DeepResearchレポート生成のための人間の嗜好からのクエリ固有のルーブリックの学習
DeepResearchにおける長文レポートの評価と学習は、検証可能な報酬信号の不足により困難であったが、本研究では人間の好みに基づいてクエリごとに最適な評価基準を自動生成する「ルーブリック生成器」を提案している。
TL;DR(結論)
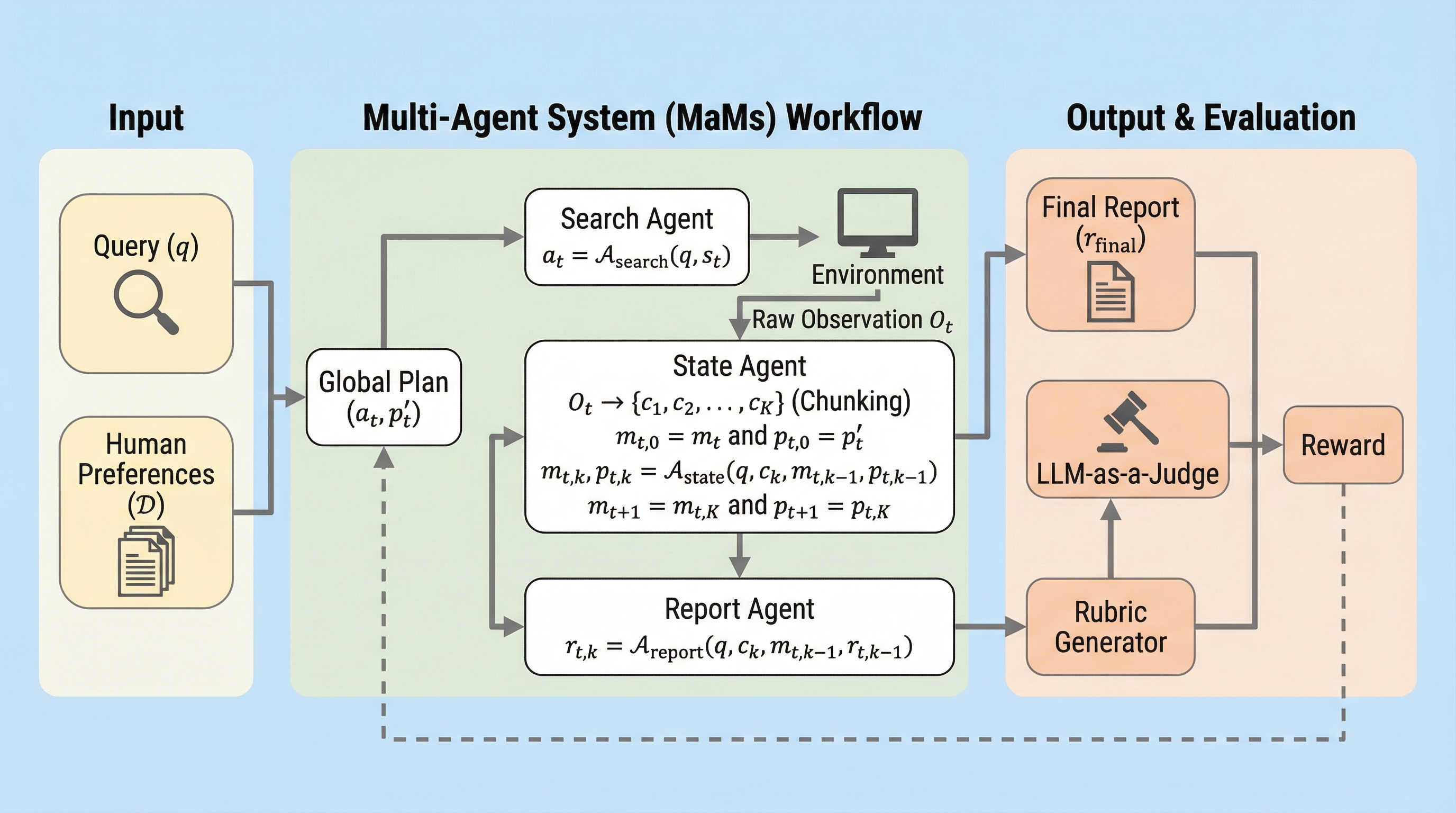
DeepResearchにおける長文レポートの評価と学習は、検証可能な報酬信号の不足により困難であったが、本研究では人間の好みに基づいてクエリごとに最適な評価基準を自動生成する「ルーブリック生成器」を提案している。 この生成器は5,000件以上のクエリと人間の選好データを用いた強化学習(GRPO)によって構築され、既存の汎用的な基準よりも人間に近い判断を可能にするとともに、長期的な推論を支える「マルチエージェント・マルコフ状態(MaMs)」ワークフローを導入した。 検証の結果、提案手法を用いたシステムはオープンソースの主要な基準をすべて上回り、商用の最先端モデルに匹敵する性能を達成しており、スケーラブルで人間に整合した調査レポート生成の新たな道を切り拓いている。
なぜこの問題か
大規模言語モデル(LLM)の急速な進歩により、膨大な文書群から証拠を合成し、複雑なクエリに対して構造化された長文レポートを作成するDeepResearchシステムが登場している。しかし、これらのシステムを効果的に訓練し、その出力を正確に評価することは、現在のAI研究における極めて困難な課題の一つである。短文の回答を求めるタスク(GAIAやBrowseCompなど)とは異なり、長文の調査レポートには唯一の「正解」が存在せず、数学の問題のように客観的に検証可能な報酬信号を得ることができないためである。人間による直接的な評価は最も信頼性が高いものの、膨大な学習データに対して適用するにはコストと時間の面で限界があり、スケーラビリティに欠けるという問題がある。 この課題を解決するために、評価基準(ルーブリック)を用いた自動評価が一般的に行われているが、既存の手法には二つの大きな欠点がある。第一に、あらかじめ定義された汎用的なルーブリックは、個別の調査クエリが持つ固有の要求事項や質の微妙な違いを識別するには粒度が粗すぎるという点である。…
核心:何を提案したのか
本研究の核心は、人間の好みに整合したクエリ特化型のルーブリック生成器を訓練するための包括的なパイプラインを提案したことにある。まず、5,000件を超えるDeepResearchスタイルのクエリに対して、複数のレポート候補を提示し、どちらが優れているかを人間が判定した大規模な選好データセットを構築した。このデータセットを基盤として、ルーブリック生成器を「グループ相対方策最適化(GRPO)」と呼ばれる強化学習手法を用いて訓練する。この訓練プロセスでは、単に基準を生成するだけでなく、生成された基準が「人間の好みを正しく反映しているか」を評価するハイブリッドな報酬システムを導入している。 具体的には、生成されたルーブリックを用いてレポートを採点した際、人間が選んだ優れたレポートに高い点数が与えられるかどうかを判定する「選好整合性報酬」を核としている。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related