TRE: 信頼領域内での探索を促進する手法の提案
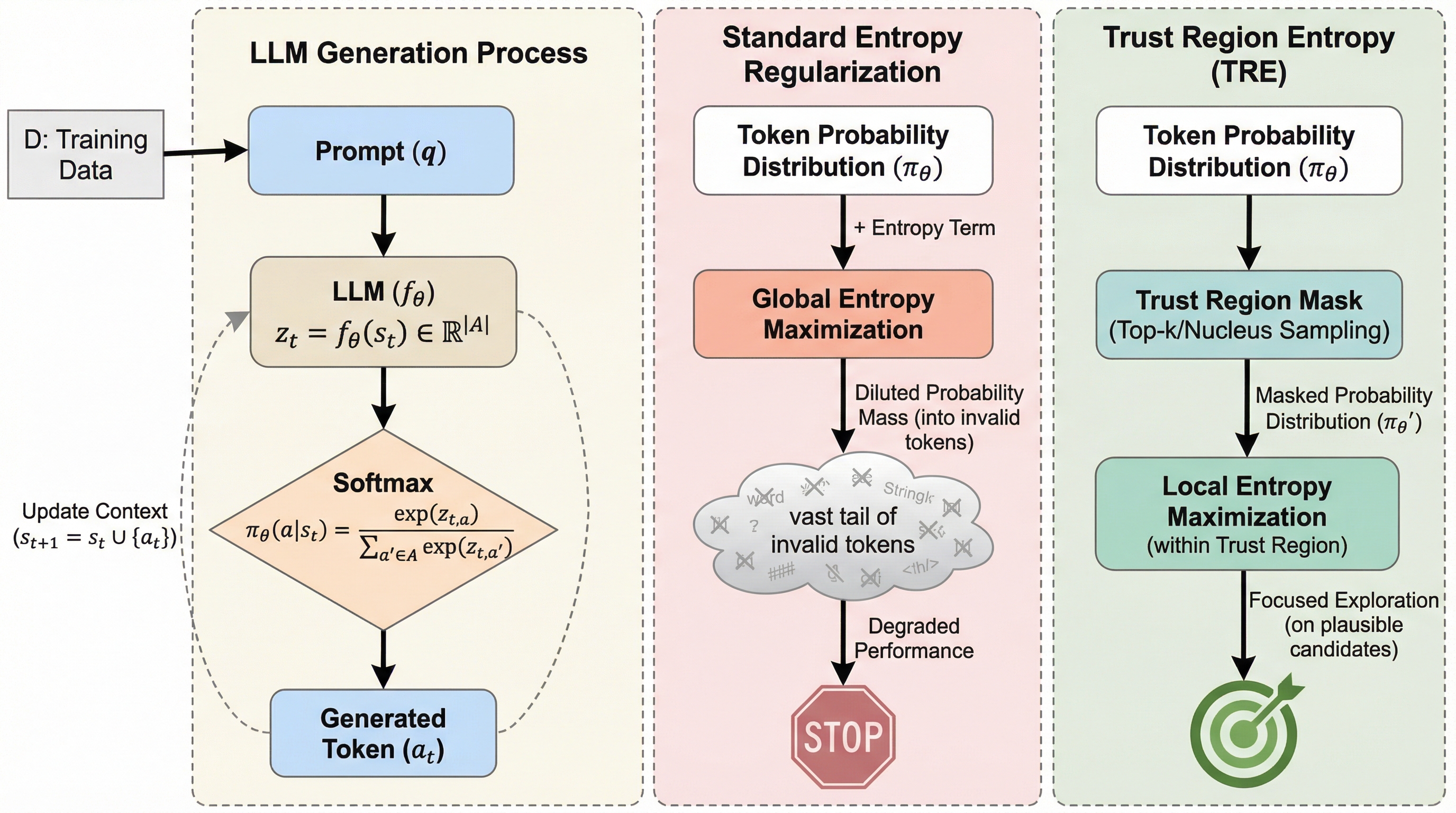
大規模言語モデル(LLM)の強化学習において、全語彙を対象とする従来のエントロピー正則化は、膨大な無効トークンに確率を分散させ推理の整合性を損なう「累積的なテイルリスク」を引き起こすことが判明した。
TL;DR(結論)
大規模言語モデル(LLM)の強化学習において、全語彙を対象とする従来のエントロピー正則化は、膨大な無効トークンに確率を分散させ推理の整合性を損なう「累積的なテイルリスク」を引き起こすことが判明した。 本研究が提案する「信頼領域エントロピー(TRE)」は、モデルが妥当と判断した上位候補(信頼領域)内でのみ探索を促すことで、構文的・論理的な破綻を防ぎつつ、数学的推論や嗜好アラインメントにおいて高い性能を実現する。 実験の結果、TREは標準的なPPOや既存の探索手法を一貫して上回り、特に生成長が長くなるほど推論能力が崩壊する従来手法の欠点を克服し、長文の思考プロセスを維持する上で極めて有効であることが示された。
なぜこの問題か
大規模言語モデル(LLM)を人間の意図に合わせ、複雑な推論能力を向上させるために、強化学習(RL)は不可欠な手法となっている。数学的な導出の正しさを最適化する場合でも、助けになる回答を生成する場合でも、方策空間を効率的に探索することが中心的な課題である。ロボット工学やグリッドワールドのような古典的な強化学習の領域では、エントロピー正則化が標準的な手法として用いられてきた。これは決定論的な方策に罰則を与え、エージェントが多様な行動をサンプリングするように促すものである。しかし、LLMに対してこの手法を直接適用しても、利益は限定的であり、むしろ性能を低下させることが近年の研究で指摘されている。 本論文では、この失敗の原因が「有効な多様体の希薄さ」と「長期間の生成における累積的なリスク」の相互作用にあると分析している。古典的な環境では行動空間が低次元(例えば10程度)であり、ランダムな探索を行っても有効な状態空間に留まることが多い。対照的に、LLMは約150,000という膨大な語彙を扱っており、構文的な一貫性や論理的な連続性を維持できる有効なトークンは、その中の極めて希薄な多様体を構成している。…
核心:何を提案したのか
本研究では、言語生成の希薄な性質に特化して設計された新しい正則化フレームワークである「信頼領域エントロピー(Trust Region Entropy, TRE)」を提案している。この手法の根底にある直感は、有効な探索は「信頼領域」、すなわち事前学習済みモデルが妥当であると見なすトークンのサブセット内に厳密に制限されるべきであるという考え方である。分布全体を平坦化するのではなく、この高信頼サブセット内でのみエントロピーを最大化することで、モデルの推論能力を損なうことなく多様な探索を実現する。 TREは、強化学習における安定した最適化の基礎概念である「信頼領域」の考え方を、訓練時の探索目的に適応させたものである。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related