RPO:部分的推論最適化を用いた強化学習ファインチューニング
大規模言語モデルの強化学習において、推論の全行程を毎回ゼロから生成する非効率性を解消するため、過去の正解パスの接頭辞を再利用して末尾のみを生成・最適化する「RPO(部分的推論最適化)」が提案されました。 この手法は、キャッシュされた成功例をヒントとして活用することで、トレーニング中のトークン生成量を約95%削減し、1.
TL;DR(結論)
大規模言語モデルの強化学習において、推論の全行程を毎回ゼロから生成する非効率性を解消するため、過去の正解パスの接頭辞を再利用して末尾のみを生成・最適化する「RPO(部分的推論最適化)」が提案されました。 この手法は、キャッシュされた成功例をヒントとして活用することで、トレーニング中のトークン生成量を約95%削減し、1.5Bモデルで90%、7Bモデルで72%という劇的な学習時間の短縮と計算リソースの節約を実現しています。 既存のGRPOやDAPOに容易に組み込める設計であり、学習の不安定性や推論の崩壊を抑制しながら、主要な数学・推論ベンチマークにおいて従来手法を上回る性能向上と、多ステップ学習における高い安定性を達成しました。
なぜこの問題か
大規模言語モデル(LLM)の推論能力を飛躍的に向上させる手法として、強化学習(RL)を用いたポストトレーニング、特に思考の連鎖(CoT)を組み合わせるアプローチが注目されています。しかし、既存の強化学習ファインチューニングには、計算コストと学習の安定性の両面で深刻な課題が残されています。第一の課題は、計算リソースの極めて非効率的な利用です。従来のアルゴリズムでは、モデルが入力クエリに対して推論の全行程を毎回ゼロから生成する必要があります。このサンプリング(ロールアウト)段階では膨大な数のトークンが生成されますが、すべてのサンプルが完成するまでパラメータの更新を行うことができません。その結果、GPUなどの計算リソースの稼働率が低下し、学習に膨大な時間を要することになります。 第二の課題は、報酬の疎(スパース)性と学習の不安定性です。数学や論理推論のタスクでは、最終的な答えが正しいかどうかに基づいて報酬が与えられることが多く、途中の推論ステップに対するきめ細かなフィードバックが欠如しています。…
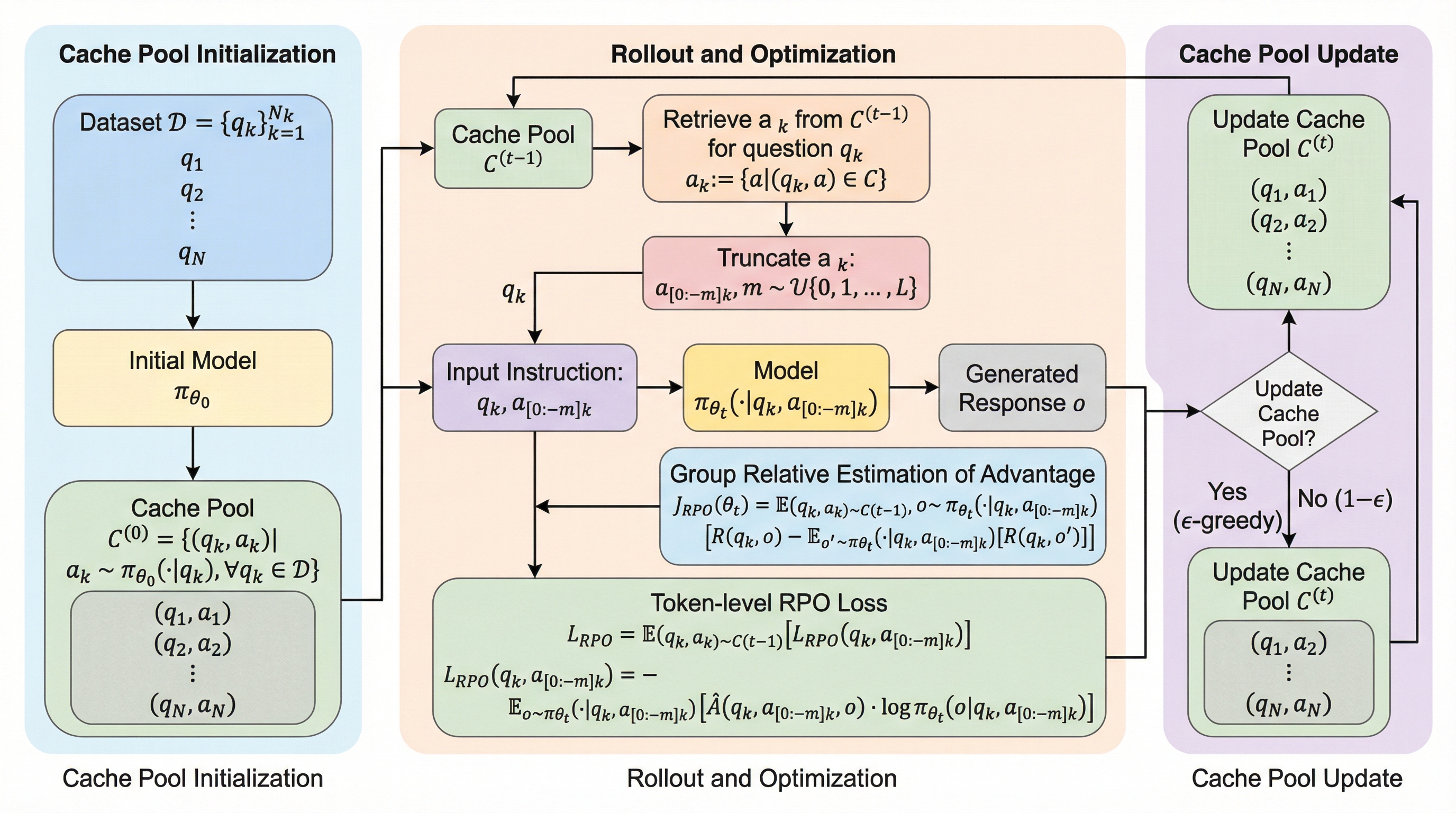
核心:何を提案したのか
本研究では、推論パス全体を毎回生成するのではなく、過去の成功体験を活用して推論の「続き」だけを最適化する「RPO(Reinforcement Fine-Tuning with Partial Reasoning Optimization)」というアルゴリズムを提案しています。これは、経験再生(Experience Replay)の概念を言語モデルの強化学習に導入した、プラグアンドプレイ型のフレームワークです。RPOの核心的なアイデアは、正解に至った推論パスの初期トークン(接頭辞)は、モデルを正しい推論の軌跡へと導く重要なガイドになるという洞察に基づいています。実験の結果、推論パスを途中で切り取った接頭辞をモデルに与え、そこから先の推論を完結させる訓練を行うだけでも、モデル全体として最初から最後まで正しい推論を行う能力を効果的に学習できることが判明しました。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related