Neural Attention Search Linear:適応的なトークンレベルのハイブリッド・アテンション・モデルに向けて
従来のTransformerが抱える計算量の課題と線形アテンションの表現力の限界を解決するため、同一レイヤー内でトークンごとに最適な演算を適応的に選択するフレームワーク「NAtS-L」が開発されました。
TL;DR(結論)
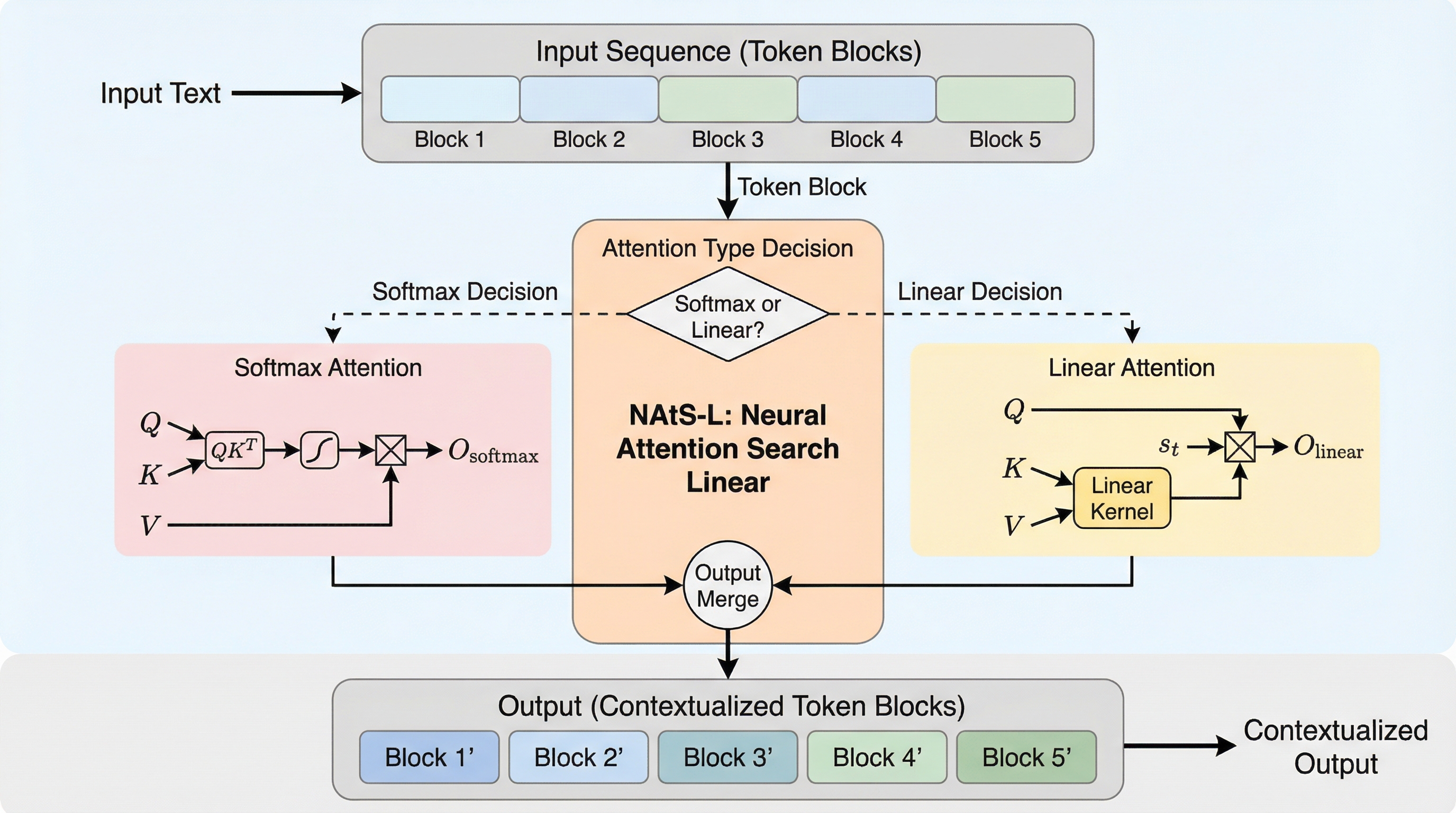
従来のTransformerが抱える計算量の課題と線形アテンションの表現力の限界を解決するため、同一レイヤー内でトークンごとに最適な演算を適応的に選択するフレームワーク「NAtS-L」が開発されました。この手法は、短期的な影響しか持たないトークンには効率的な線形アテンションを適用し、長期的な情報保持が必要なトークンにはSoftmaxアテンションを割り当てることで、計算効率と精度の両立を実現します。学習可能なAttention Score Layerを通じて、各トークンブロックに最適な演算を自動的に検索し、従来の固定的なハイブリッドモデルよりも柔軟で、長文コンテキストにおいて高い性能と低い遅延を維持するトークンレベルの混合アーキテクチャを構築することに成功しました。
なぜこの問題か
現代のLLMにおいて、Transformerモデルは長文コンテキストのグローバルな情報をモデル化する強力な能力を持っており、その中核をなす自己アテンション操作は非常に重要です。しかし、自己アテンションの計算複雑性は入力シーケンスの長さに対して二次関数的($O(L^2)$)に増加するため、コンテキストが長くなるにつれて計算上の大きなボトルネックとなります。推論時においても、すべての中間的なKV値をキャッシュするために線形的なメモリ量が必要となり、コンテキスト長が増大するにつれてGPUメモリシステムに深刻な負荷をかけることになります。この課題を解決するために、非線形なSoftmax操作を線形操作に置き換える線形アテンションモデルが提案されてきましたが、これらは過去の情報を固定サイズの隠れ状態に圧縮するため、表現力が制限されるという欠点があります。 線形アテンションモデルは、トレーニングと推論の両方で複雑さを効率的に削減できる有望な方向性を示していますが、モデルが入力コンテキストのすべてを限られたサイズの隠れ状態にエンコードできるかどうかは依然として不明確です。…
核心:何を提案したのか
本論文では、同一レイヤー内の異なるトークンに対して線形アテンションとSoftmaxアテンションの両方を適用するフレームワーク「Neural Attention Search Linear(NAtS-L)」を提案しています。NAtS-Lは、入力されたトークンが線形アテンションモデルで処理可能か、それともSoftmaxアテンションが必要かを自動的に判断する仕組みを持っています。具体的には、短期的な影響しか持たず固定サイズの隠れ状態にエンコードできるトークンと、長期的な検索に関連する情報を含み将来のクエリのために保存しておく必要があるトークンを識別します。これにより、重要な情報には高精度なSoftmaxを、それ以外には低コストな線形アテンションを使い分けることが可能になります。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related