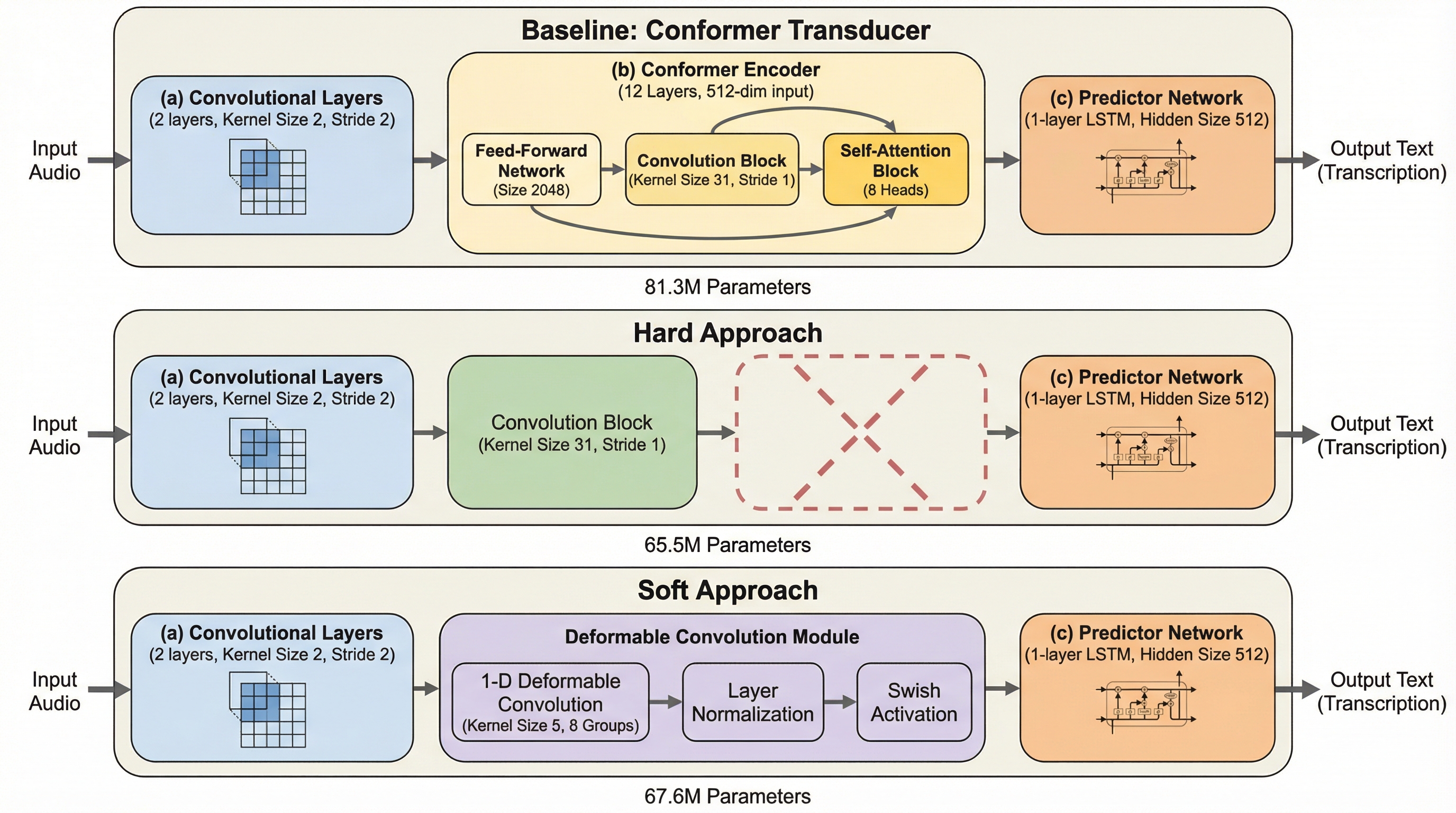
ストリーミング自動音声認識にSelf-Attentionは本当に必要なのか?
ストリーミング自動音声認識(ASR)において、Self-Attentionは全域的な依存関係を捉える設計でありながら、実際にはチャンク内の局所的な情報処理に終始していることが判明しました。 本研究では、Self-Attentionを軽量な可変形畳み込み(Deformable Convolution)に置き換える「ソフト手法」と、完全に削除する「ハード手法」を提案し、計算コストを大幅に削減しました。 LibriSpeech等のデータセットを用いた検証の結果、単語誤り率(WER)の悪化を最小限に抑えつつ、パラメータ数を最大19.4%削減し、GPU上での処理速度を約2倍に高速化することに成功しました。