RAGTurk: トルコ語における検索拡張生成(RAG)のベストプラクティス
トルコ語のような形態論的に豊かな言語における検索拡張生成(RAG)の挙動を解明するため、WikipediaとCulturaXから構築された20,459個の質問回答ペアを含む初の包括的データセット「RAGTurk」が提案されました。
TL;DR(結論)
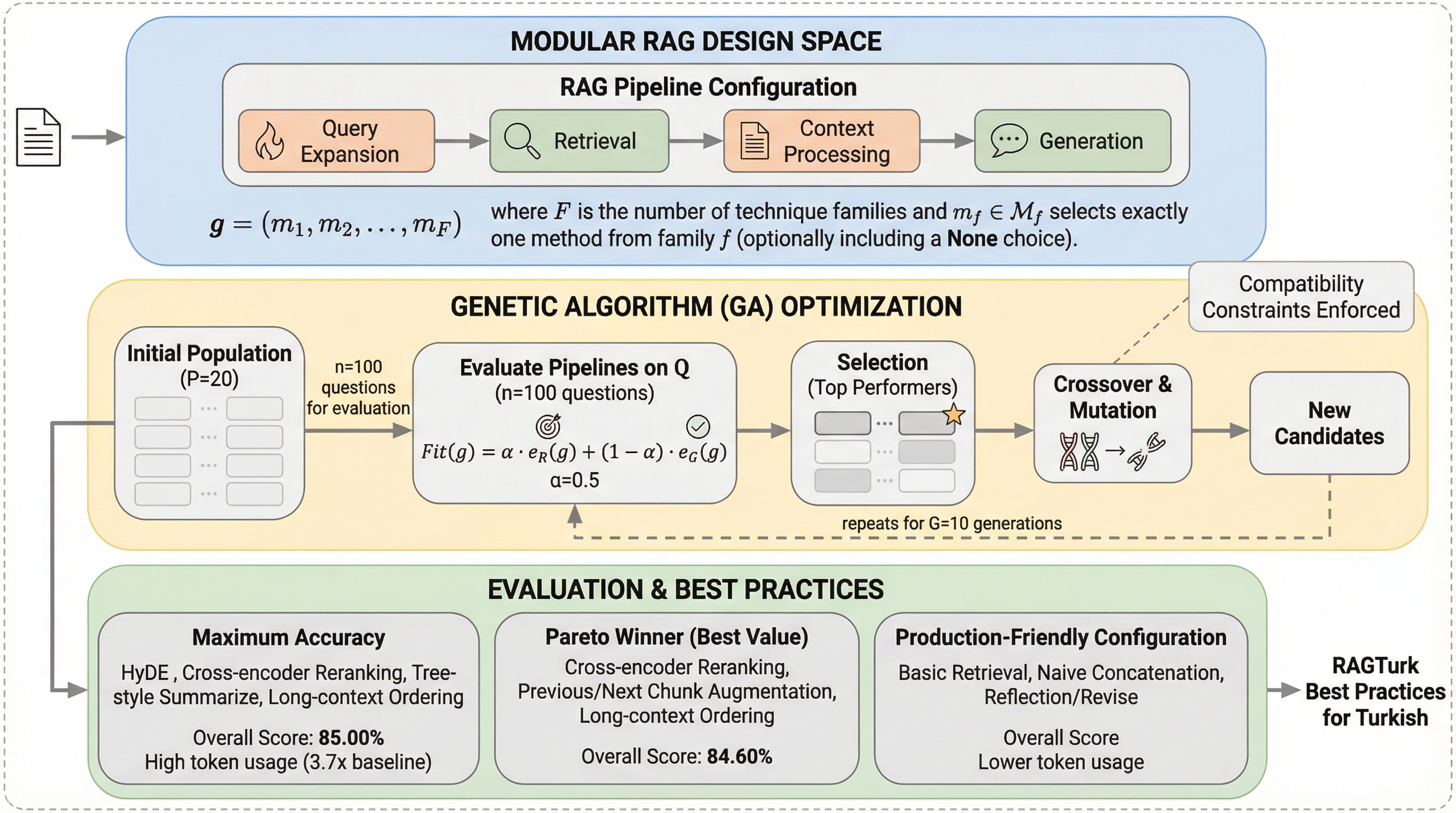
トルコ語のような形態論的に豊かな言語における検索拡張生成(RAG)の挙動を解明するため、WikipediaとCulturaXから構築された20,459個の質問回答ペアを含む初の包括的データセット「RAGTurk」が提案されました。 研究ではクエリ変換から回答の洗練に至る7つの主要ステージをベンチマークし、HyDEが最高精度(85%)を達成する一方で、クロスエンコーダによる再ランキングとコンテキスト拡張を組み合わせた構成が低コストで同等の性能(84.60%)を実現することを明らかにしました。 生成モジュールを過剰に積み重ねるとトルコ語特有の形態論的な手がかりが歪められ、かえって性能が低下するリスクがあるため、堅牢な再ランキングとシンプルなクエリの明確化を核としたパイプライン設計がトルコ語RAGにおいて最も効果的であると結論付けられています。
なぜこの問題か
大規模言語モデル(LLM)は自然言語処理の多くの分野で優れた性能を示していますが、最新の情報や特定のドメイン知識、あるいは検証可能な事実を必要とするクエリに対しては、依然としてハルシネーション(もっともらしい嘘)や知識の欠如という課題を抱えています。検索拡張生成(RAG)は、外部の信頼できる証拠を生成プロセスに取り入れることでこれらの制限を緩和する手法として急速に普及しました。しかし、これまでのRAGに関する設計指針や最適化の研究のほとんどは英語に集中しており、トルコ語のような形態論的に豊かな言語における挙動は十分に解明されていませんでした。 トルコ語は膠着語としての性質を持ち、一つの語根に複数の接辞が結合することで複雑な意味を表現します。このような言語的特徴は、語形変化が激しく、語順も柔軟であるため、英語向けに設計された検索手法やベンチマークでは捉えきれない特有の課題を生じさせます。例えば、単語の表面的な一致に頼る検索では、形態論的な変化によって関連文書を見落とす可能性が高まります。…
核心:何を提案したのか
本研究の核心は、トルコ語におけるRAGパイプラインの初の体系的かつエンドツーエンドの評価を実施し、そのための包括的なベンチマーク「RAGTurk」を構築したことにあります。このデータセットは、信頼性の高い百科事典情報であるトルコ語のWikipediaと、多様なウェブページから抽出されたCulturaXの2つの主要なソースから構成されています。合計で11,196の記事から、20,459個の根拠に基づいた質問回答ペアを生成しました。これには、単純な事実に関する質問だけでなく、複数の情報を組み合わせて解釈を必要とする質問も含まれており、現実世界の多様な検索シナリオを網羅しています。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related