貪欲になるな、再考せよ:文書レベルの情報抽出のためのサンプリングと選択
文書レベル情報抽出(DocIE)において、従来の「貪欲法(Greedy Decoding)」による単一出力はモデルの潜在能力を制限していましたが、本研究では複数の候補を生成して最適なものを選択するフレームワーク「ThinkTwice」を提案しました。
TL;DR(結論)
文書レベル情報抽出(DocIE)において、従来の「貪欲法(Greedy Decoding)」による単一出力はモデルの潜在能力を制限していましたが、本研究では複数の候補を生成して最適なものを選択するフレームワーク「ThinkTwice」を提案しました。 この手法では、候補間の類似度に基づく「F1 Voting」や学習済みの報酬モデルによる選択を導入し、特に推論能力を持つ大規模言語モデルにおいて、サンプリング数を増やすことで従来の最高精度を大幅に更新することに成功しました。 さらに、高品質な推論過程を自動生成する棄却サンプリング手法を開発し、多言語対応や複雑な構造を持つデータセットにおいても、教師あり・なしの両設定で既存手法を凌駕する性能を達成し、推論時の計算量拡大の有効性を証明しました。
なぜこの問題か
情報抽出(IE)は、テキストから特定のエンティティや関係性を特定し、構造化された形式に変換する極めて重要なタスクです。歴史的に見れば、情報抽出は文書全体を対象とするタスクとして定義されてきましたが、機械学習や統計的手法の普及に伴い、処理や注釈が容易な「文レベル」のデータセットへと焦点が移ってしまった経緯があります。しかし、現実世界のニュース記事や公式報告書、法的文書などでは、重要な情報は単一の文に収まることは稀であり、複数の文やセクションに分散していることが一般的です。そのため、文書全体を俯瞰して情報を統合し、複雑な推論を行う文書レベル情報抽出(DocIE)の重要性が近年改めて強く認識されています。 近年の大規模言語モデル(LLM)の飛躍的な発展により、長いコンテキストを直接処理し、ゼロショットやフューショットで情報を抽出することが可能になりました。しかし、LLMの生成プロセスには本質的に不確実性が伴います。これまでの研究では、評価の再現性や安定性を確保するために、常に最も確率の高い単一の単語を選択し続ける「貪欲法(Greedy Decoding)」を採用するのが標準的な作法となっていました。…
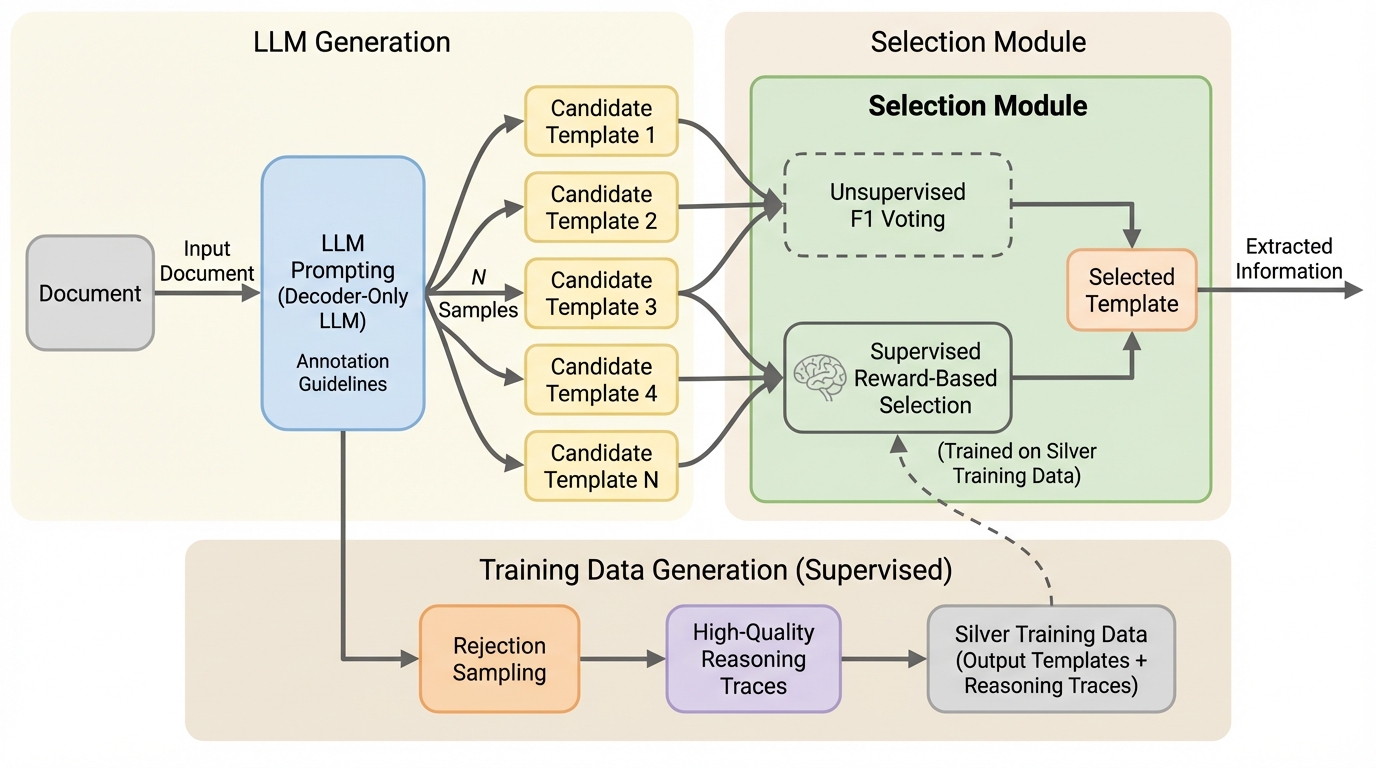
核心:何を提案したのか
本研究は、大規模言語モデルが一度の生成で満足するのではなく、何度も「再考」して最適な答えを選び出す新しいフレームワーク「ThinkTwice」を提案しました。このフレームワークは、対象の文書に対して複数の候補テンプレートをサンプリングし、次に専用の選択モジュールがそれらの中から最も信頼できる出力を特定するという二段階の構成をとっています。これにより、単一の出力に依存するリスクを回避し、モデルの生成能力を最大限に活用することが可能になります。 提案手法の核心は、抽出された情報の質を評価するための二つの革新的な選択戦略にあります。一つ目は、教師なし手法である「F1 Voting」です。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related