APC-RL: 適応的な方策合成でデータ駆動型の事前分布を超える強化学習手法
従来の強化学習におけるデモンストレーションの活用は、データが最適かつタスクに完全に適合していることを前提としていたが、現実の不完全なデータでは性能が低下するという課題があった。 本研究が提案するAPC(Adaptive Policy Composition)は、複数の正規化流を用いた事前分布を持つアクターと、事前分布を一切持たないアクターを階層的に組み合わせ、オンラインの報酬に基づいて適切な行動を適応的に選択する。 実験の結果、APCはデモンストレーションが不適合な場合でも堅牢性を維持し、適合している場合には学習を大幅に加速させ、さらに不完全なデータからでも最適な行動を導き出すことが確認された。
TL;DR(結論)
従来の強化学習におけるデモンストレーションの活用は、データが最適かつタスクに完全に適合していることを前提としていたが、現実の不完全なデータでは性能が低下するという課題があった。 本研究が提案するAPC(Adaptive Policy Composition)は、複数の正規化流を用いた事前分布を持つアクターと、事前分布を一切持たないアクターを階層的に組み合わせ、オンラインの報酬に基づいて適切な行動を適応的に選択する。 実験の結果、APCはデモンストレーションが不適合な場合でも堅牢性を維持し、適合している場合には学習を大幅に加速させ、さらに不完全なデータからでも最適な行動を導き出すことが確認された。
なぜこの問題か
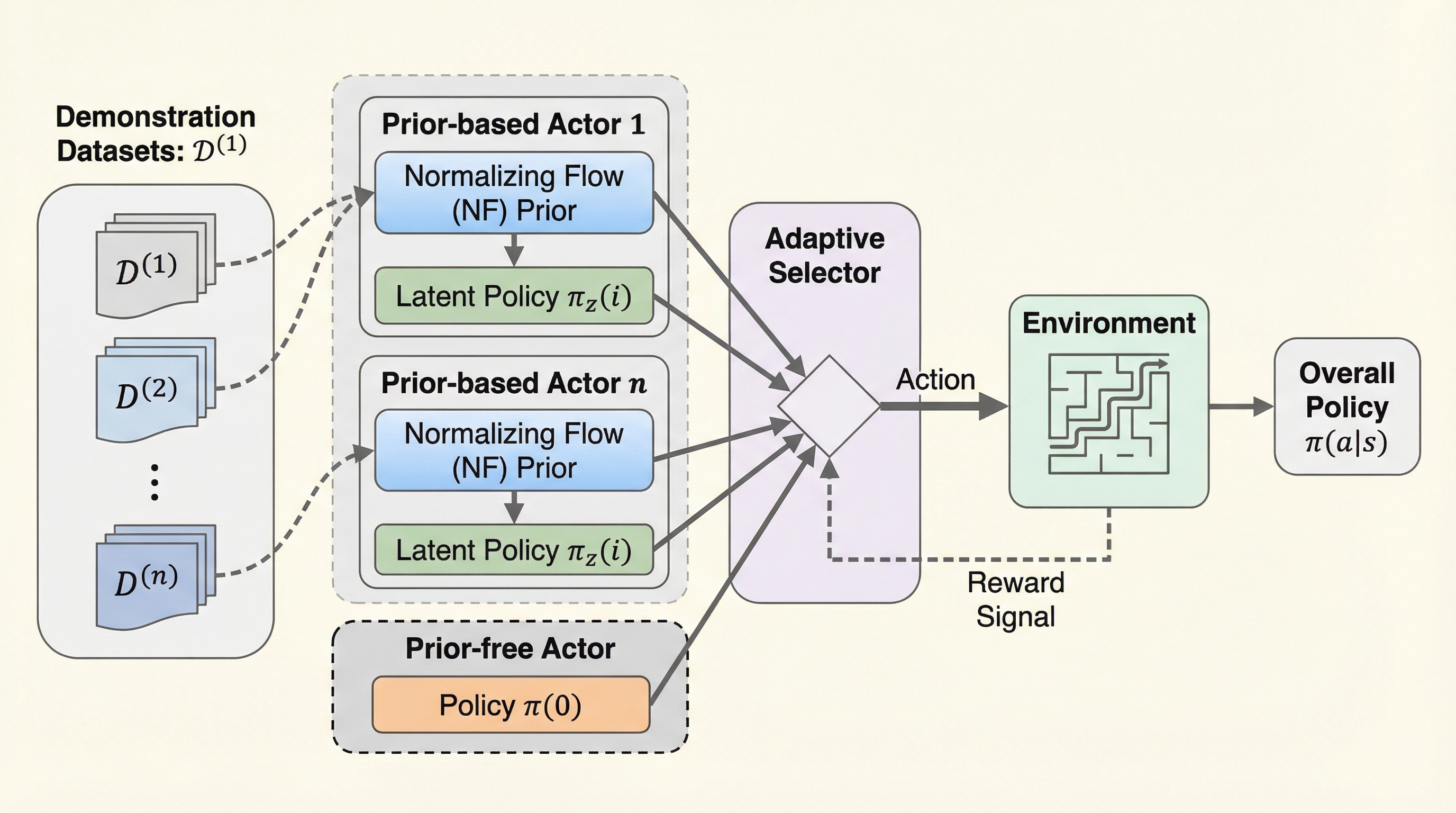
強化学習において、デモンストレーションデータを組み込むことは学習を劇的に加速させる有効な手段である。しかし、既存の手法の多くは、提供されるデモンストレーションが最適であり、かつ目標とするタスクと完全に一致しているという暗黙の、しかし極めて重要な仮定を置いている。現実のシナリオにおいて、デモンストレーションは疎(スパース)であったり、最適ではなかったり、あるいは目標タスクと整合していなかったりすることが頻繁に起こる。このような不完全なデータを強化学習に統合すると、エージェントが不適切な行動に固執してしまい、結果として性能が著しく低下するという問題が生じる。 特に、デモンストレーションデータに厳格に従うように方策を正規化する手法や、デモンストレーションの行動を生成モデルで模倣する手法では、データセットとオンラインの強化学習タスクが不整合(ミスアライメント)である場合に失敗の主な原因となる。これは、データが不完全であるにもかかわらず、エージェントがそのデータから逸脱することを制限されてしまうためである。…
核心:何を提案したのか
著者らは、Adaptive Policy Composition(APC)と呼ばれる新しい階層的な強化学習アプローチを提案した。APCの核心は、複数のデータ駆動型の事前分布(Normalizing Flowを用いたもの)と、事前分布を一切持たないアクターを適応的に合成する仕組みにある。このモデルは、上位レベルの「セレクター」と、下位レベルの複数の「アクター」で構成されている。 APCの最大の特徴は、下位レベルのアクターの中に、必ず「事前分布を持たないアクター(prior-free actor)」を一つ含めている点である。これにより、もし提供されたデモンストレーションが現在のタスクに全く役に立たない場合でも、エージェントはデモンストレーションから完全に離脱して、報酬フィードバックのみからゼロから学習を進める柔軟性を確保している。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related