情報検索のための推論と推論のための情報検索に関するチュートリアル
従来の情報検索(IR)は意味的な類似性に基づく文書ランキングに特化してきましたが、否定や排他、多段階の推論を伴う複雑な要求に応えるため、検索プロセスそのものを推論システムの中核に据えるパラダイムシフトが求められています。
TL;DR(結論)
従来の情報検索(IR)は意味的な類似性に基づく文書ランキングに特化してきましたが、否定や排他、多段階の推論を伴う複雑な要求に応えるため、検索プロセスそのものを推論システムの中核に据えるパラダイムシフトが求められています。本研究は、大規模言語モデル(LLM)の推論戦略、神経記号的手法、確率的枠組み、幾何学的表現といった多角的なアプローチを統合し、表現の妥当性・推論メカニズム・計算の実行可能性という3つの軸で整理した統一的な分析フレームワークを提案しています。このフレームワークを通じて、既存の検索システムの限界を理論的・実証的に明らかにし、検索技術が単なるデータ取得手段ではなく、検証可能で構造化された推論を実現するための不可欠な基盤として機能する未来のロードマップを提示しています。
なぜこの問題か
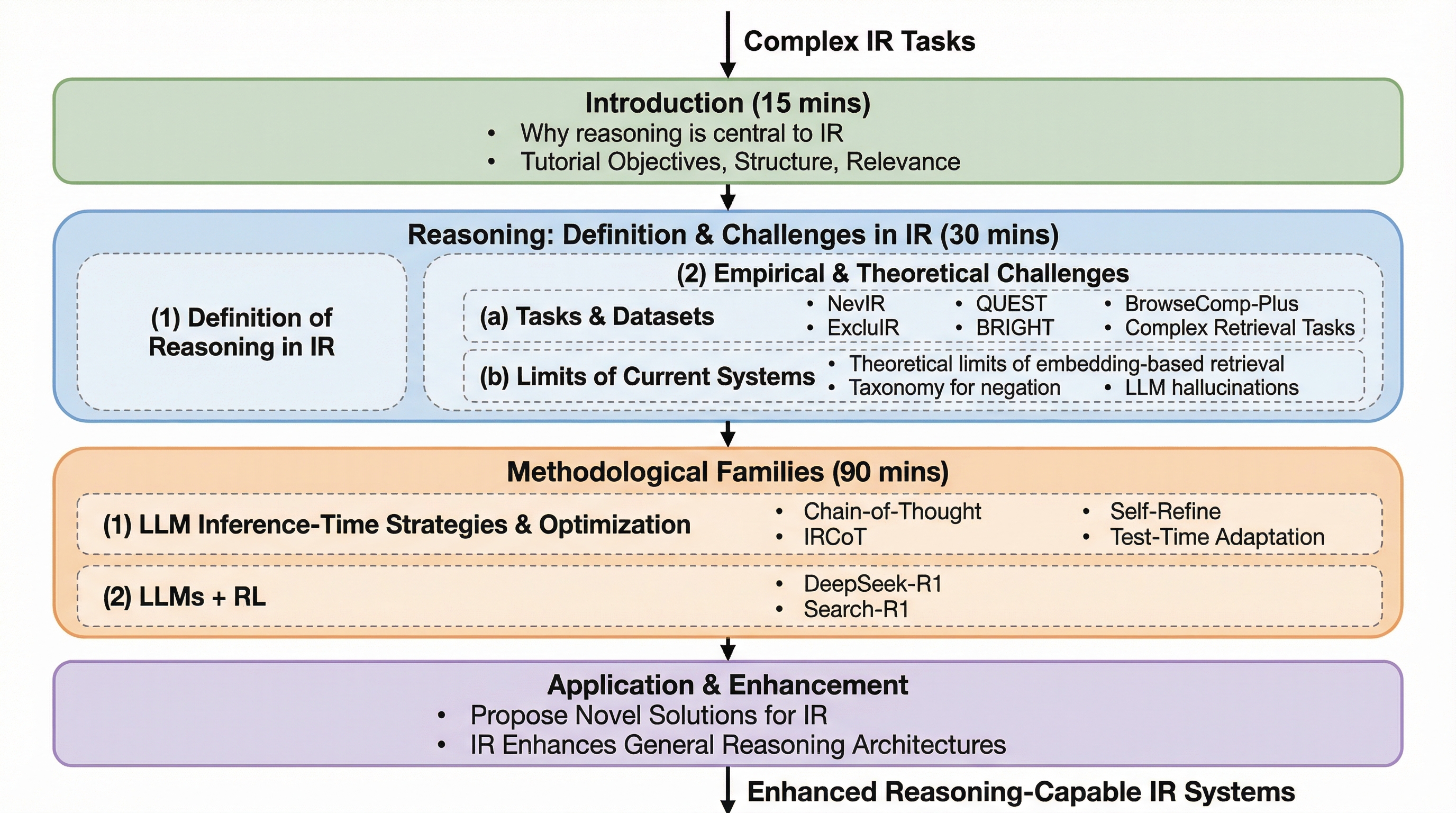
現代の情報検索システムは、密ベクトル表現や生成モデルの発展により、クエリと文書の意味的なマッチングにおいて優れた成果を上げてきました。しかし、現実世界のユーザーが抱える情報ニーズは、単なる類似性の判断をはるかに超える複雑な論理構造を含んでいます。例えば、「特定の条件を除外する(排他)」、「否定的な制約を遵守する」、「複数の情報源から証拠を合成する」、「多段階の推論を経て結論を導き出す」といったタスクにおいて、現在のニューラル検索モデルは依然として明確な弱点を露呈しています。実証的な側面では、NevIRやExcluIR、QUEST、BRIGHT、BrowseComp-Plusといった最新のベンチマークにおいて、現在の検索システムが論理的な制約を正しく処理できないことが示されています。 また、理論的な研究(Wellerら)によれば、埋め込みベースの検索手法には本質的な表現上の限界が存在し、これは単にモデルの規模やデータ量を拡大するだけでは解決できない可能性が指摘されています。…
核心:何を提案したのか
本研究は、情報検索(IR)における推論の定義を明確化し、多様な推論手法を体系的に整理するための「統一的分析フレームワーク」を提案しています。このフレームワークは、単に既存の手法を羅列するのではなく、以下の3つの主要な評価軸(Axes)に基づいて、各手法の特性とトレードオフを明らかにすることを目的としています。 第一の軸は「表現の妥当性(Representational adequacy)」です。これは、検索対象やクエリの表現空間が、論理構造や階層関係、あるいは述語に関する不確実性をどの程度正確にエンコードできるかを評価するものです。第二の軸は「推論と学習のメカニズム(Mechanisms of inference and learning)」であり、表現空間上でどのように推論が実行され、モデルの更新が行われるのか、またその推論過程がどのように検証されるのかに焦点を当てます。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related