$V_0$: 状態ゼロにおけるあらゆる方策のための汎用価値モデル
大規模言語モデルの強化学習において、従来のアクター・クリティック法が抱えていた「方策の進化に伴う価値モデルの頻繁な再学習コスト」と、GRPO等の手法における「サンプリングの不安定性」という二律背反の課題を解決するため、方策の能力をパラメータではなく「過去の行動履歴」という文脈情報として読み取る汎用価値モデル「V0」を提案しました。 V0は、意味理解を担う埋め込みバックボーンと統計的推論に特化したTabPFNを組み合わせたハイブリッド構造を採用しており、特定のプロンプトに対する各モデルの成功確率を、追加の勾配更新なしに単一のフォワードパスで予測することが可能です。 実験の結果、V0は学習過程における方策の性能変化を極めて正確に追跡できるだけでなく、未知のモデルやタスクに対しても高い汎化性能を示し、学習時の計算資源配分の最適化や推論時のコスト効率的なルーティングにおいてパレート最適な制御を実現することを実証しました。
TL;DR(結論)
大規模言語モデルの強化学習において、従来のアクター・クリティック法が抱えていた「方策の進化に伴う価値モデルの頻繁な再学習コスト」と、GRPO等の手法における「サンプリングの不安定性」という二律背反の課題を解決するため、方策の能力をパラメータではなく「過去の行動履歴」という文脈情報として読み取る汎用価値モデル「V0」を提案しました。 V0は、意味理解を担う埋め込みバックボーンと統計的推論に特化したTabPFNを組み合わせたハイブリッド構造を採用しており、特定のプロンプトに対する各モデルの成功確率を、追加の勾配更新なしに単一のフォワードパスで予測することが可能です。 実験の結果、V0は学習過程における方策の性能変化を極めて正確に追跡できるだけでなく、未知のモデルやタスクに対しても高い汎化性能を示し、学習時の計算資源配分の最適化や推論時のコスト効率的なルーティングにおいてパレート最適な制御を実現することを実証しました。
なぜこの問題か
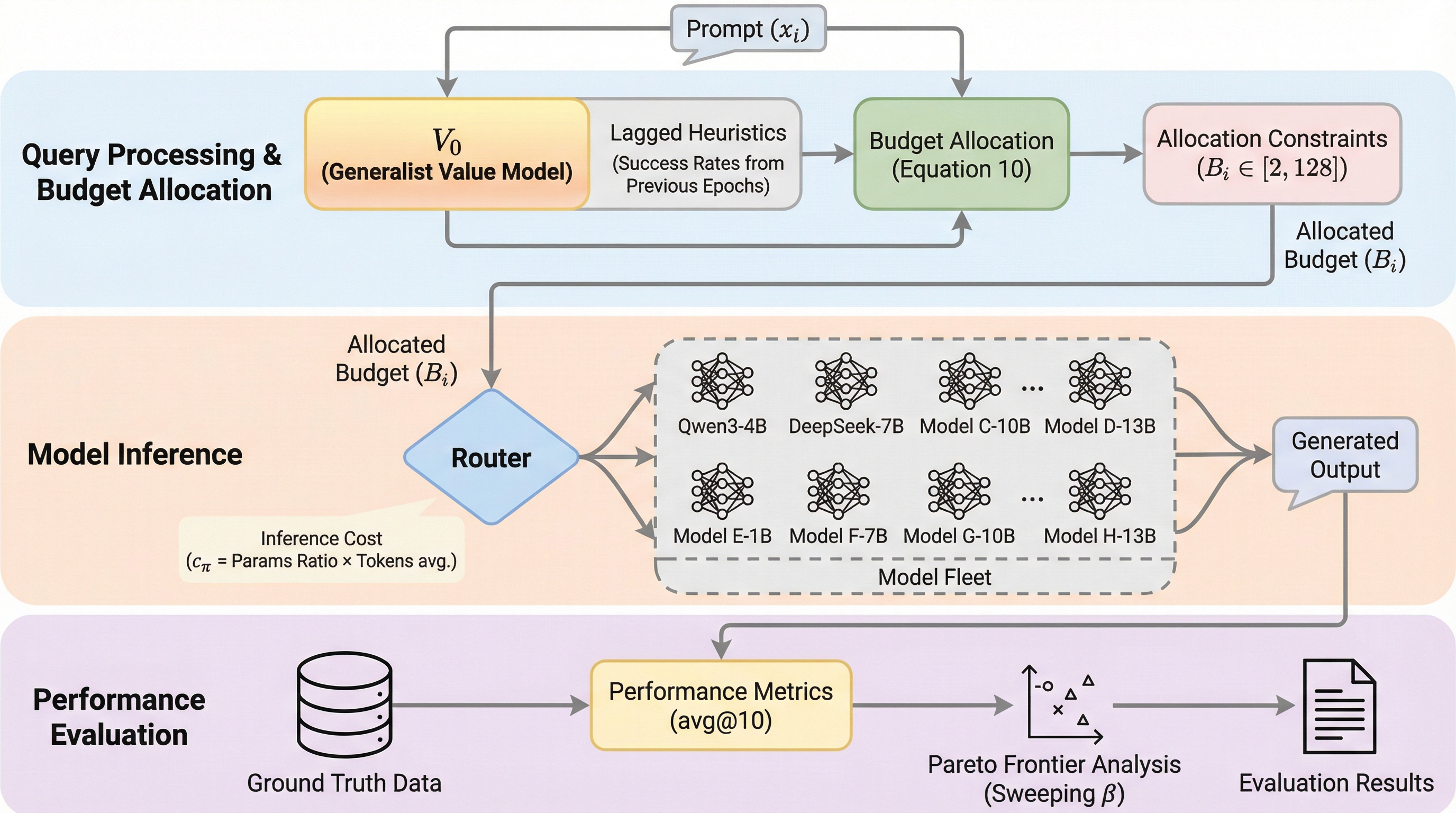
大規模言語モデル(LLM)の事後学習フェーズにおいて、検証可能な報酬を用いた強化学習(RLVR)は、モデルの論理的推論能力や指示追従性能を飛躍的に向上させるための主要なパラダイムとなっています。このプロセスでは、方策勾配法が一般的に用いられますが、ある行動が現在のモデルの平均的な実力に対してどれだけ優れているかを測るための「ベースライン」の設定が、学習の収束性と安定性を左右する極めて重要な要素となります。伝統的なPPO(Proximal Policy Optimization)などのアクター・クリティック法では、このベースラインを推定するために、方策モデルと同等の規模を持つ「価値モデル(クリティック)」を個別に維持し、学習させる必要があります。しかし、方策モデルが学習によって刻一刻と進化し、その能力分布が非定常、つまり常に変化し続ける状態であるため、価値モデルもそれに同期して逐次的に再学習を繰り返さなければなりません。この「結合のジレンマ」は、膨大な計算リソースとメモリのオーバーヘッドを引き起こし、大規模なモデル開発における大きな障壁となっていました。…
核心:何を提案したのか
本論文では、価値推定の枠組みを根本的に再定義した汎用価値モデル「V0」を提案しています。V0の核心的なアイデアは、方策の能力を価値モデルのパラメータ内に隠れた潜在変数として扱うのではなく、明示的な「文脈入力(コンテキスト)」として扱うことにあります。具体的には、価値推定を従来の「パラメータのフィッティング」から「インコンテキスト学習(ICL)」へと転換しました。V0は、特定のモデルが過去にどのようなクエリに対してどのようなパフォーマンス(成功または失敗)を示したかという履歴ペアをコンテキストとして受け取り、それに基づいて未知のプロンプトに対する期待性能を予測します。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related