観測からイベントへ:強化学習のためのイベント認識型世界モデル
従来のモデルベース強化学習が抱えていた、生のピクセル情報への過度な依存やノイズに対する脆弱性を克服するため、人間の認知機能を模倣して連続的な観測を意味のある「イベント」として切り出す「イベント認識型世界モデル(EAWM)」が提案されました。
TL;DR(結論)
従来のモデルベース強化学習が抱えていた、生のピクセル情報への過度な依存やノイズに対する脆弱性を克服するため、人間の認知機能を模倣して連続的な観測を意味のある「イベント」として切り出す「イベント認識型世界モデル(EAWM)」が提案されました。 このフレームワークは、適応的ガウス混合モデルなどを用いてラベルなしで自動的にイベントを生成し、イベント境界を特定するセグメンターを通じて、タスクに重要な時空間的変化を捉える簡潔な潜在表現を学習することで、予測の困難な不確実性を排除します。 Atari 100KやDeepMind Controlなどの主要ベンチマークにおいて、既存の強力な手法を10%から45%上回る性能向上を達成し、特に複雑な動的変化を伴うタスクや未知の視覚的変動がある環境において、新しい最先端の記録を樹立しました。
なぜこの問題か
モデルベース強化学習(MBRL)は、環境の動態を学習する世界モデルを構築し、その中での想像上の試行錯誤を通じて学習を進めることで、実環境との相互作用回数を減らす手法として注目されています。しかし、既存の多くの手法は、生の観測データ、特にピクセル単位の情報をそのまま再現することに固執しており、これがいくつかの深刻な課題を引き起こしています。まず、現在の世界モデルは、テクスチャや色の変化といった、タスクの本質とは無関係な視覚的変動に対して非常に脆弱です。これにより、構造的に類似したシーンであっても、背景が少し変わるだけで汎化性能が著しく低下するという問題が生じています。 また、確率的な環境において生の観測値を正確に予測することは、理論的に極めて困難な課題です。例えば、コインを投げる前にその結果をピクセルレベルで予測することは不可能であり、このような本質的な不確実性が存在する中で全ての情報を予測しようとすると、モデルの学習が不安定になり、長期的な予測精度が低下します。これに対し、生物学的なシステム、特に人間の脳は、連続的な感覚入力をそのまま処理するのではなく、意味のある「イベント」として断片化して認識しています。…
核心:何を提案したのか
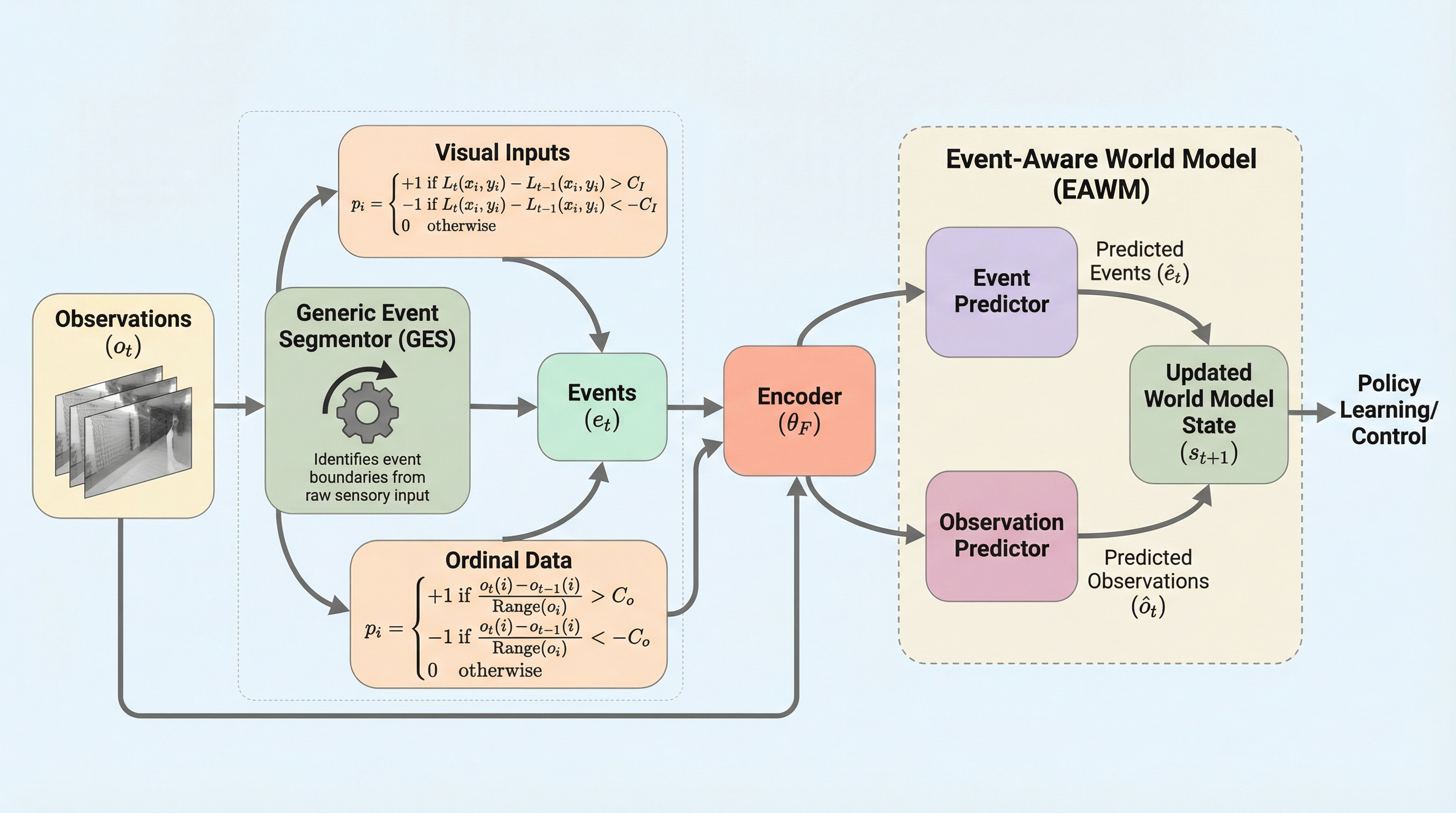
本研究では、生の観測データからコンパクトな運動学的特徴を学習する汎用的なフレームワーク「イベント認識型世界モデル(EAWM)」を提案しています。このフレームワークの最大の特徴は、手動のラベル付けを一切必要とせずに、環境からの観測ストリームを自動的にイベントへと変換し、それを世界モデルの学習プロセスに直接組み込む点にあります。EAWMは、特定のニューラルネットワークの構造に依存しない統一的な定式化を採用しており、DreamerV3やSimulusといった既存の強力な世界モデルに対して、最小限の調整で統合することが可能です。 具体的には、EAWMは2つの主要な革新的コンポーネントを導入しています。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related