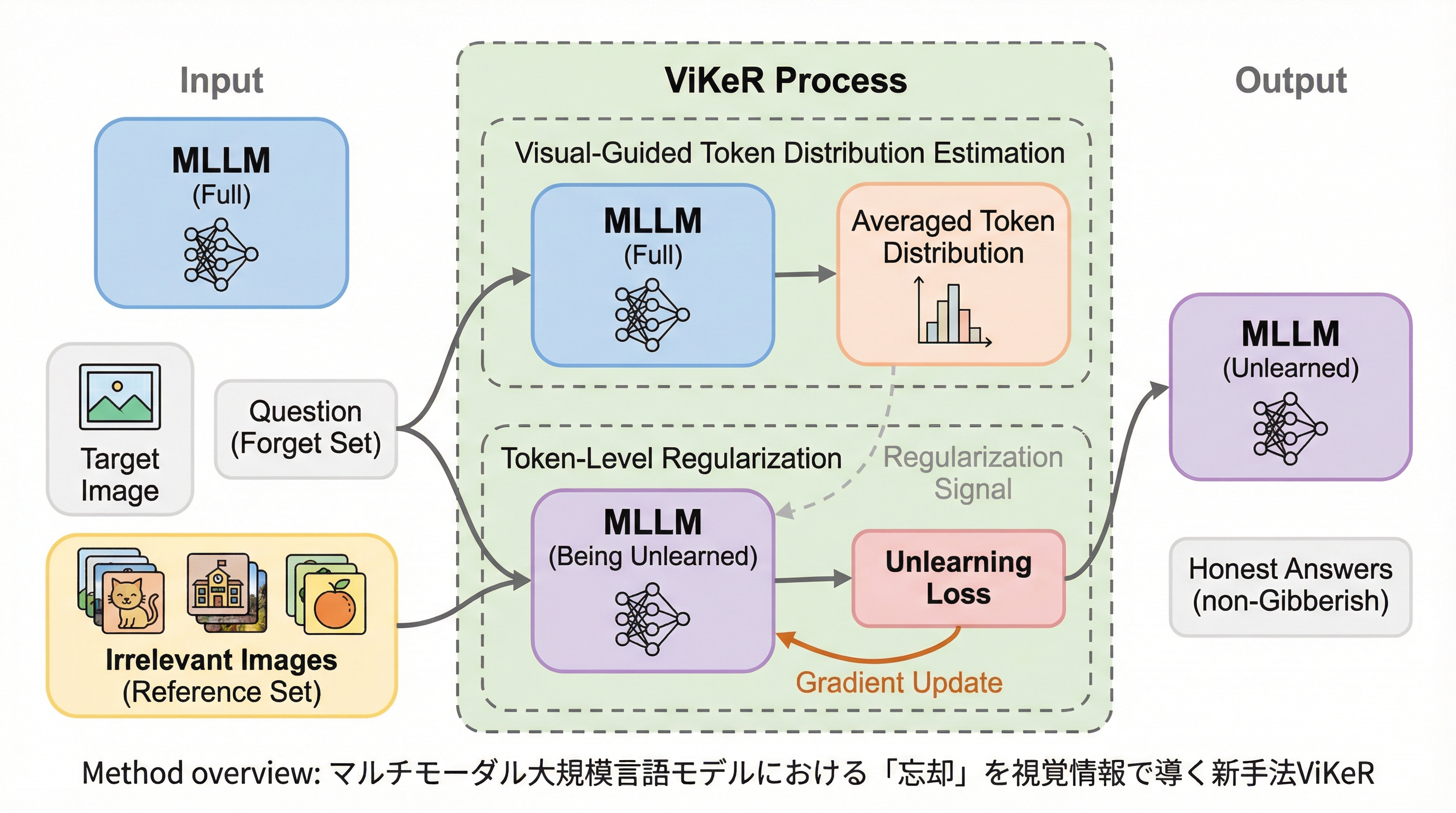
マルチモーダル大規模言語モデルにおける「忘却」を視覚情報で導く新手法ViKeR
マルチモーダル大規模言語モデル(MLLM)において、特定の個人情報や著作権データを消去する際、従来のテキストベースの手法では文法構造を司る単語まで損なわれ「This am」のような言語崩壊を招く課題があったが、本研究では視覚情報を手がかりに重要な情報を識別する新手法「ViKeR」を提案した。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
マルチモーダル大規模言語モデル(MLLM)において、特定の個人情報や著作権データを消去する際、従来のテキストベースの手法では文法構造を司る単語まで損なわれ「This am」のような言語崩壊を招く課題があったが、本研究では視覚情報を手がかりに重要な情報を識別する新手法「ViKeR」を提案した。
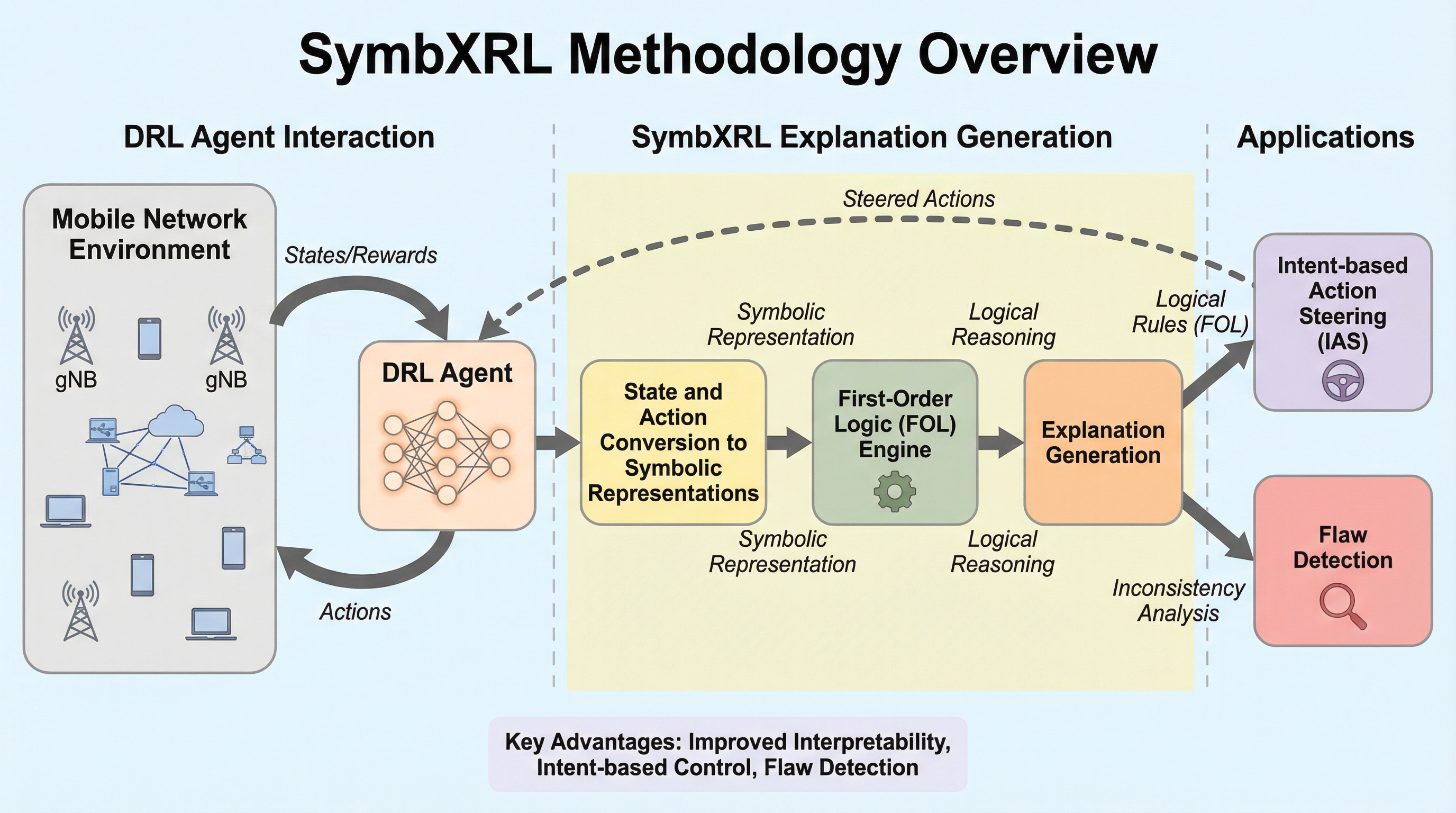
将来の6Gネットワーク管理において不可欠な深層強化学習(DRL)は、意思決定プロセスが不透明な「ブラックボックス」であるため、実際の運用現場への導入が困難という課題がある。 本研究が提案する「SymbXRL」は、一階述語論理(FOL)という記号AIの手法を用いて、DRLの複雑な数値データを人間が理解可能な記号や論理規則に変換し、直感的な説明とナレッジグラフを生成する。 実証実験では、ネットワークスライシングとMassive MIMOの制御において、既存手法を上回る解釈性を提供し、意図に基づく行動制御によって累積報酬を中央値で12%向上させることに成功した。
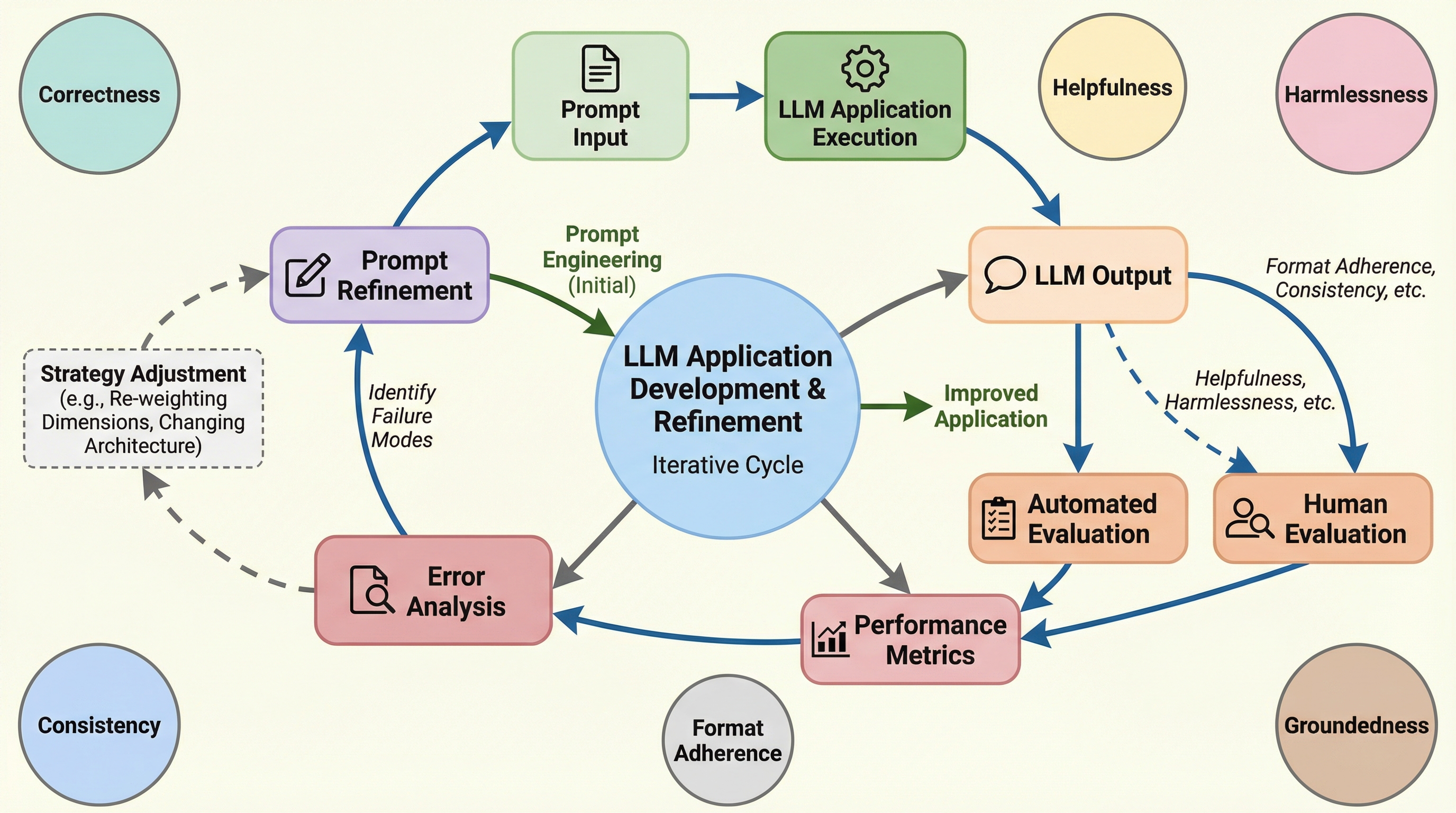
LLMの出力は非決定論的でモデル更新に敏感なため、従来の決定論的なテスト手法では不十分であり、「定義・テスト・診断・修正」の4フェーズからなる評価主導型の反復ワークフローを導入することで、場当たり的な調整から再現可能なエンジニアリングプロセスへの転換を提案する。
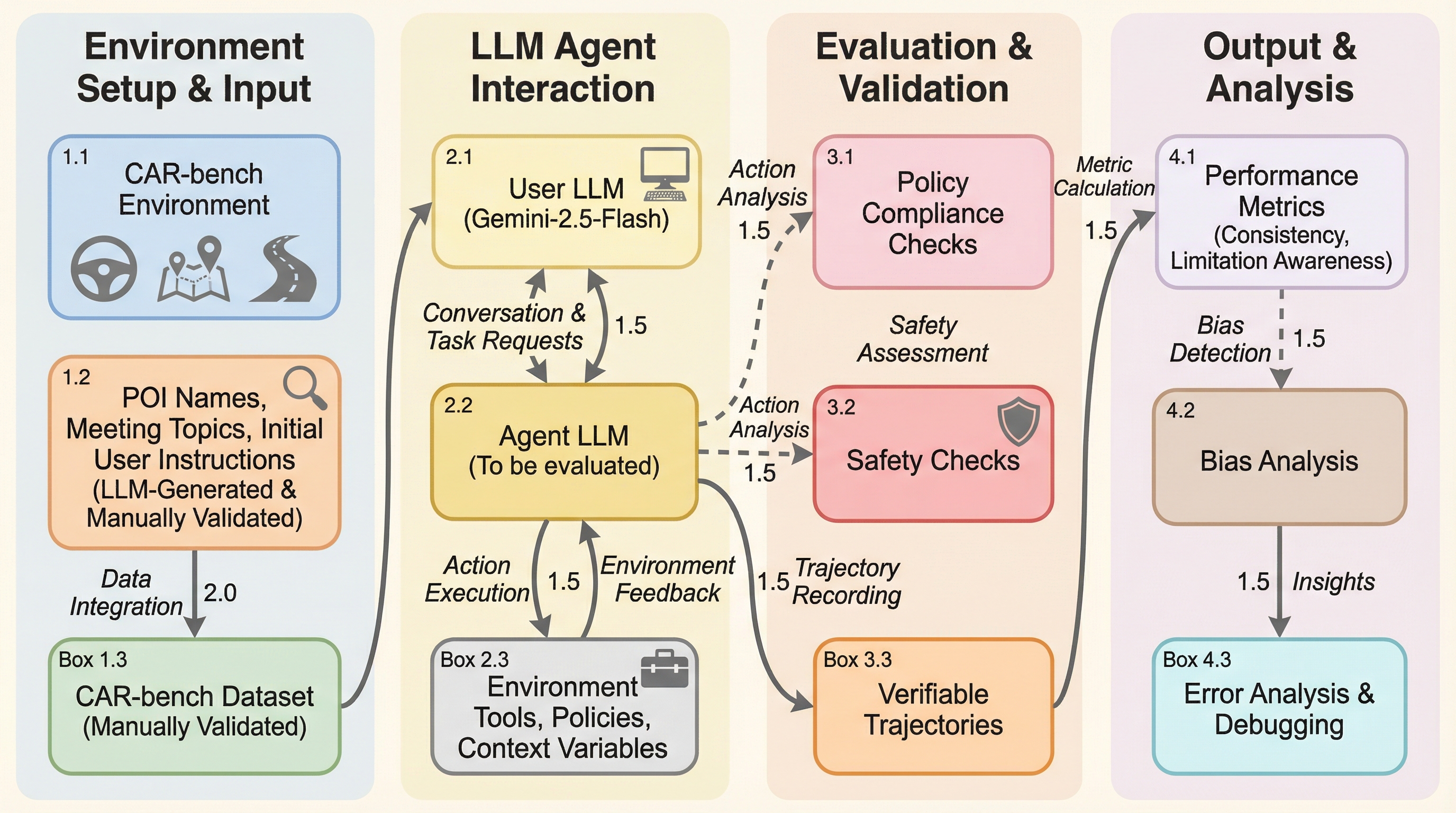
CAR-benchは、車載アシスタントという実世界の不確実な環境において、LLMエージェントの一貫性、不確実性への対処、および自身の能力限界の認識能力を評価するための新しいベンチマークである。従来のタスク完了重視の評価とは異なり、必要なツールや情報が欠落している場合に嘘をつかずに限界を認める「Hallucinationタスク」と、曖昧な要求を対話や内部検索で解消する「Disambiguationタスク」を導入している。最新の推論モデルを含む評価の結果、一度の成功(Pass@3)と常に成功すること(Pass^3)の間には大きな乖離があり、特に曖昧さの解消においては一貫した成功率が50%を下回るなど、実用化に向けた信頼性の課題が浮き彫りになった。エージェントが「何ができるか」だけでなく「何ができないか」を正しく認識することの重要性を、本ベンチマークは定量的に示している。
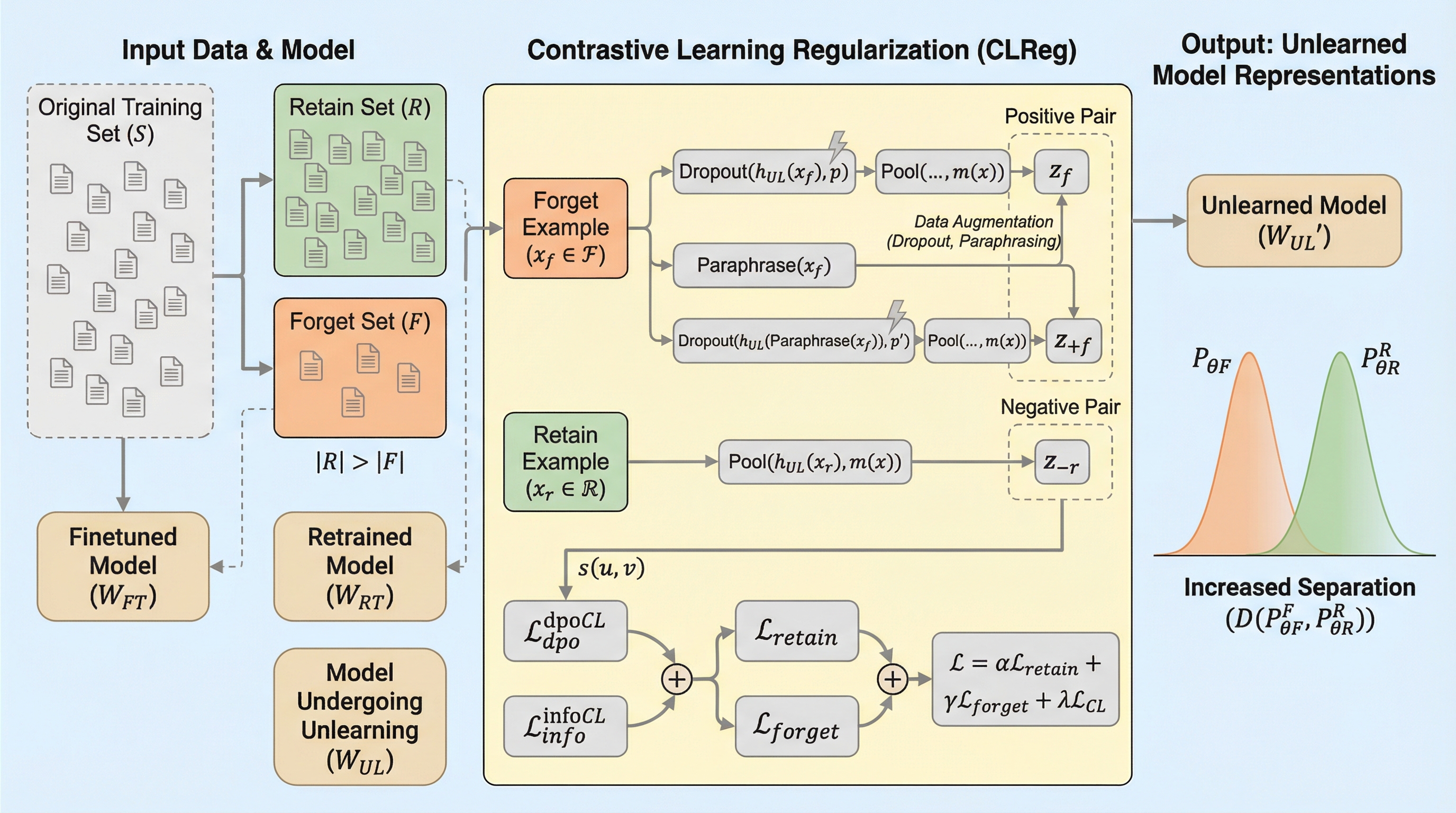
大規模言語モデル(LLM)のアンラーニングにおいて、従来の出力確率(Logits)を調整する手法は、忘却すべき概念を内部表現(Latents)に残存させ、保持すべき知識と絡み合わせる「抑制」に留まるという課題があった。
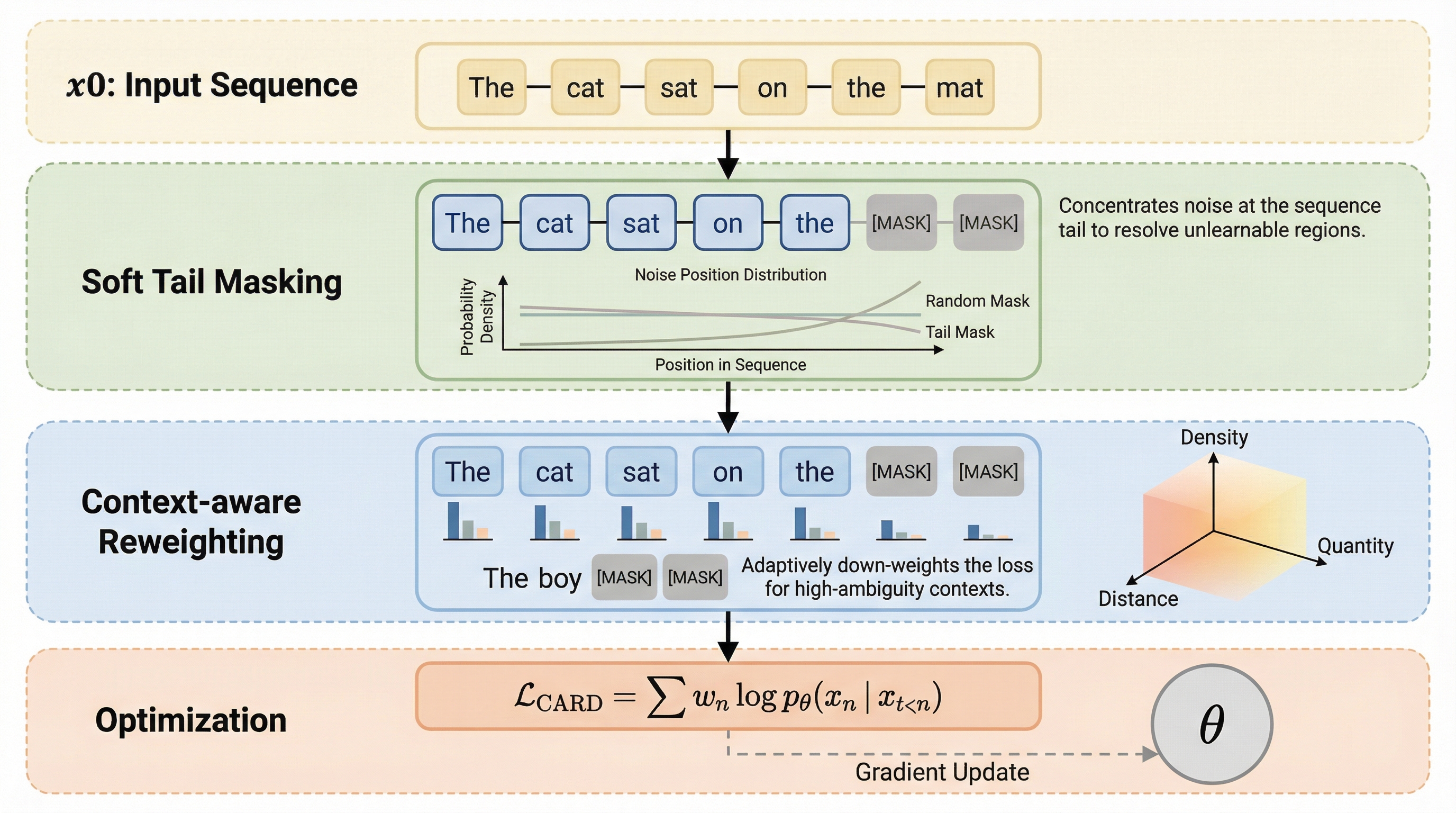
CARD(Causal Autoregressive Diffusion)は、自己回帰モデルの安定した訓練効率と拡散モデルの高速な並列推論を、因果的アテンションマスクという単一の枠組みで統合した革新的な言語モデルである。
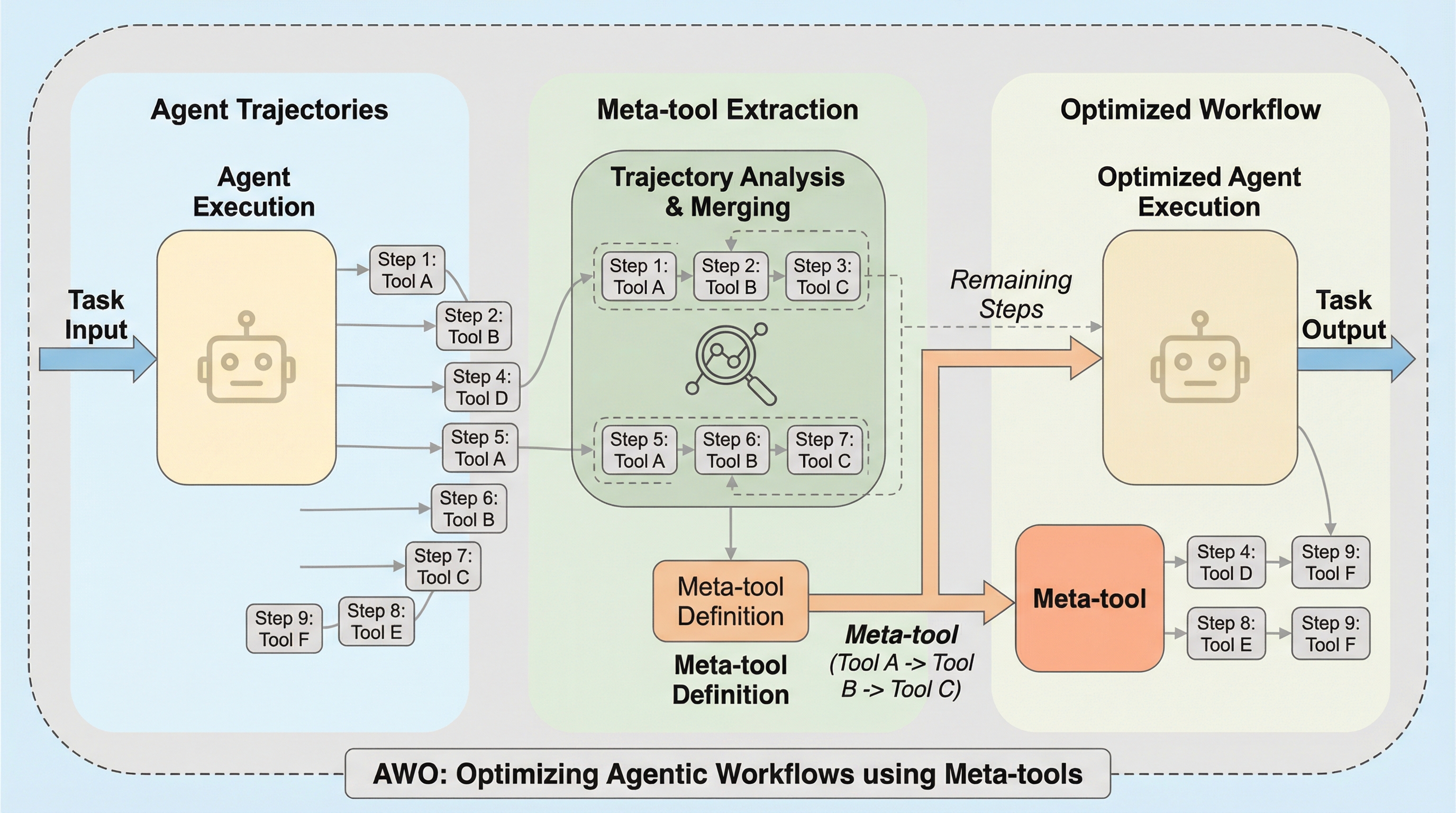
エージェント型AIは大規模言語モデル(LLM)が推論とツール実行を繰り返すことで複雑な課題を解決しますが、反復的な推論ステップが過剰な運用コストや遅延、ハルシネーションによる失敗を招くという課題があります。
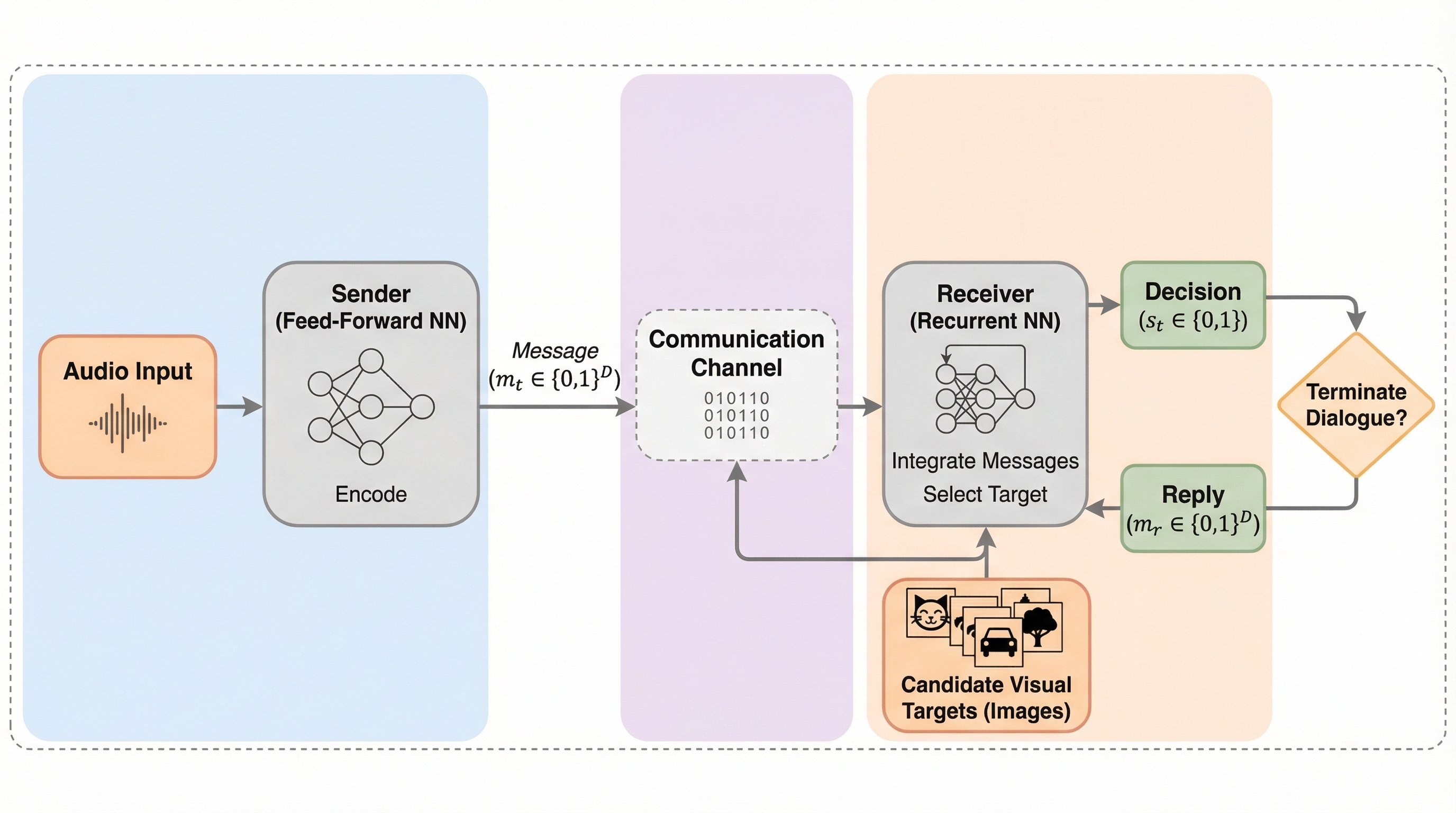
本研究は、送信者が「音声」を聞き、受信者が「画像」を見るという、互いに異なる知覚モダリティ(感覚器)を持つ異種マルチエージェント間において、共通の知覚基盤がない状態からどのようにコミュニケーションが創発するかを調査したものです。
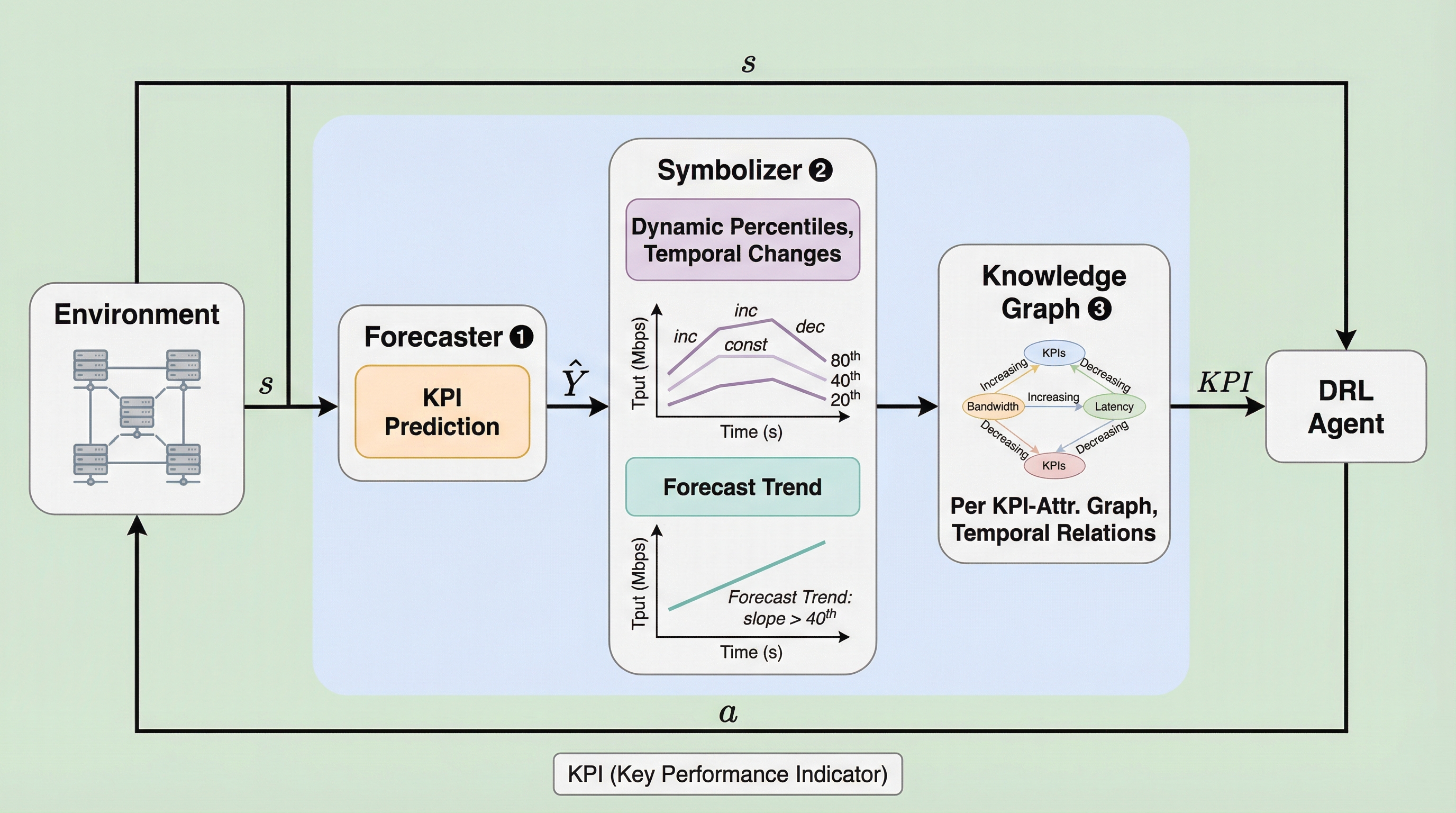
SIAは、予測情報を活用する深層強化学習(DRL)エージェントの意思決定プロセスをリアルタイムで可視化し、人間が理解可能な形式で解釈可能にする新しいフレームワークである。記号的AIの抽象化概念とKPIごとの独立した知識グラフを融合することで、現在の観測データと将来の予測データが行動に与える影響を個別に分離して評価する「影響スコア(IS)」を導入し、既存手法より200倍以上の高速化を達成した。ビデオストリーミングやRANスライシングなどの検証において、エージェントの設計ミスを特定してビットレートを9%向上させ、さらに再学習なしで報酬を25%改善することに成功し、予測型制御の信頼性と性能を大幅に高めている。
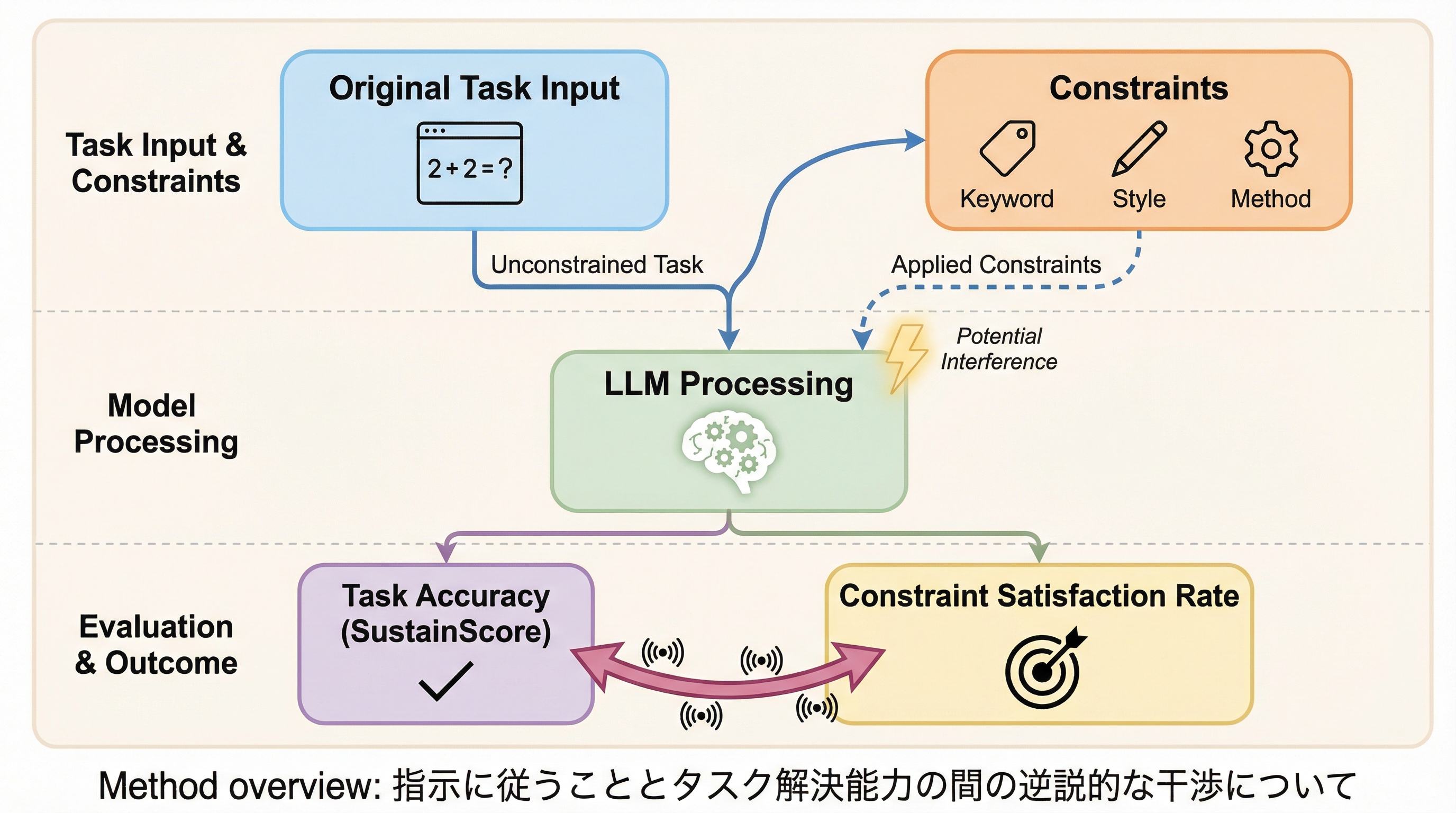
大規模言語モデル(LLM)において、ユーザーの指示や制約を遵守しようとする能力(指示追従)が、モデルが本来持っているはずのタスク解決能力をかえって阻害してしまう「逆説的な干渉」という現象が本研究によって明らかになりました。