大規模推論モデルにおける効率的な推論のための動的思考トークン選択
大規模推論モデル(LRM)が生成する膨大な思考プロセスは、メモリ消費と計算コストを増大させ、効率的な展開を妨げる深刻なボトルネックとなっています。本研究では、アテンションマップの解析により、思考トークンのうち最終的な回答に寄与するのはわずか約20%から30%の重要なトークンのみであり、残りの大部分は冗長であるという「推論におけるパレートの法則」を発見しました。この知見に基づき、重要な思考トークンを動的に予測・選択して保持し、不要なキャッシュを破棄する手法「DYNTS」を提案し、推論速度を最大2.62倍向上させ、メモリ使用量を最大5.73倍削減しつつ、フルキャッシュと同等の高い精度を維持することに成功しました。
TL;DR(結論)
大規模推論モデル(LRM)が生成する膨大な思考プロセスは、メモリ消費と計算コストを増大させ、効率的な展開を妨げる深刻なボトルネックとなっています。本研究では、アテンションマップの解析により、思考トークンのうち最終的な回答に寄与するのはわずか約20%から30%の重要なトークンのみであり、残りの大部分は冗長であるという「推論におけるパレートの法則」を発見しました。この知見に基づき、重要な思考トークンを動的に予測・選択して保持し、不要なキャッシュを破棄する手法「DYNTS」を提案し、推論速度を最大2.62倍向上させ、メモリ使用量を最大5.73倍削減しつつ、フルキャッシュと同等の高い精度を維持することに成功しました。
なぜこの問題か
DeepSeek-R1やGemini、ChatGPTなどの最新の大規模推論モデル(LRM)は、最終的な回答を導き出す前に「思考の痕跡(reasoning trace)」を明示的に生成することで、数学やプログラミング、科学といった複雑で困難なタスクにおいて極めて優れた性能を発揮します。しかし、この思考プロセスは非常に長くなる傾向があり、推論中におけるKey-Value(KV)キャッシュのメモリ占有量を膨大にし、アテンション計算に関連する計算負荷を急増させます。特にリソースが制限された環境において、この膨大なメモリフットプリントはモデルの展開を困難にする決定的な要因となっています。既存のKVキャッシュ圧縮技術は、不要なトークンを定期的に破棄することで最適化を試みてきましたが、これらをLRMの推論プロセスにそのまま適用するには二つの大きな限界がありました。 第一に、従来の多くの手法は長いコンテキストのプリフィル(事前入力)段階を最適化するように設計されており、LRM特有の「短いプリフィルと非常に長いデコーディング(生成)」というシナリオには適していません。…
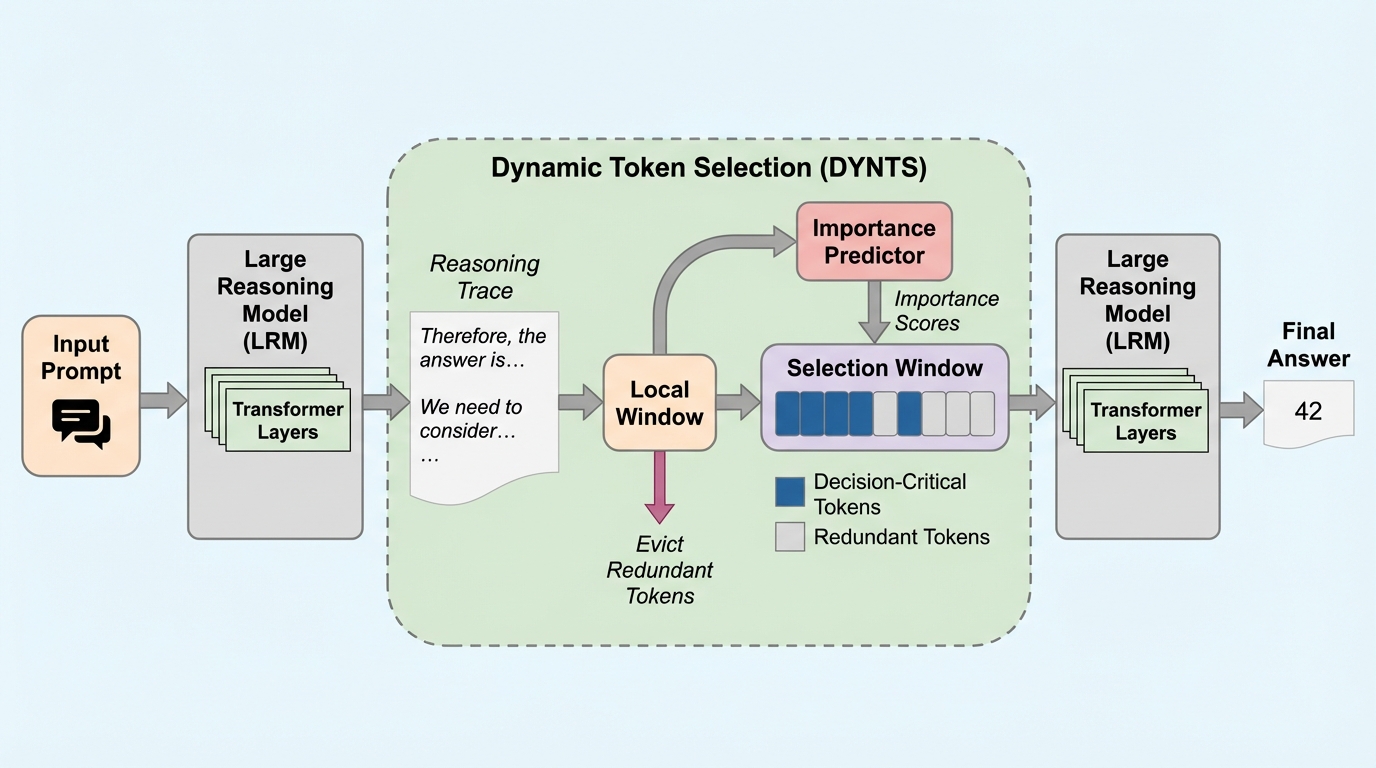
核心:何を提案したのか
本研究では、LRMが生成するコンテンツを詳細に分析し、どのトークンが最終的な回答を導くために最も重要であるかを調査しました。アテンションの重みはトークン間の依存関係を捉える指標となるため、これを利用して思考トークンの重要度を評価しました。具体的には、生成された内容を「思考の痕跡」と「最終的な回答」に分解し、回答トークンから各思考トークンへのアテンションの重みを集計することで重要度スコアを算出しました。その結果、思考トークンのうち平均以上の重要度スコアを持つのはわずか約21.1%に過ぎず、大多数の推論ステップは最終的な回答に対してわずかな影響しか与えていないことが判明しました。この発見は、LRMの推論においても「パレートの法則(80/20の法則)」が成立していることを示唆しています。つまり、ごく一部の決定的な思考トークンが回答の正否を支配しているのです。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related