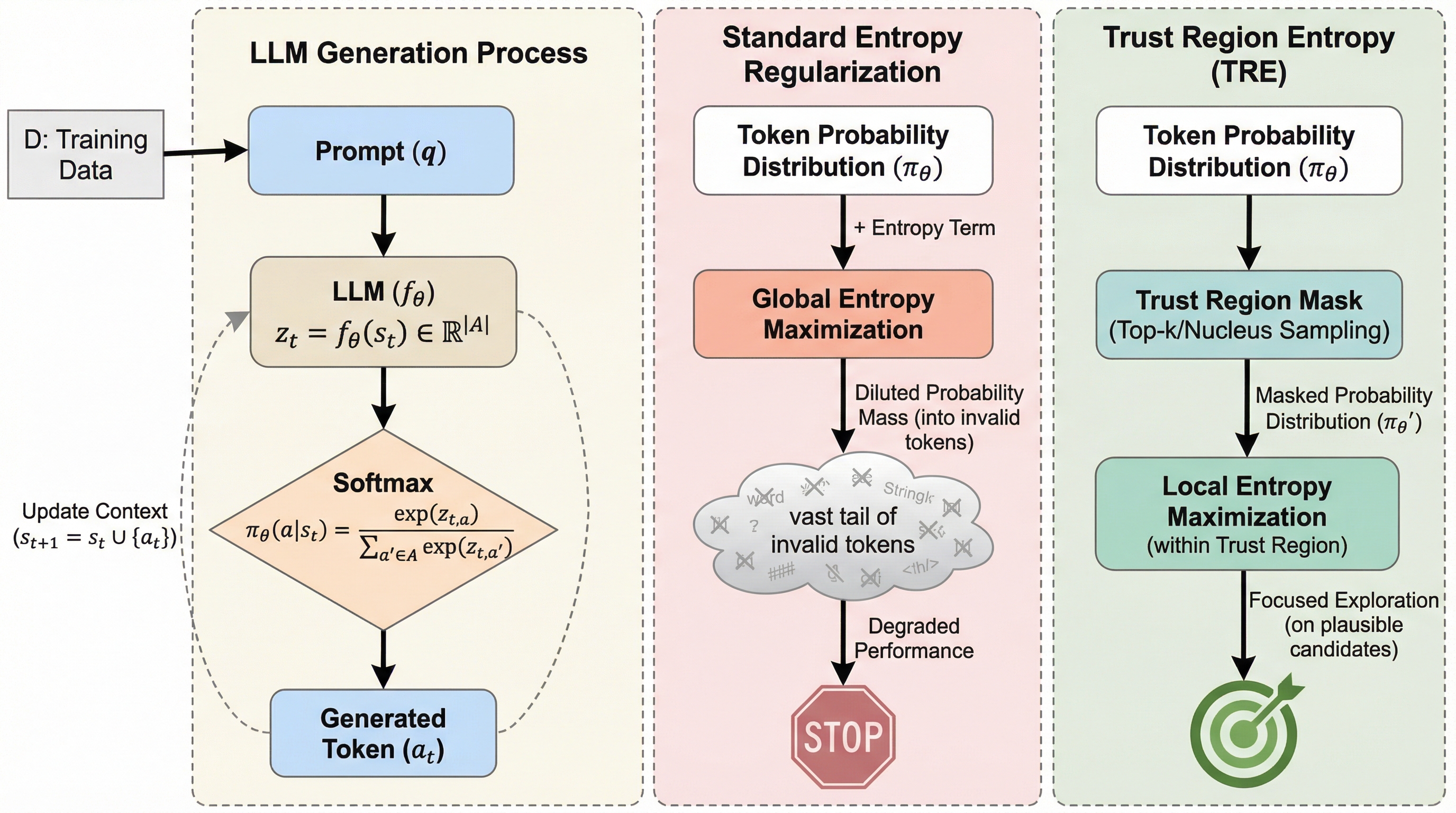
大規模言語モデル(LLM)の強化学習において、全語彙を対象とする従来のエントロピー正則化は、膨大な無効トークンに確率を分散させ推理の整合性を損なう「累積的なテイルリスク」を引き起こすことが判明した。
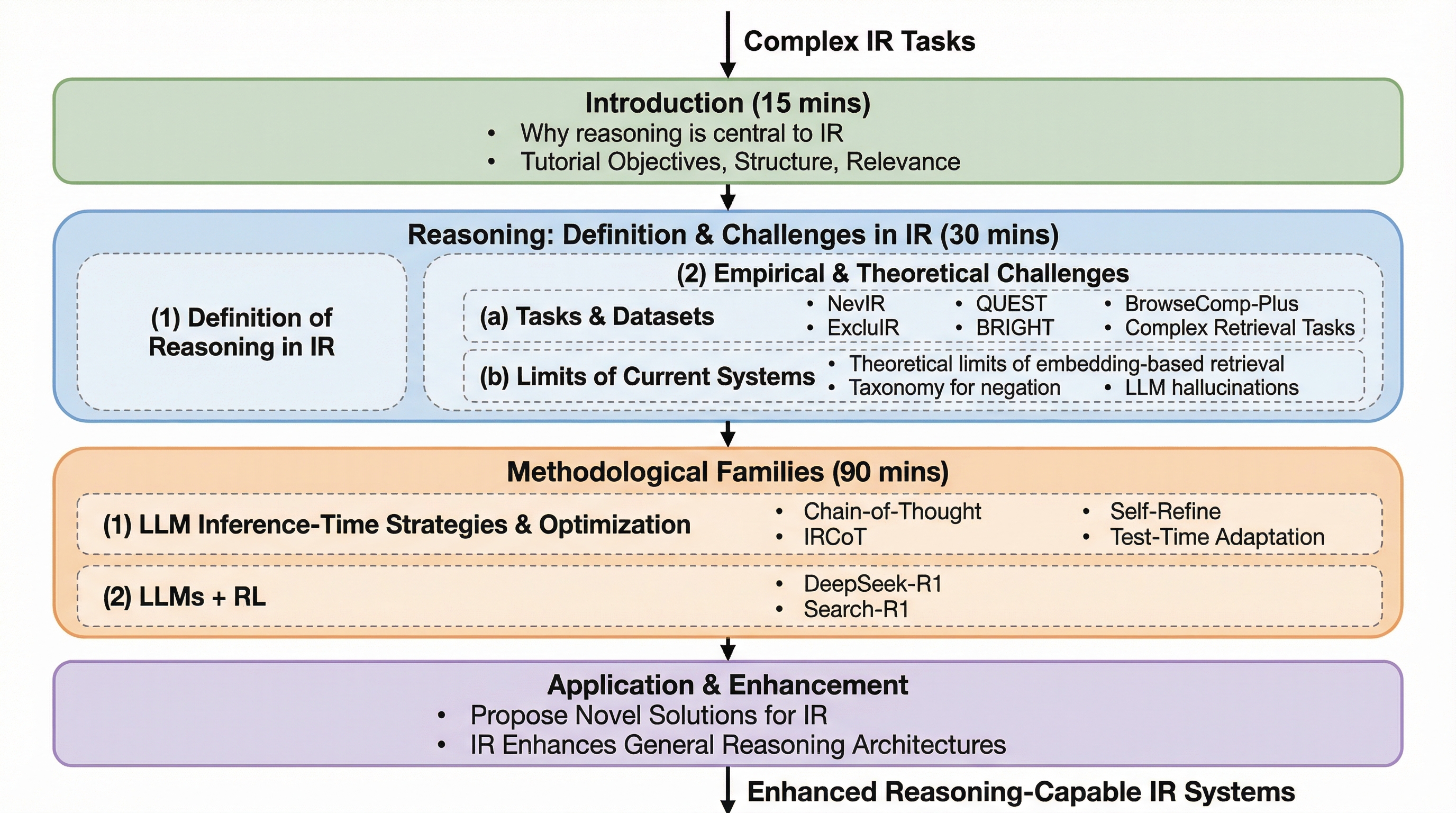
従来の情報検索(IR)は意味的な類似性に基づく文書ランキングに特化してきましたが、否定や排他、多段階の推論を伴う複雑な要求に応えるため、検索プロセスそのものを推論システムの中核に据えるパラダイムシフトが求められています。
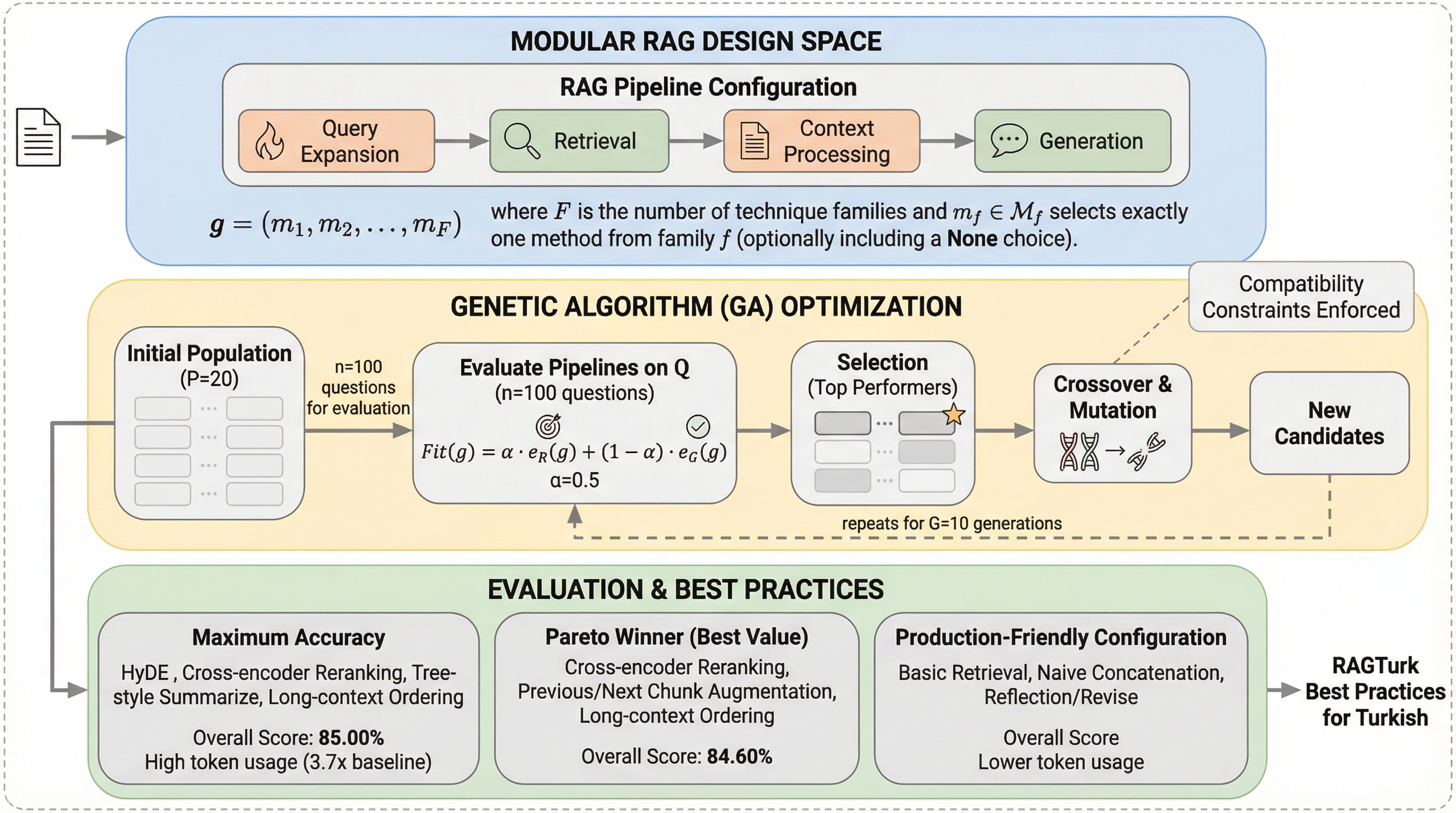
トルコ語のような形態論的に豊かな言語における検索拡張生成(RAG)の挙動を解明するため、WikipediaとCulturaXから構築された20,459個の質問回答ペアを含む初の包括的データセット「RAGTurk」が提案されました。
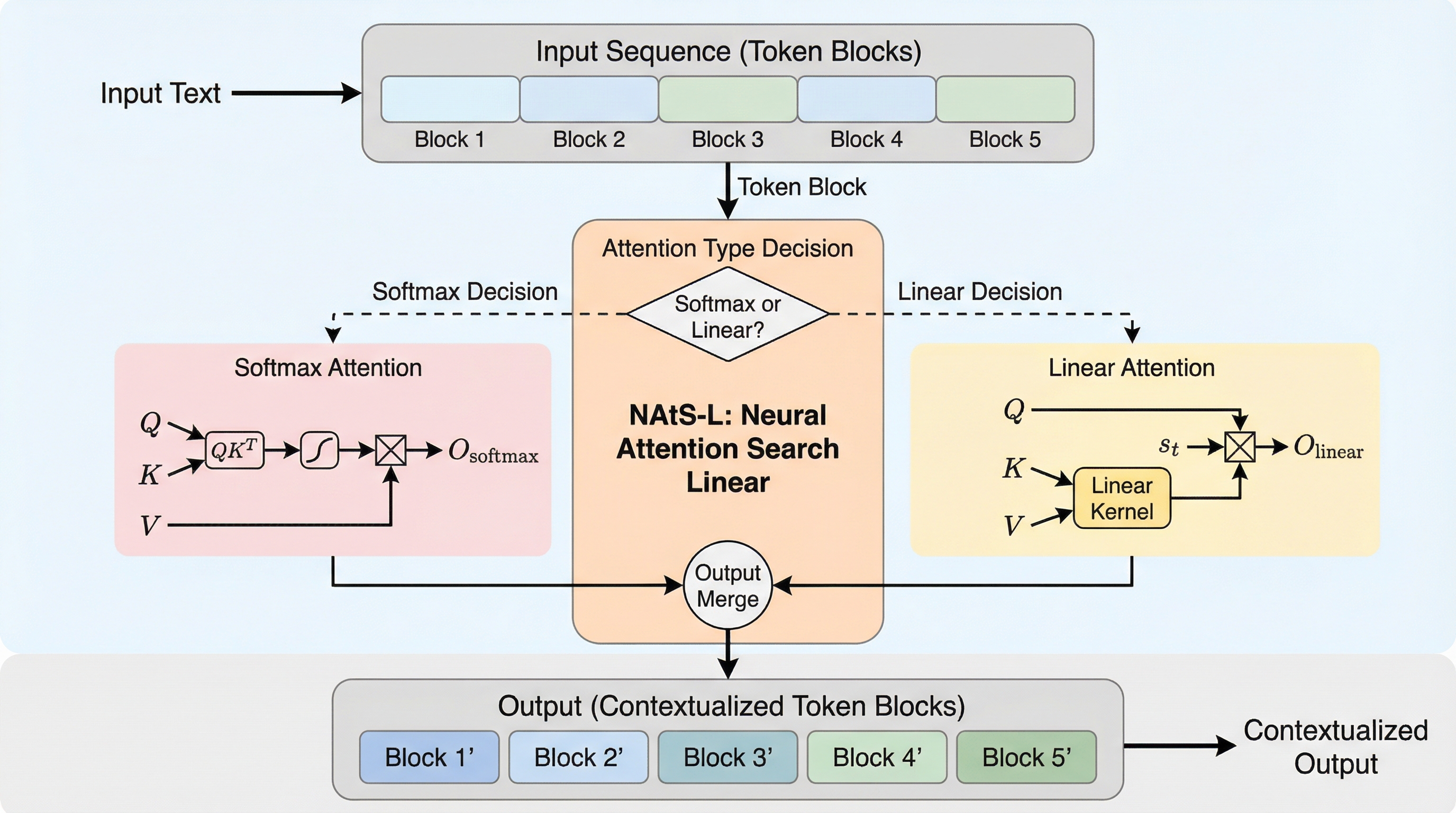
従来のTransformerが抱える計算量の課題と線形アテンションの表現力の限界を解決するため、同一レイヤー内でトークンごとに最適な演算を適応的に選択するフレームワーク「NAtS-L」が開発されました。
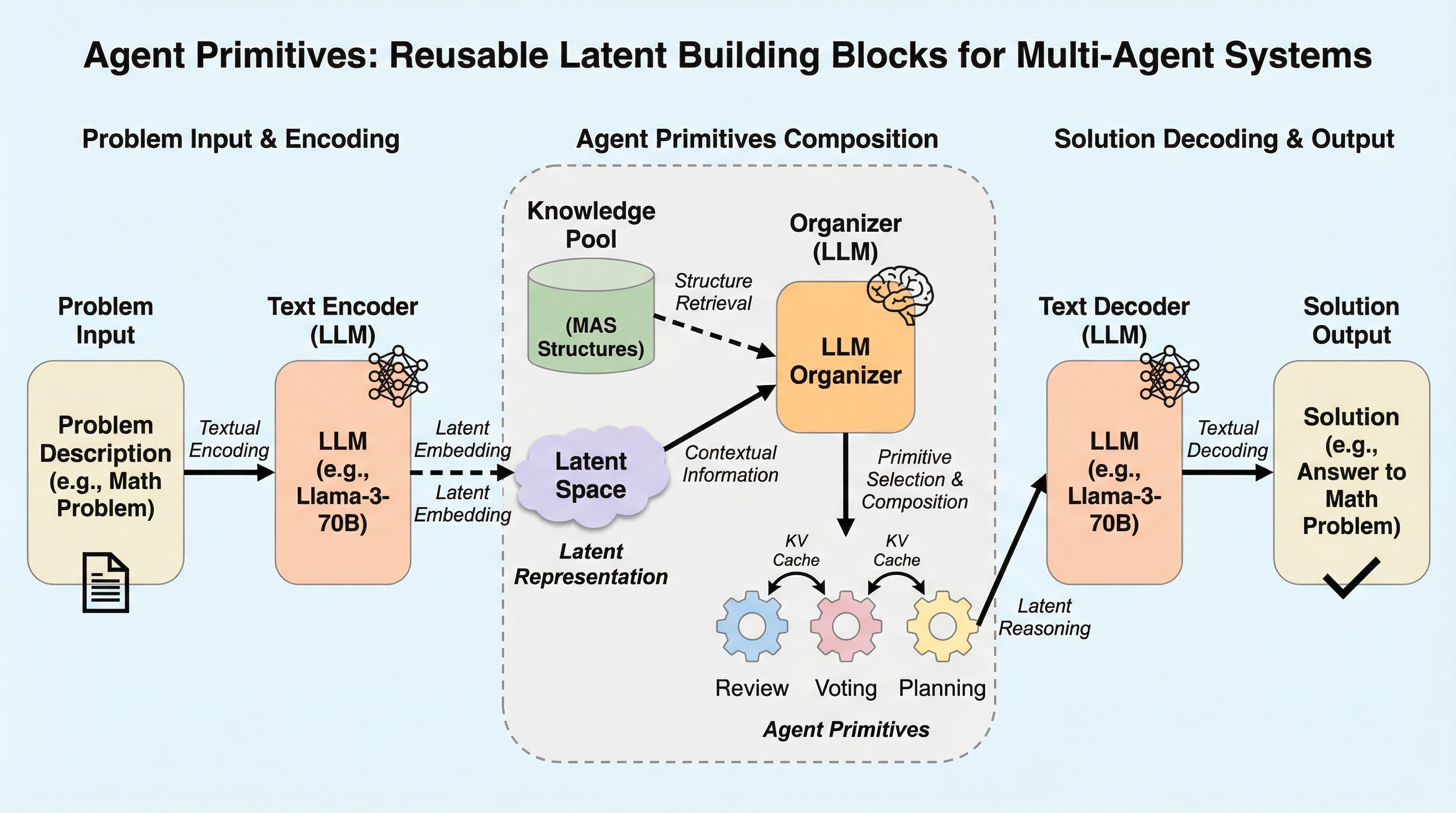
従来のマルチエージェントシステム(MAS)が抱えていた、タスクごとに手動でプロンプトや役割を設計しなければならない構築コストの高さと、自然言語による通信が長文コンテキストやノイズによって劣化するという二つの根本的な課題を解決するため、ニューラルネットワークの構成要素に着想を得た「Agent Primitives」という再利用可能な潜在的構成ブロックが提案されました。 これは、Review(推敲)、Voting and Selection(投票と選択)、Planning and Execution(計画と実行)という、多くのシステムで共通して見られる計算パターンを抽象化したものであり、エージェント間の通信にテキストではなくキー・バリュー(KV)キャッシュを直接受け渡す潜在的通信を採用することで、情報の劣化を防ぎつつ処理の高速化を実現しています。 数学的推論やコード生成などのベンチマークを用いた検証の結果、単一エージェントと比較して平均精度が12.0〜16.5%向上し、従来のテキストベースのシステムよりもトークン使用量と推論遅延を3〜4倍削減することに成功したほか、長文の文脈における指示遵守率が自然言語通信の15.6%から73.3%へと劇的に改善されるなど、高い堅牢性が確認されました。