マルチモーダル大規模言語モデルの音声推論能力のためのベンチマーク
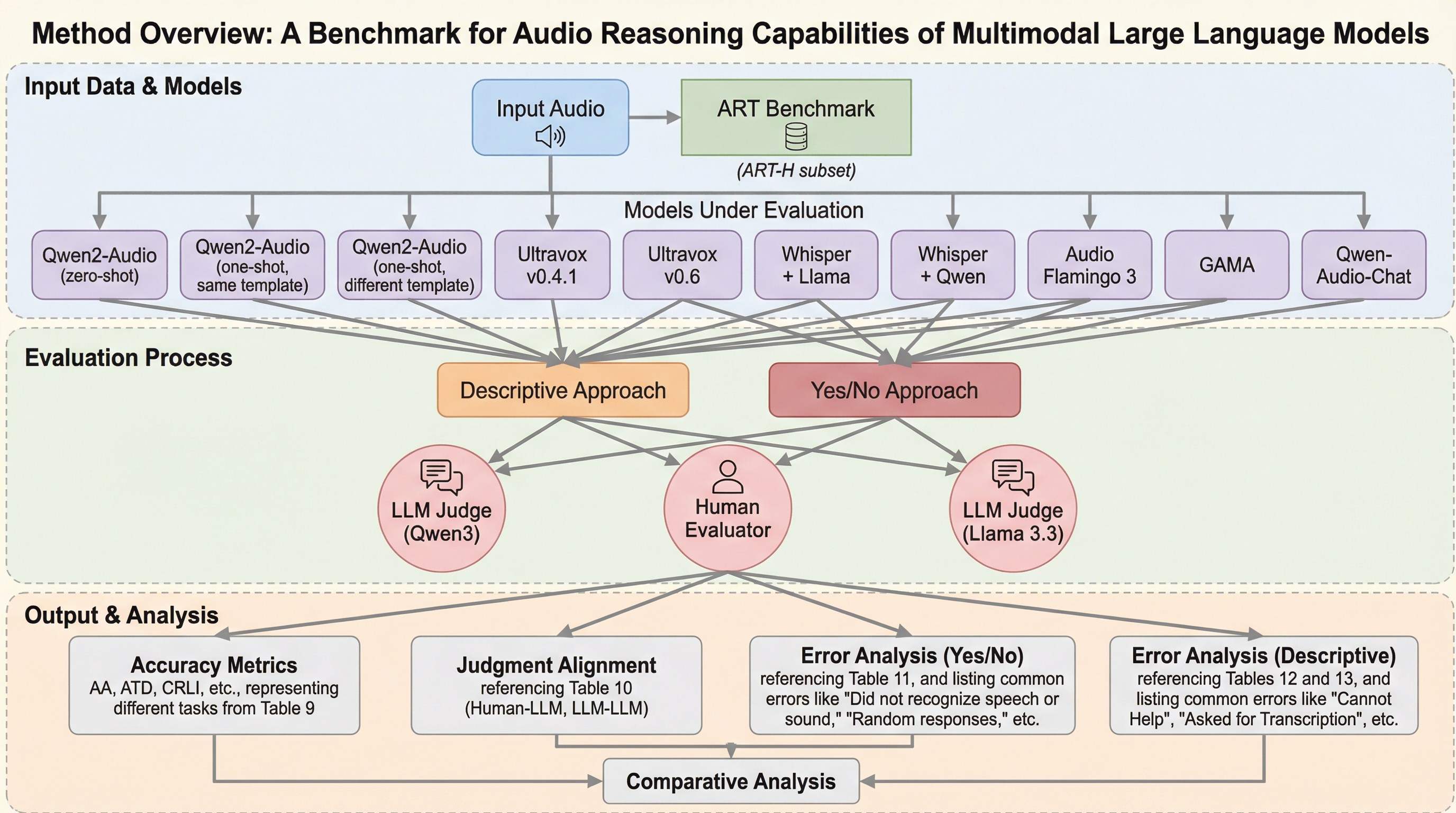
現在のマルチモーダル大規模言語モデル(MLLM)の音声評価指標は、話者識別や性別判定といった個別のタスクに偏っており、複数の音声情報を組み合わせて論理的に思考する「推論能力」を十分に測定できていない。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
現在のマルチモーダル大規模言語モデル(MLLM)の音声評価指標は、話者識別や性別判定といった個別のタスクに偏っており、複数の音声情報を組み合わせて論理的に思考する「推論能力」を十分に測定できていない。
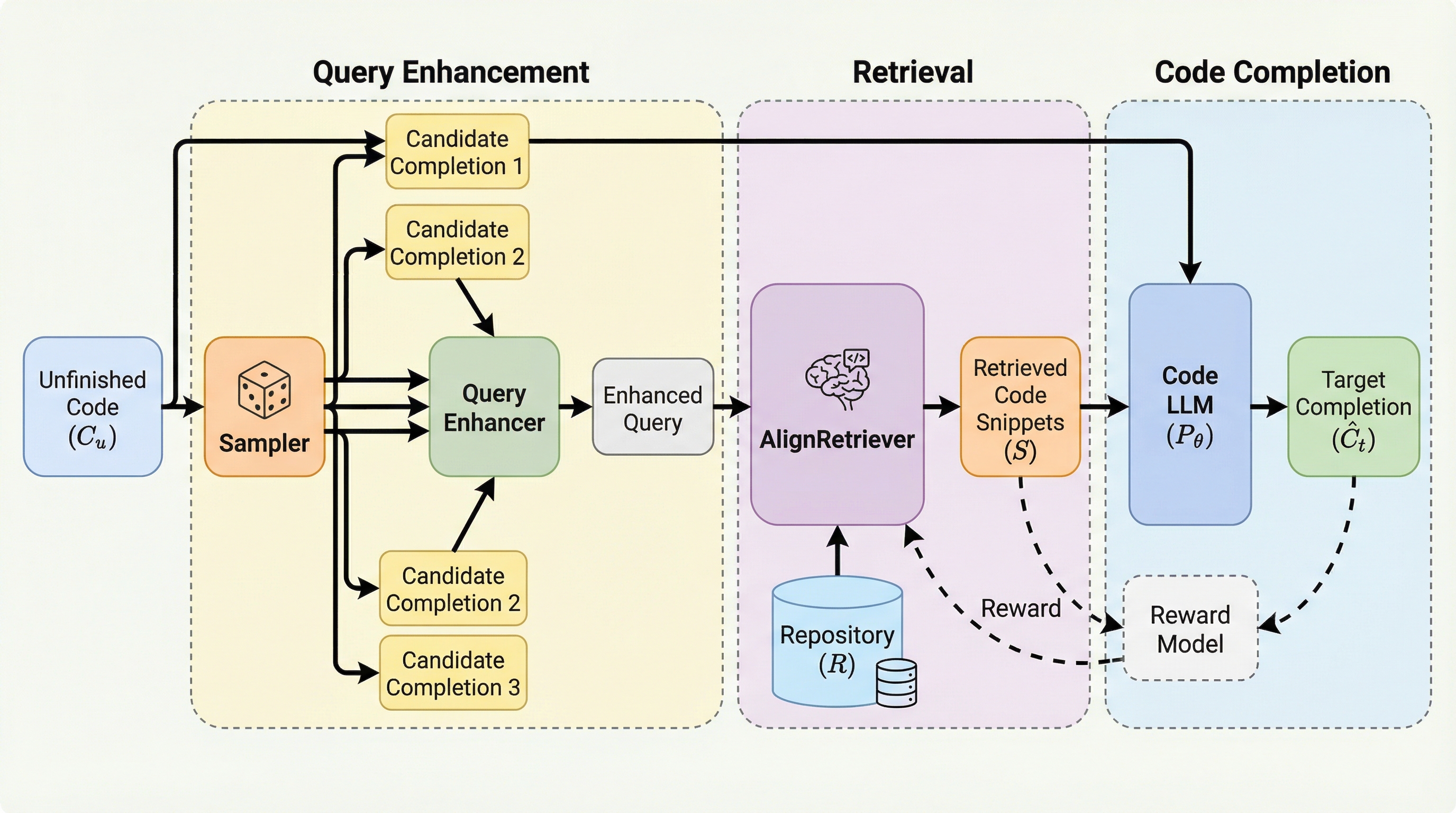
既存のコード生成モデルはリポジトリ固有の知識が不足しており、検索拡張生成(RAG)を用いてもクエリとターゲットコードの間に意味的な不一致が生じるという課題がありました。本研究が提案するAlignCoderは、複数の候補生成によってクエリを強化する仕組みと、強化学習を用いた検索モデルの訓練手法を導入することで、検索精度とコード補完の正確性を大幅に向上させます。実験の結果、CrossCodeEvalベンチマークにおいてベースラインを18.1%上回るEMスコアを達成し、多様なプログラミング言語やモデルに対して高い汎用性と優れた性能を持つことが実証されました。
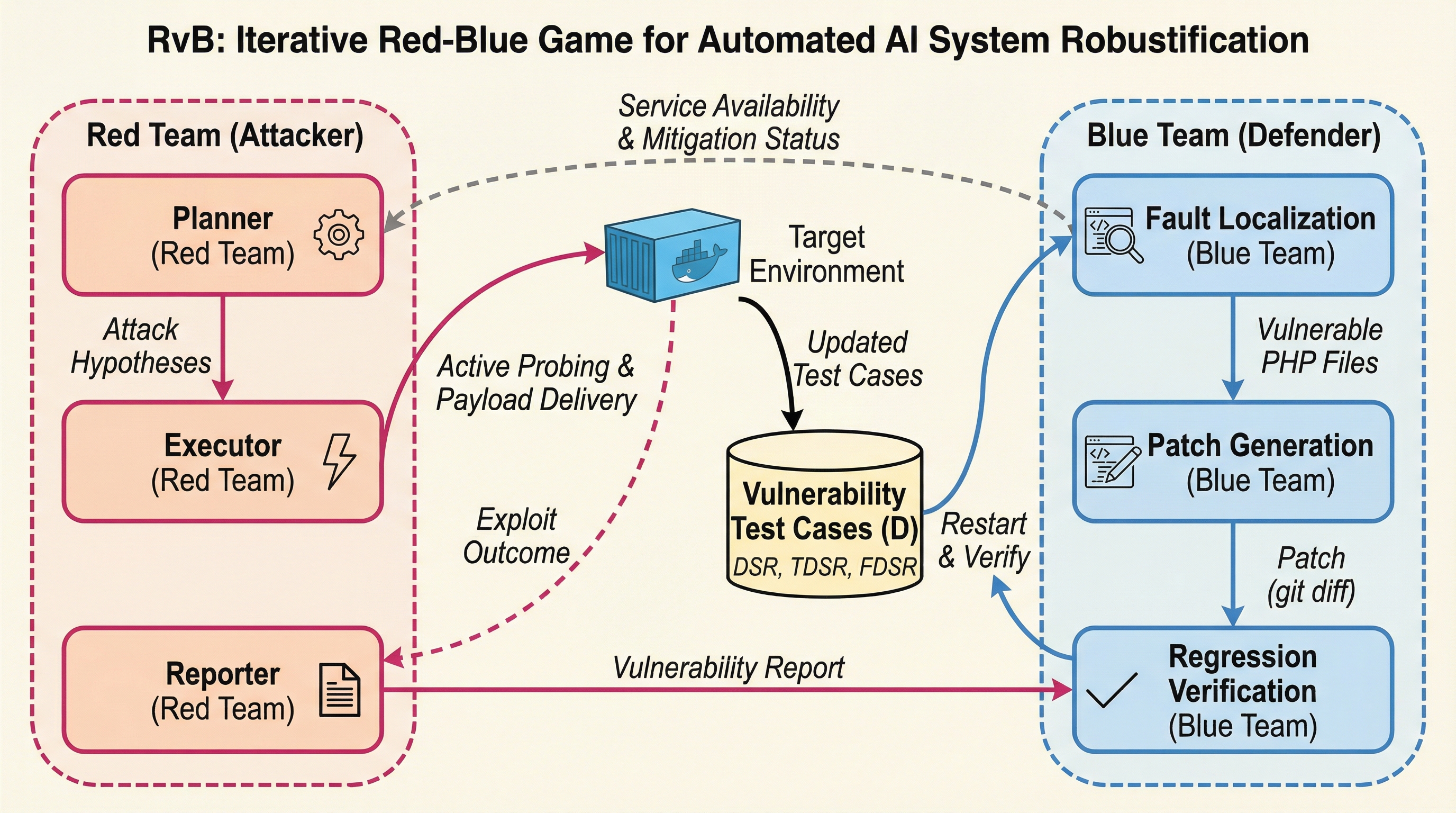
RvBは、大規模言語モデルの安全性を飛躍的に高めるために開発された、学習や微調整を一切必要としない革新的な自動堅牢化フレームワークであり、攻撃を担うレッドチームと防御を担うブルーチームが対話的に試行錯誤を繰り返す「不完全情報ゲーム」として設計されている。
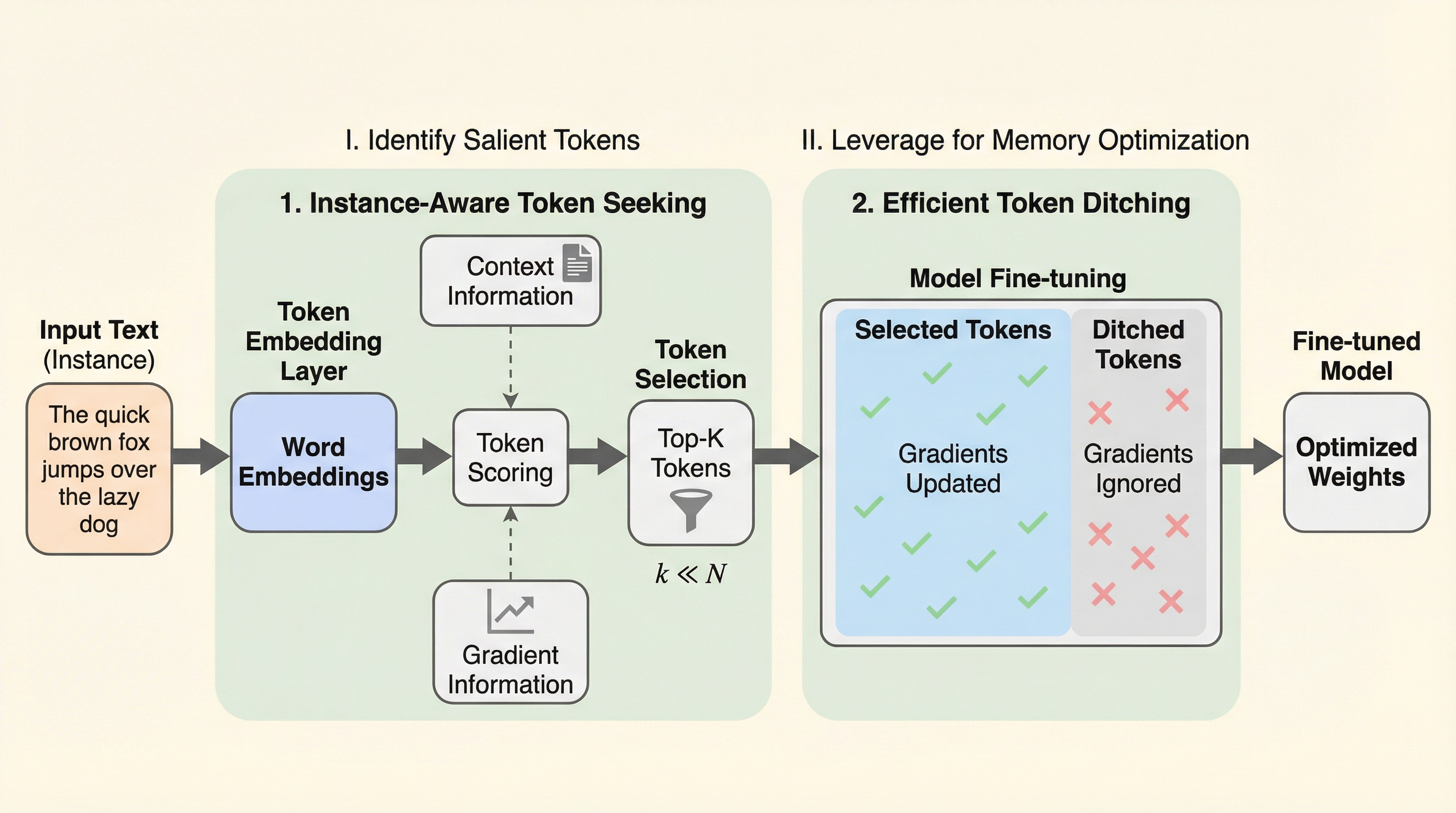
大規模言語モデルのファインチューニングにおいて、メモリ消費の最大87%を占めるアクティベーションの課題を解決するため、各データの文脈と勾配情報から重要なトークンのみを選択して学習する「TOKENSEEK」が提案されました。 この手法は、Llama3.2 1Bにおいて元のメモリのわずか14.8%(2.
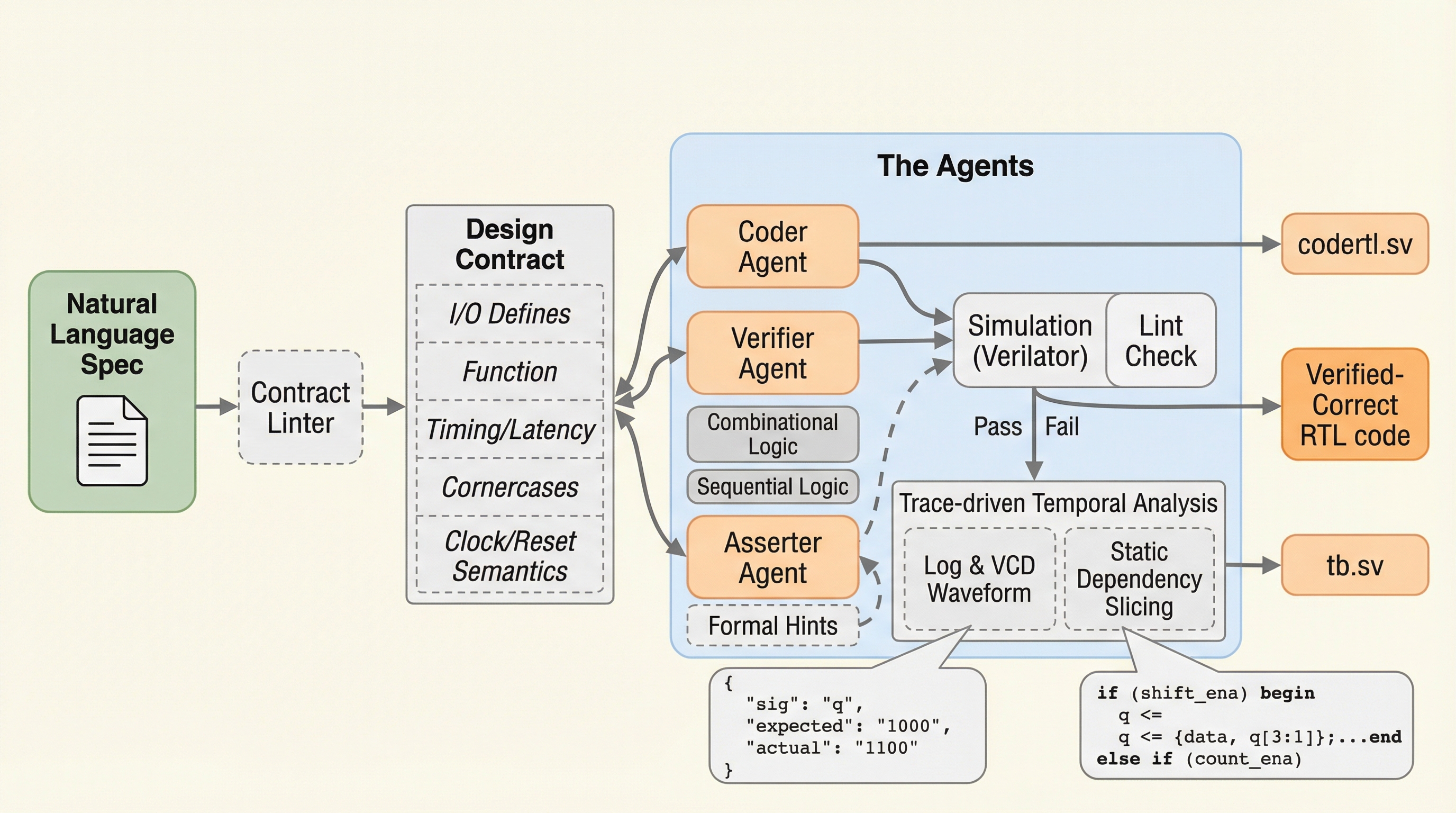
大規模言語モデルを用いたRTL設計において、設計契約(Design Contract)を核としたマルチエージェントフレームワーク「VERI-SURE」を開発し、エージェント間での意図の乖離(セマンティック・ドリフト)を防ぐ仕組みを構築しました。
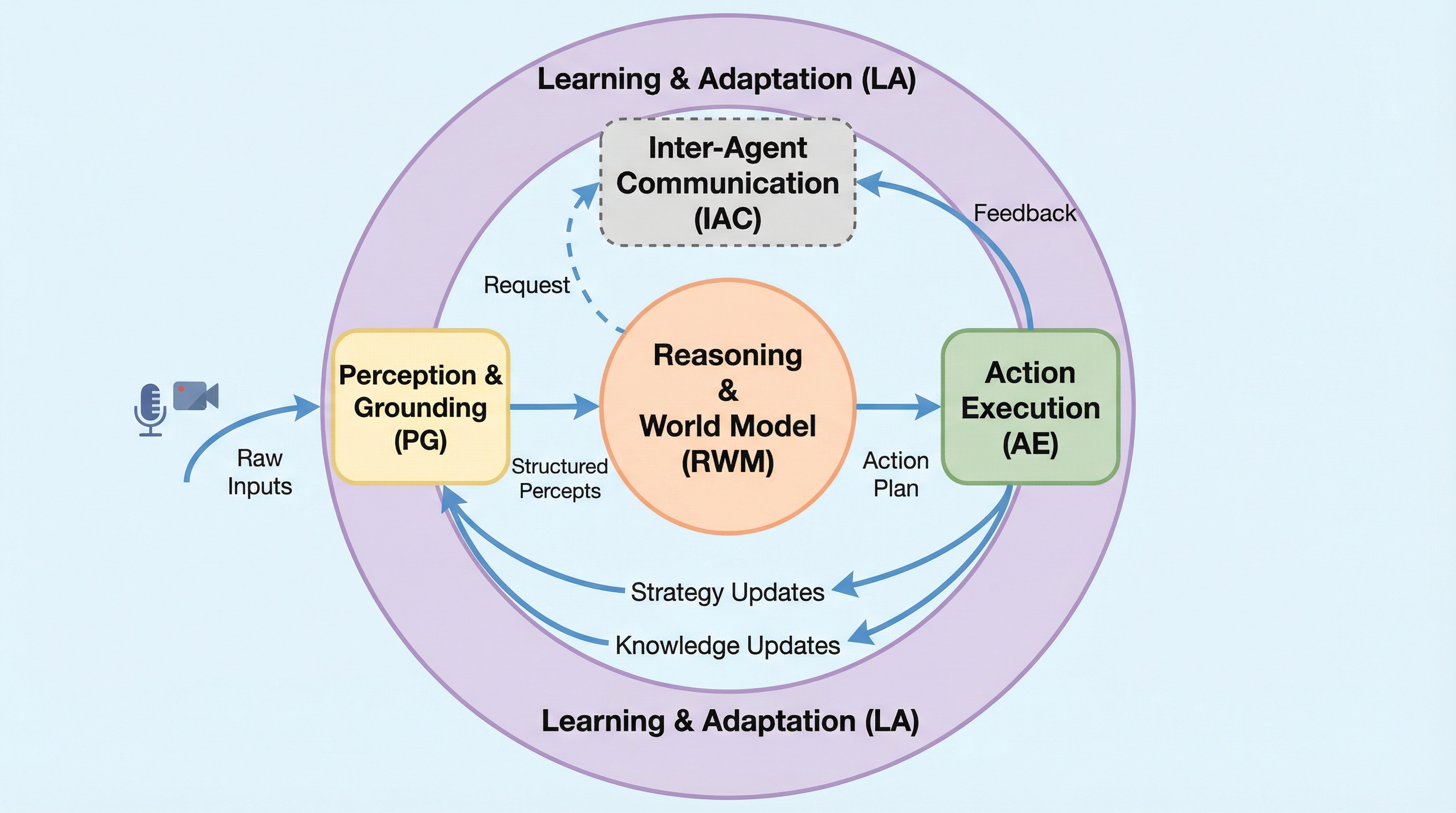
基盤モデルを用いたエージェントAIは、ハルシネーションや推論能力の不足、そして場当たり的なシステム設計による信頼性の低さが大きな課題となっており、既存の設計パターンも理論的根拠に欠け実装が困難な状況にあります。
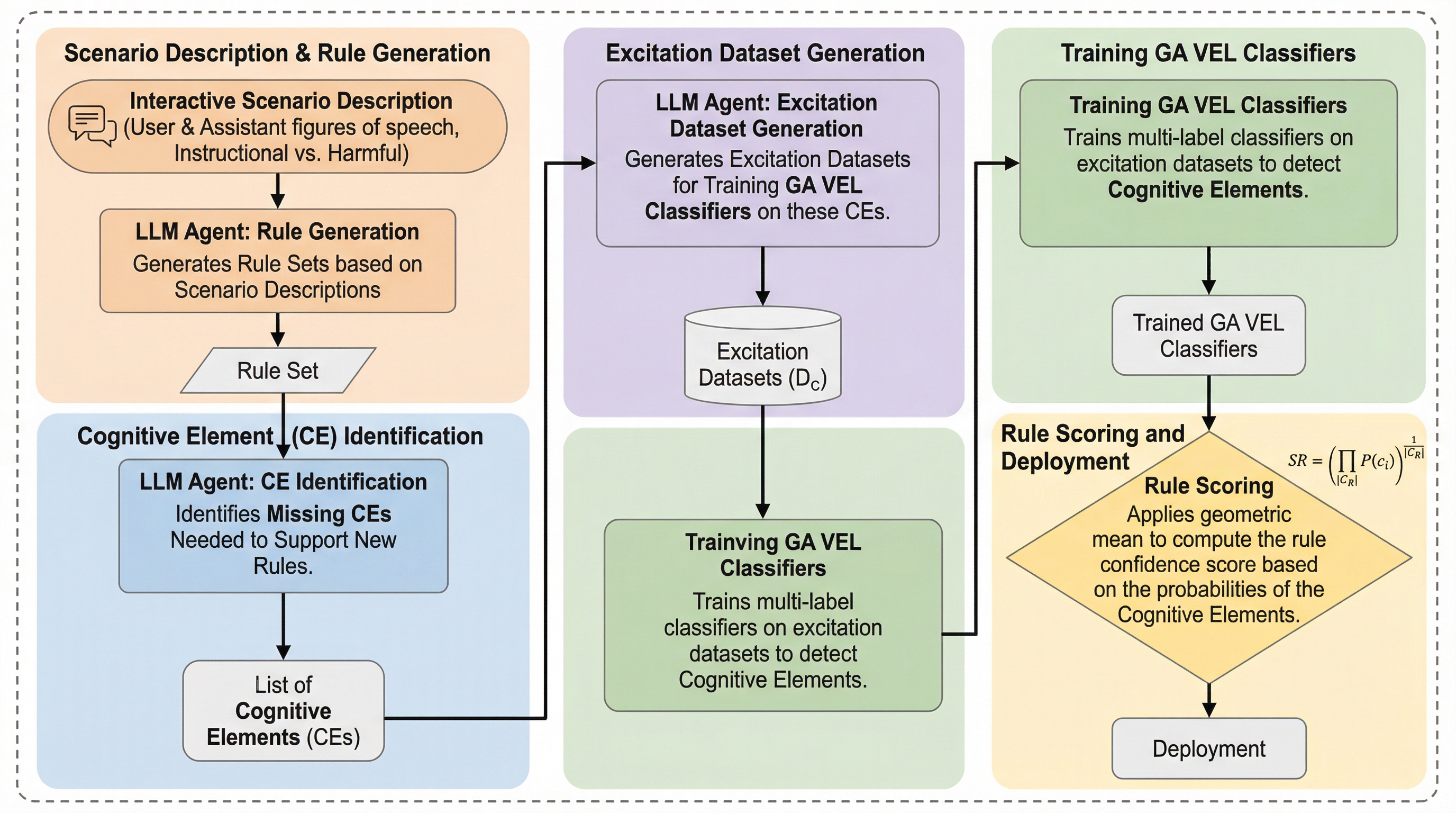
大規模言語モデル(LLM)の内部状態を「認知要素(CE)」という解釈可能な最小単位に分解し、それらを論理ルールで組み合わせることで、高度な安全監視を実現するフレームワーク「GAVEL」が提案されました。

マルチエージェント・システム(MAS)において、すべてのタスクに高性能なモデルを割り当てると膨大なコストが発生し、逆に安価なモデルでは論理的な脆弱性によりタスク全体が失敗するという「コストパフォーマンスのパラドックス」を解決するため、軽量なニューラルルーターであるCASTERが提案されました。

本研究は、科学分野の複雑なマルチホップ質問応答において、反復的な検索と推論のループが、理想的な静的根拠(ゴールドコンテキスト)を上回る性能を発揮することを解明しました。11種類の最新大規模言語モデルを用いた実験の結果、反復的RAGは非推論特化型モデルにおいて最大25.