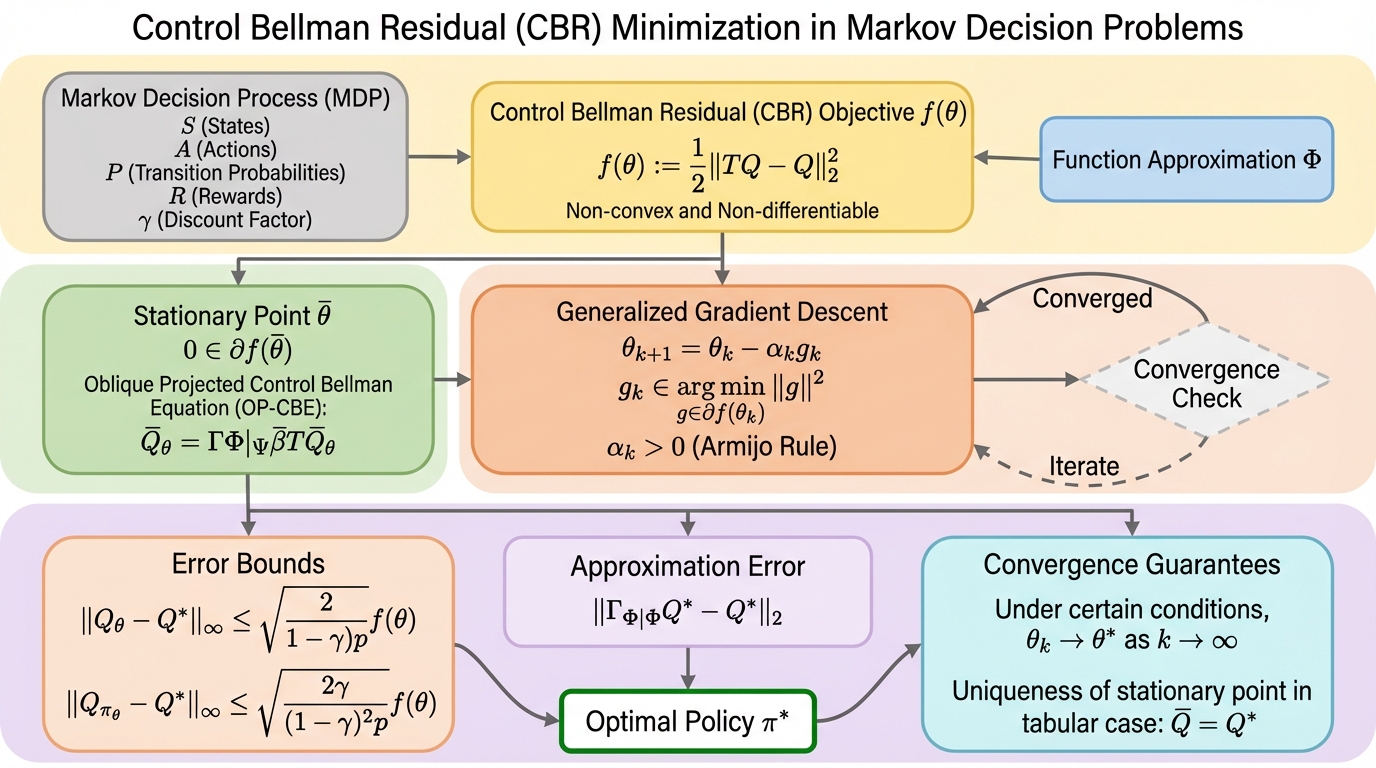
マルコフ決定問題に対する制御ベルマン残差最小化の解析
強化学習の標準的な動的計画法は関数近似下で収縮性を失い収束が不安定になる課題があるが、本研究はベルマン残差最小化を政策最適化(制御タスク)へ拡張し、非凸・非平滑な目的関数が持つ区分的二次構造や局所リプシッツ連続性を解明することで、関数近似を用いても安定して解を探索できる理論的基盤を確立した。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
強化学習の標準的な動的計画法は関数近似下で収縮性を失い収束が不安定になる課題があるが、本研究はベルマン残差最小化を政策最適化(制御タスク)へ拡張し、非凸・非平滑な目的関数が持つ区分的二次構造や局所リプシッツ連続性を解明することで、関数近似を用いても安定して解を探索できる理論的基盤を確立した。
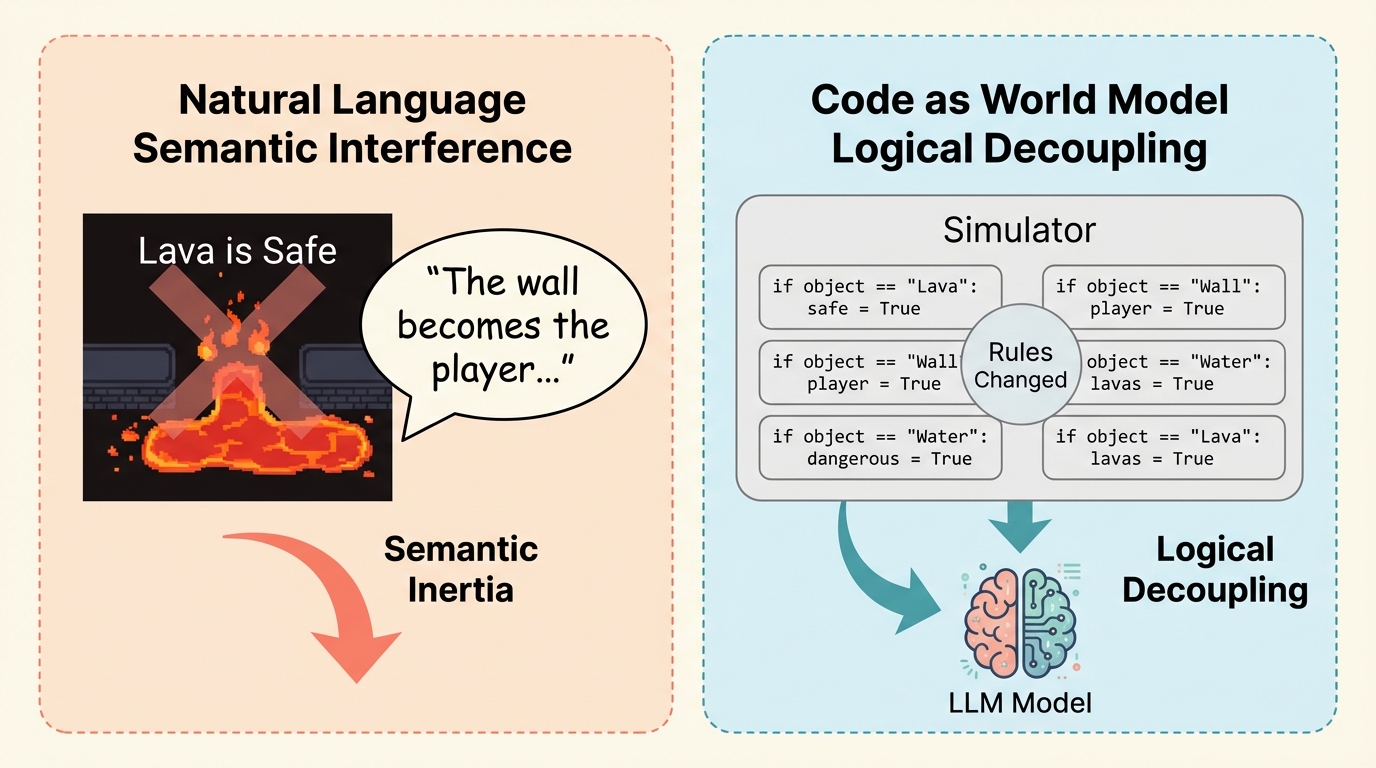
大規模言語モデル(LLM)が、文脈上の新しいルールよりも学習済みの事前知識を優先してしまう「意味的慣性」という問題を特定し、パズルゲーム「Baba Is You」を用いてその影響を定量的に評価しました。
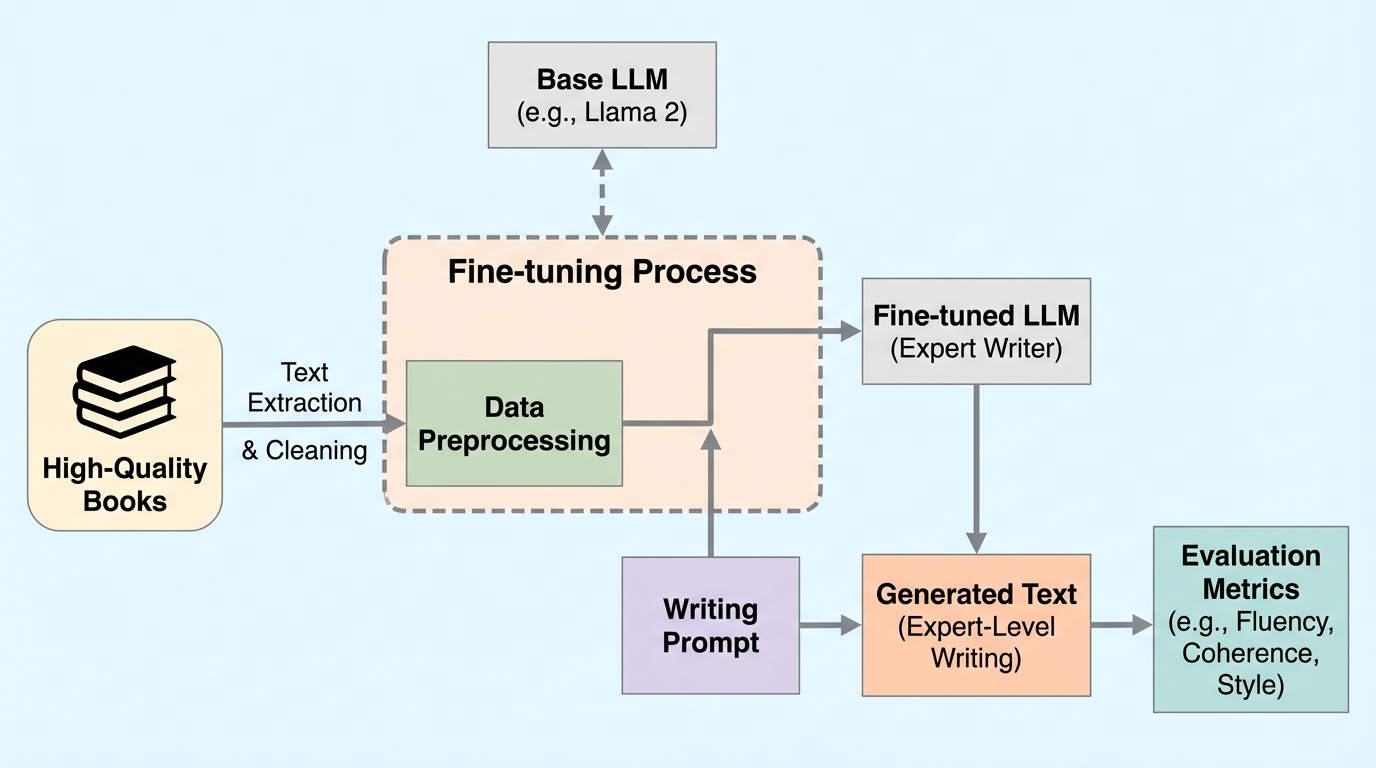
アイオワ・ライターズ・ワークショップ等の名門校に所属する28名の専門作家と3つの大規模言語モデルを対象に、著名な作家50名の文体を模倣する能力を比較する大規模な行動実験が行われました。 文脈内学習のみの条件では専門家は82.
地方自治体が公開する議事録は、官僚的で難解な記述スタイルや膨大な文書量により、市民やジャーナリストが特定の情報を効率的に検索することが困難であるという課題を抱えている。本研究では、大規模言語モデル(LLM)であるGemini 2.
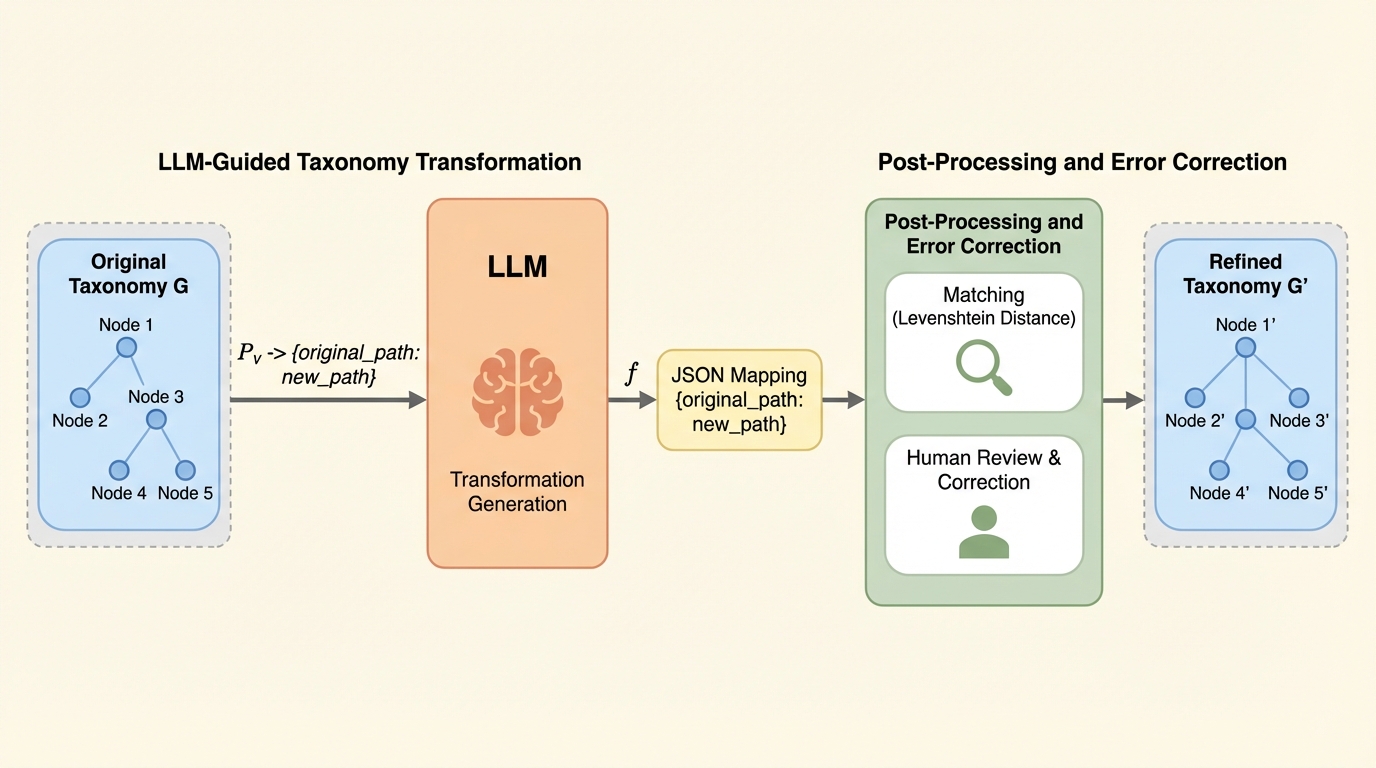
階層的テキスト分類(HTC)において、人間が作成した従来のタクソノミー(分類体系)には曖昧さや不整合が含まれており、言語モデルの学習を妨げているという課題がある。 本研究が提案する「TAXMORPH」は、大規模言語モデル(LLM)をタクソノミストとして活用し、リネームや統合、再配置を通じて分類体系全体をモデルの内部表現に適した構造へと自動的に洗練させるフレームワークである。 実験の結果、LLMで洗練されたタクソノミーは人間による元の体系を最大で2.9ポイント上回るF1スコアを記録し、モデルの推論バイアスとより密接に一致することで分類精度を向上させることが確認された。
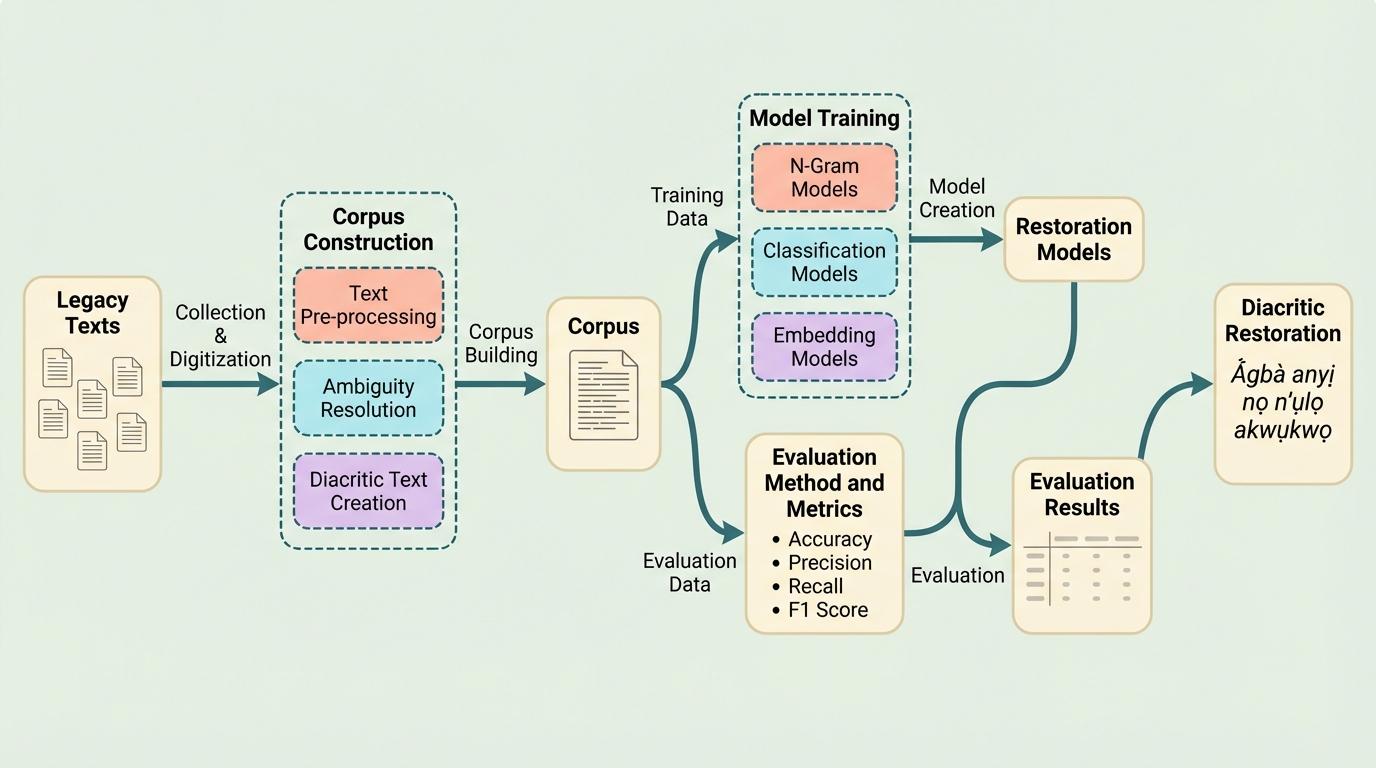
イグボ語は自然言語処理のリソースが極めて乏しい言語であり、デジタルテキストにおいて意味や声を区別する発音記号が省略されることで生じる深刻な曖昧性が、言語理解の大きな障壁となっている。本研究では、この問題を解決するために、n-gramモデル、機械学習による分類モデル、および他言語からの投影を利用した単語埋め込みモデルという3つの主要な技術的アプローチを提案し、データセット生成のための柔軟なフレームワークを構築した。検証の結果、提案されたすべての手法が単語の出現頻度のみに基づく基準値を大幅に上回る精度を記録し、特に文脈情報を活用する手法が、検索エンジンや機械翻訳などの言語インフラを改善する上で極めて有効であることを実証した。
科学計算の基盤である膨大なレガシーFortranコードを現代的なGPU対応のDevito環境へ移行させるため、GraphRAGと多層的なAIエージェントを組み合わせた統合フレームワークが開発されました。
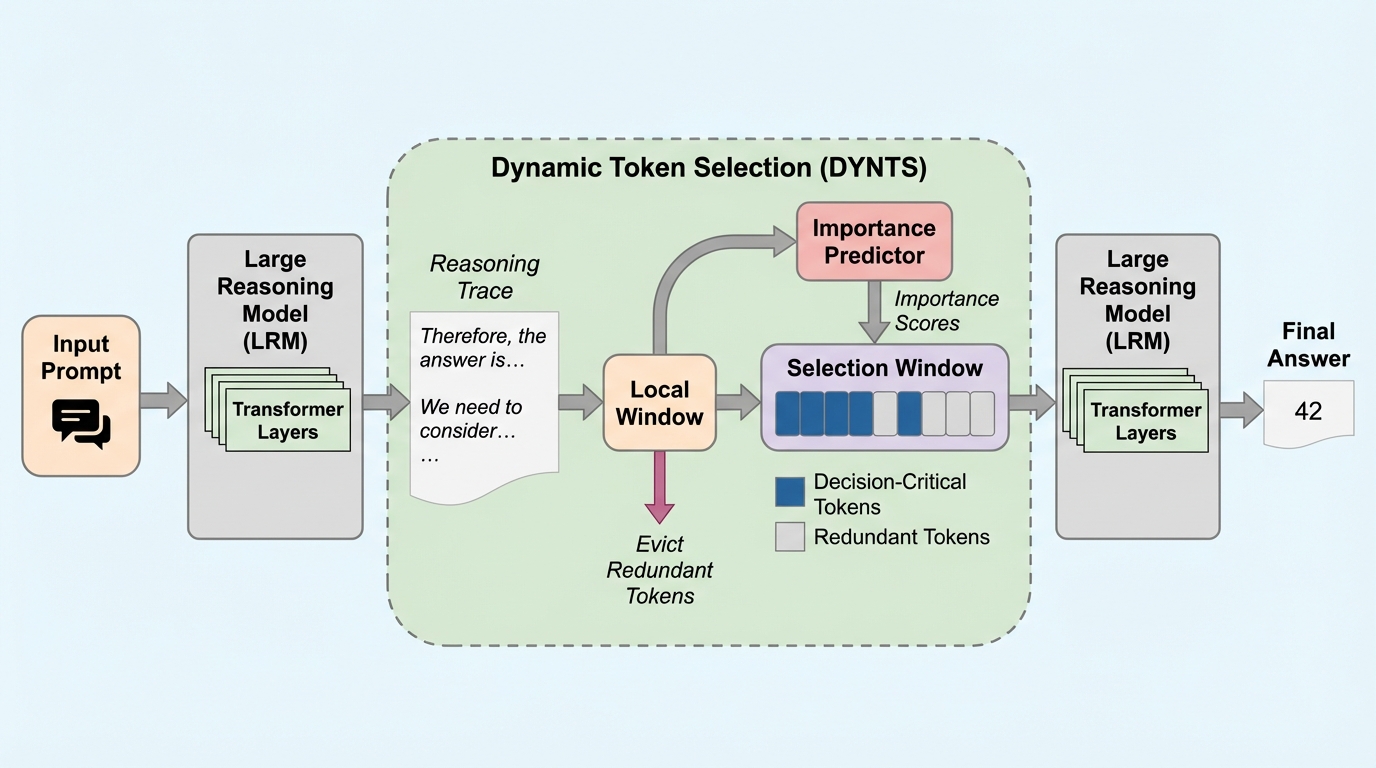
大規模推論モデル(LRM)が生成する膨大な思考プロセスは、メモリ消費と計算コストを増大させ、効率的な展開を妨げる深刻なボトルネックとなっています。本研究では、アテンションマップの解析により、思考トークンのうち最終的な回答に寄与するのはわずか約20%から30%の重要なトークンのみであり、残りの大部分は冗長であるという「推論におけるパレートの法則」を発見しました。この知見に基づき、重要な思考トークンを動的に予測・選択して保持し、不要なキャッシュを破棄する手法「DYNTS」を提案し、推論速度を最大2.62倍向上させ、メモリ使用量を最大5.73倍削減しつつ、フルキャッシュと同等の高い精度を維持することに成功しました。
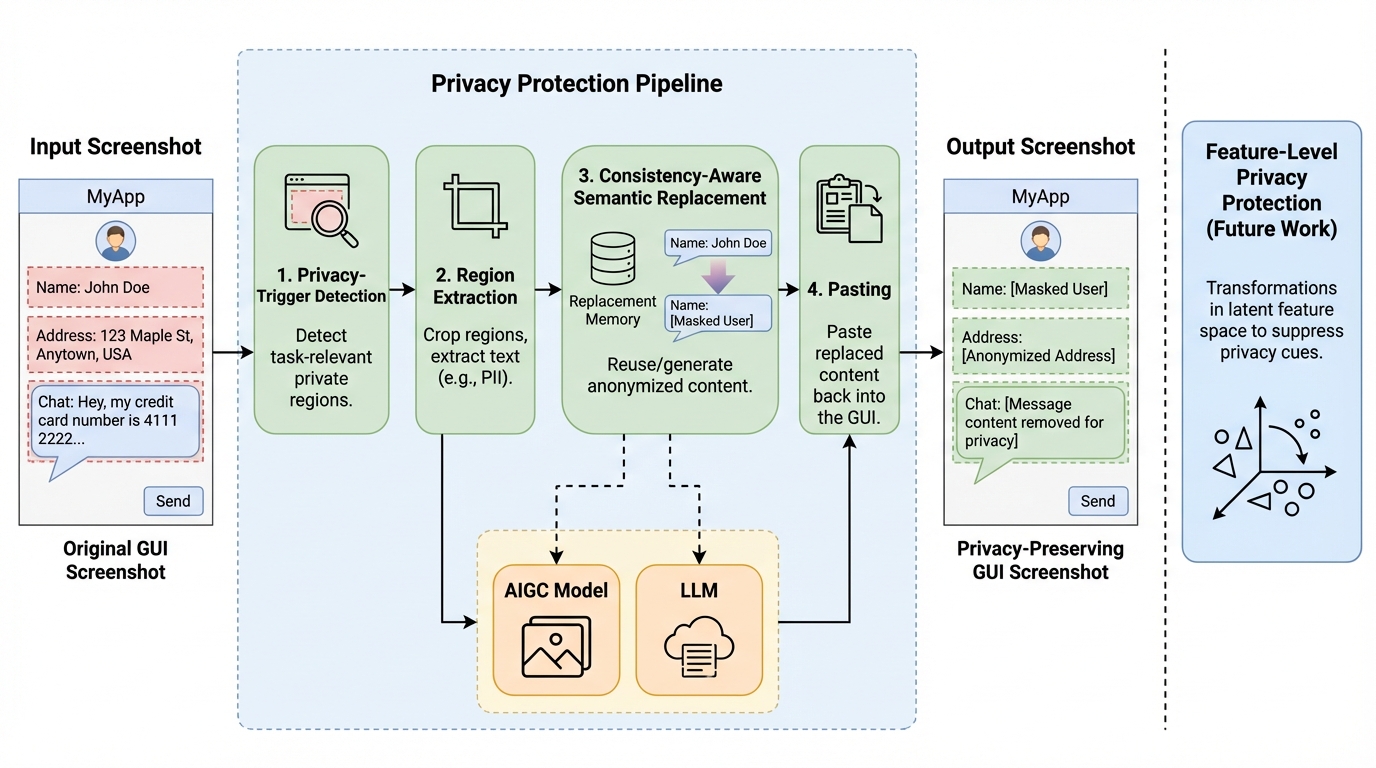
GUIエージェントが画面情報を外部サーバーへ送信する際の深刻なプライバシー漏洩リスクを解決するため、認識・保護・実行の3段階で構成される汎用フレームワーク「GUIGuard」を提案した。この手法は、機密情報の特定と加工をユーザーのローカルデバイスで行い、加工済みの安全な情報のみを強力なリモートモデルへ送信することで、高度な推論能力とプライバシー保護を両立させるものである。 1万枚以上のスクリーンショットを含む大規模ベンチマーク「GUIGuard-Bench」を構築し、既存の最新モデルでもプライバシー情報の認識精度が極めて低いという深刻な現状を明らかにした。Android環境で13.3%、PC環境で1.4%という結果は、現在のAIが何を守るべきかを正しく判断できていないことを示しており、実用化に向けた最大の障壁が認識精度にあることを浮き彫りにした。 機密情報を隠蔽しつつタスクの実行に必要な意味情報を維持する保護戦略を導入することで、ユーザーのプライバシー保護と自動化タスクの成功を高い次元で両立できることを実証した。本研究は、プライバシー認識の精度向上こそが実用的なGUIエージェント構築における最大のボトルネックであることを示し、信頼できるハイブリッド型サービスの実現に向けた具体的な技術的指針と評価基盤を提供している。
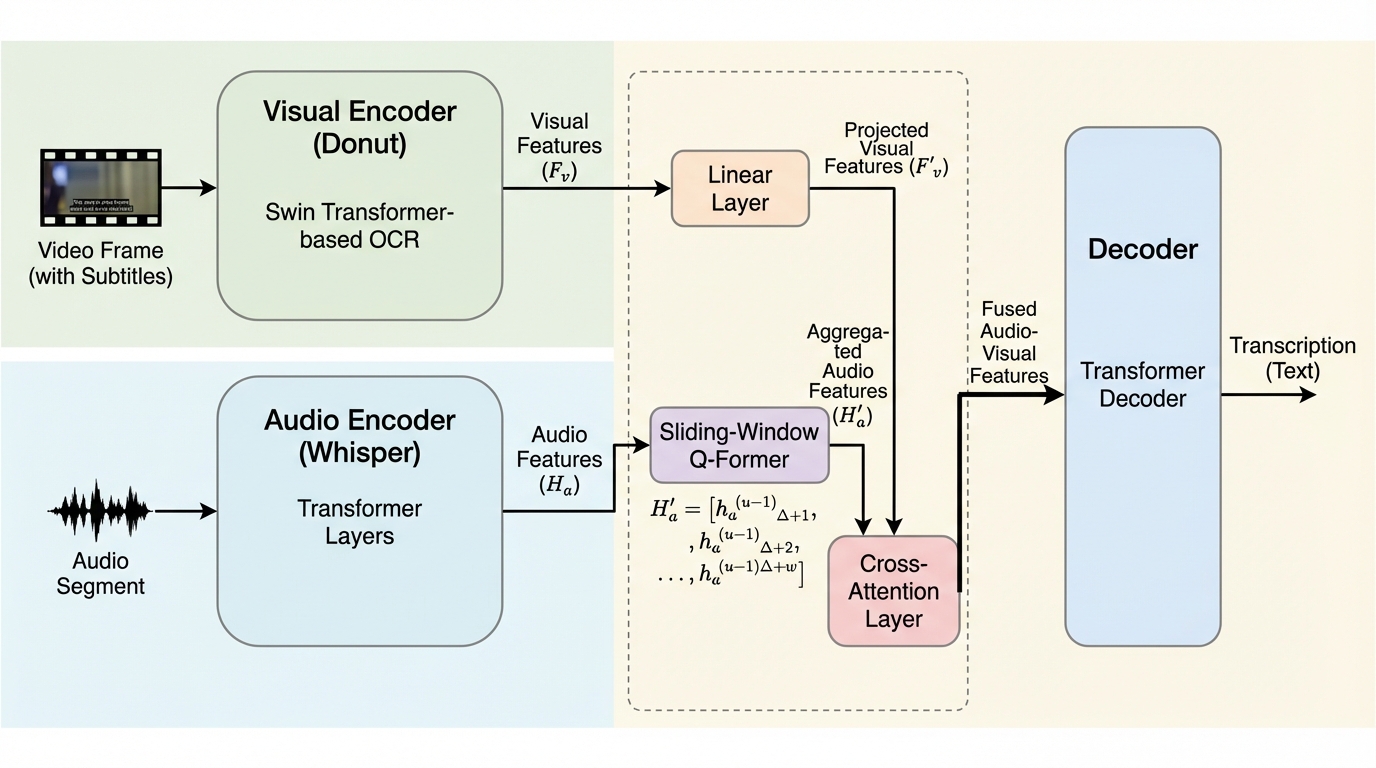
本研究では、音声認識モデルのWhisperとOCRモデルのDonutを統合した、エンドツーエンドのマルチモーダル音声認識モデル「Donut-Whisper」を提案し、映画の字幕などの視覚的なテキスト情報を活用することで、音声のみのモデルが苦手とするノイズ環境や未知語の認識精度を大幅に向上させた。