複数回の更新を伴う一般化された知識編集のための競合解消およびシャープネスを考慮した最小化
大規模言語モデルの内部知識を効率的に更新する手法として、モデル編集やLoRAなどのパラメータ効率的な微調整が検討されてきましたが、入力形式の変化への弱さや複数回の更新における不安定さ、そして古い知識との衝突が実用上の大きな課題となっていました。
TL;DR(結論)
大規模言語モデルの内部知識を効率的に更新する手法として、モデル編集やLoRAなどのパラメータ効率的な微調整が検討されてきましたが、入力形式の変化への弱さや複数回の更新における不安定さ、そして古い知識との衝突が実用上の大きな課題となっていました。 本研究で提案されたCoRSAは、損失曲面の平坦化を行うSAMと、新旧知識の差を最大化するDPO、さらに勾配の衝突を防ぐPCGradを組み合わせることで、多様な表現への汎化性能を高めつつ、連続的な知識更新における安定性を大幅に向上させることに成功しました。 検証の結果、事実情報の編集ベンチマークにおいてLoRAを12.42%上回る汎化性能を達成し、忘却を27.82%抑制したほか、コード領域でも高い更新効率を示しており、既存手法の限界を打破する実用的な知識管理フレームワークとしての有効性が確認されています。
なぜこの問題か
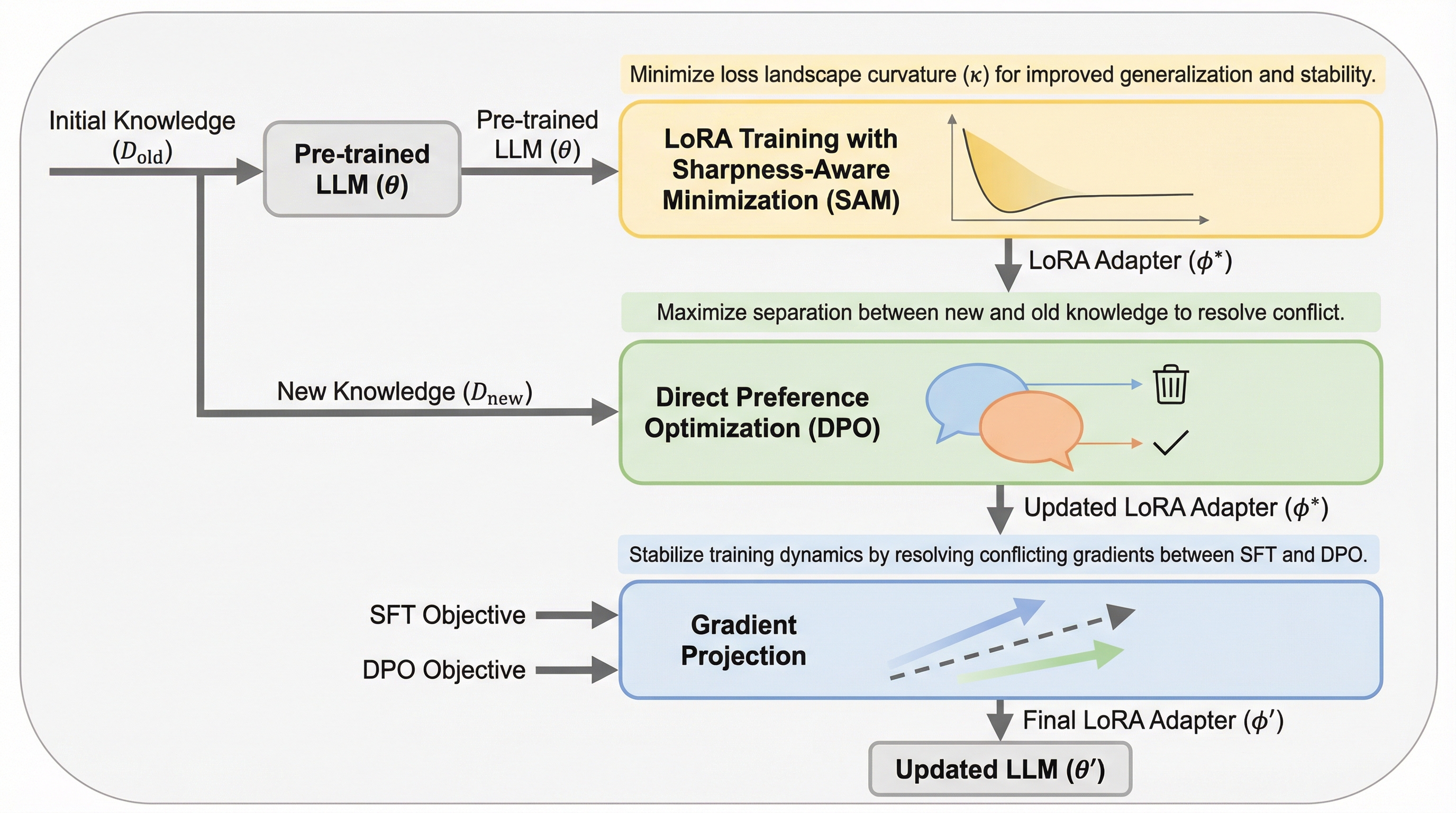
大規模言語モデル(LLM)は、下流タスクを解決するために内部に保持された知識に大きく依存していますが、現実世界の情報は常に変化するため、モデルを最新の状態に保つことが不可欠な課題となっています。しかし、モデル全体を再学習させる手法は計算コストが極めて高く、実用的ではないため、より効率的な代替案としてモデル編集やパラメータ効率的な微調整(PEFT)が注目されてきました。 既存の手法には主に3つの大きな限界が存在することが指摘されています。第一に、入力形式に対する汎化性能の不足です。LLMは多様な入力形式を処理する必要がありますが、特定の例で知識を更新しても、言い換えられた質問や異なる文脈では更新された知識が反映されないことが多くあります。第二に、複数回の更新に対する安定性の欠如です。知識は時間の経過とともに進化するため、モデルは重複する事実や振る舞いを繰り返し修正する必要がありますが、既存手法では過去の更新が損なわれたり、モデル全体の能力が低下したりする問題が発生します。 第三の課題は、知識の衝突です。LLMは膨大なコーパスで事前学習されているため、新しく導入された情報と既存の内部知識が矛盾することが多々あります。…
核心:何を提案したのか
本論文では、これらの課題を包括的に解決するために、LoRAを用いたマルチアップデート知識編集のための学習フレームワークであるCoRSA(Conflict-Resolving and Sharpness-Aware Minimization)を提案しています。CoRSAは、損失曲面の幾何学的構造とモデルの安定性の間に密接な関係があるという分析に基づき、3つの主要なメカニズムを統合しています。 まず、LoRAアダプタの汎化性能と将来の更新に対する安定性を高めるために、Sharpness-Aware Minimization(SAM)を導入しました。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related