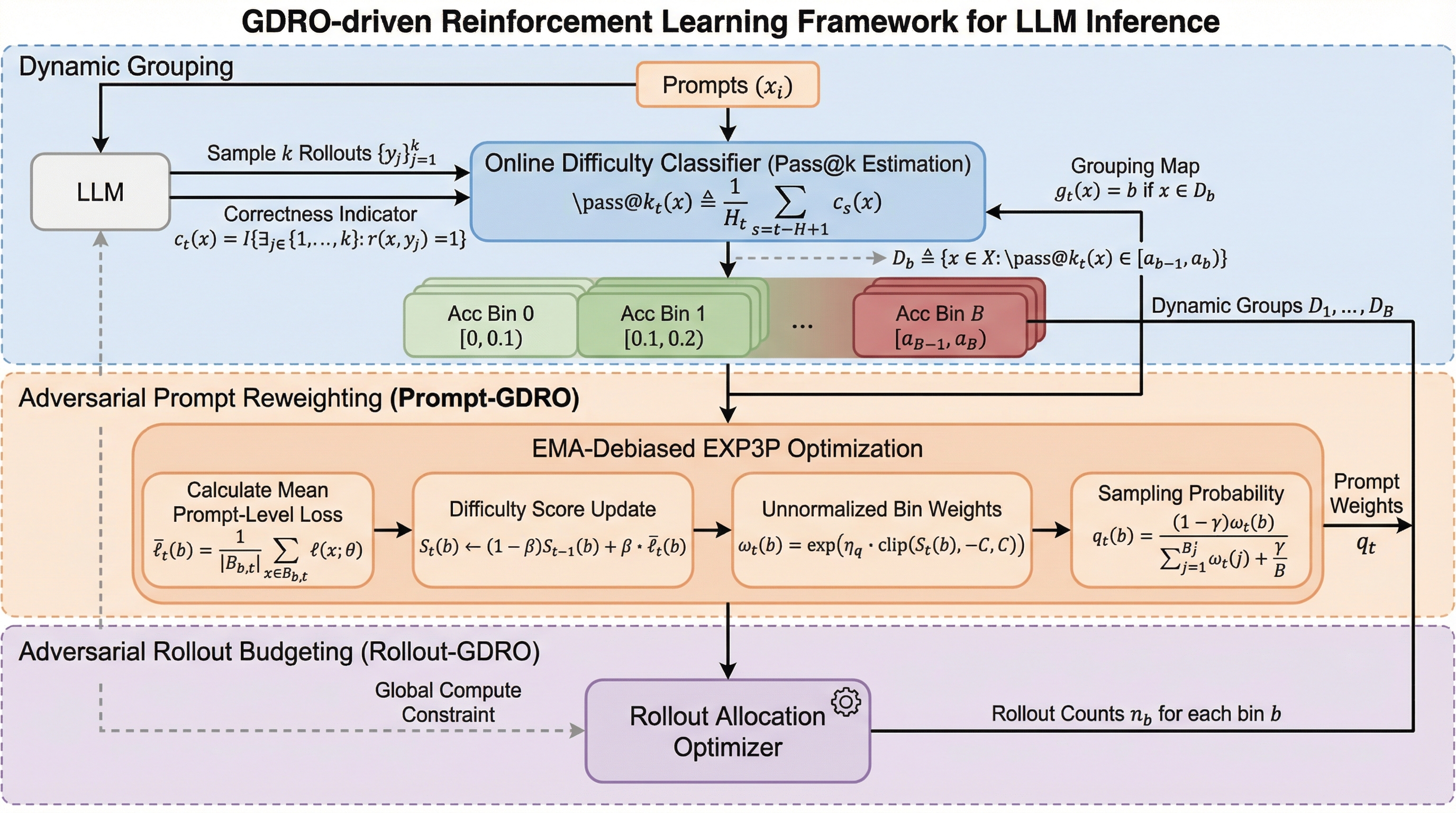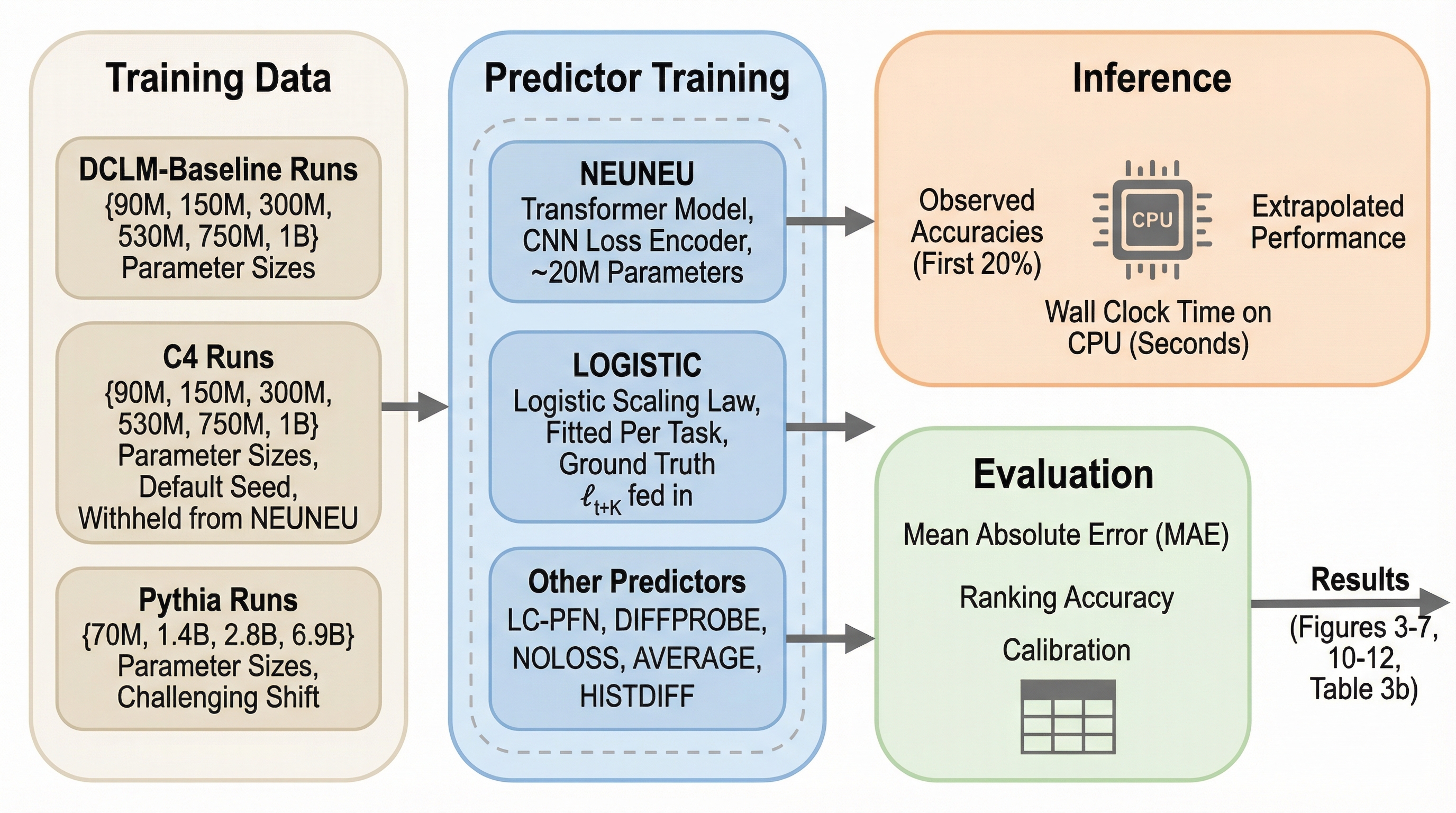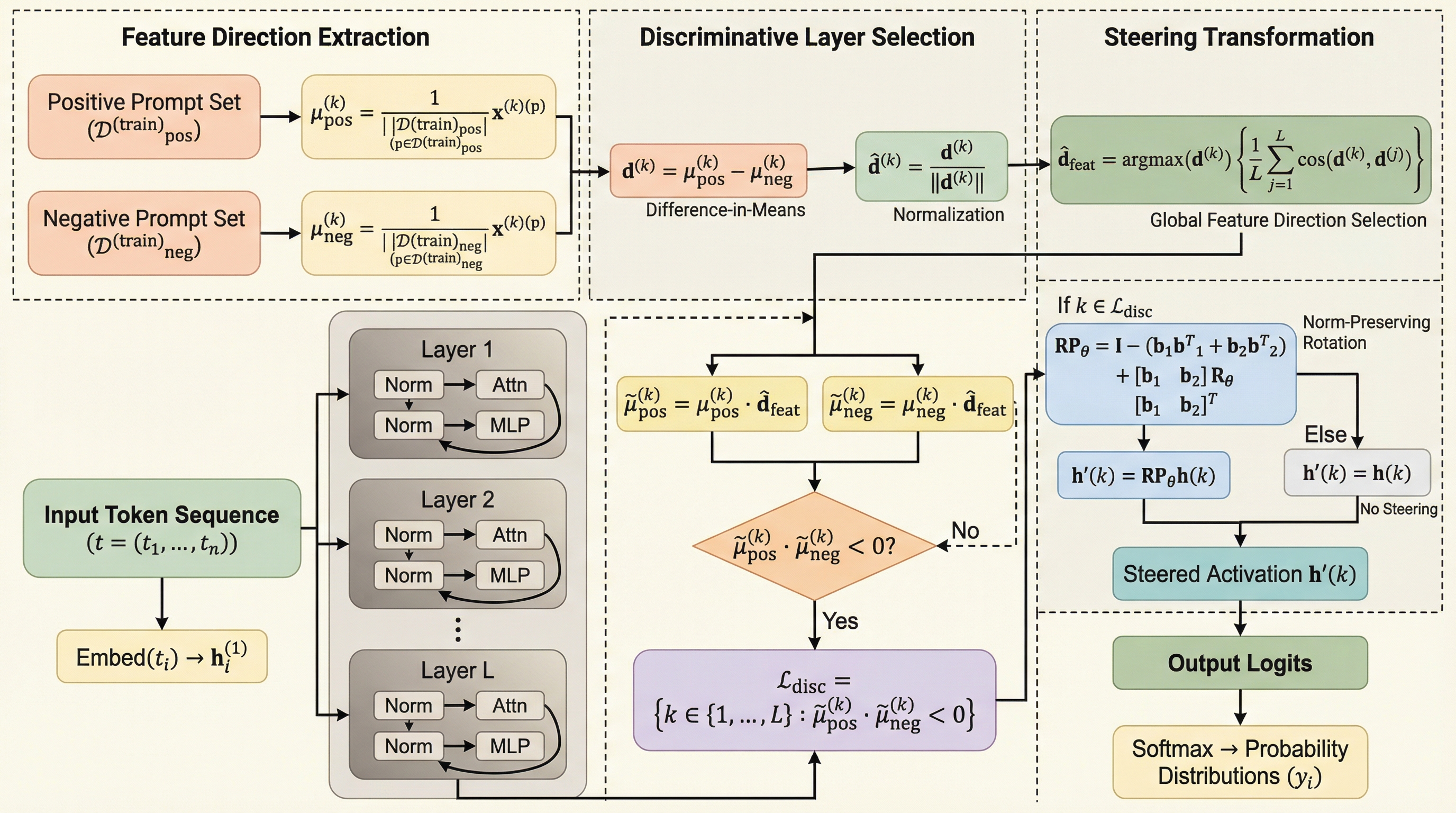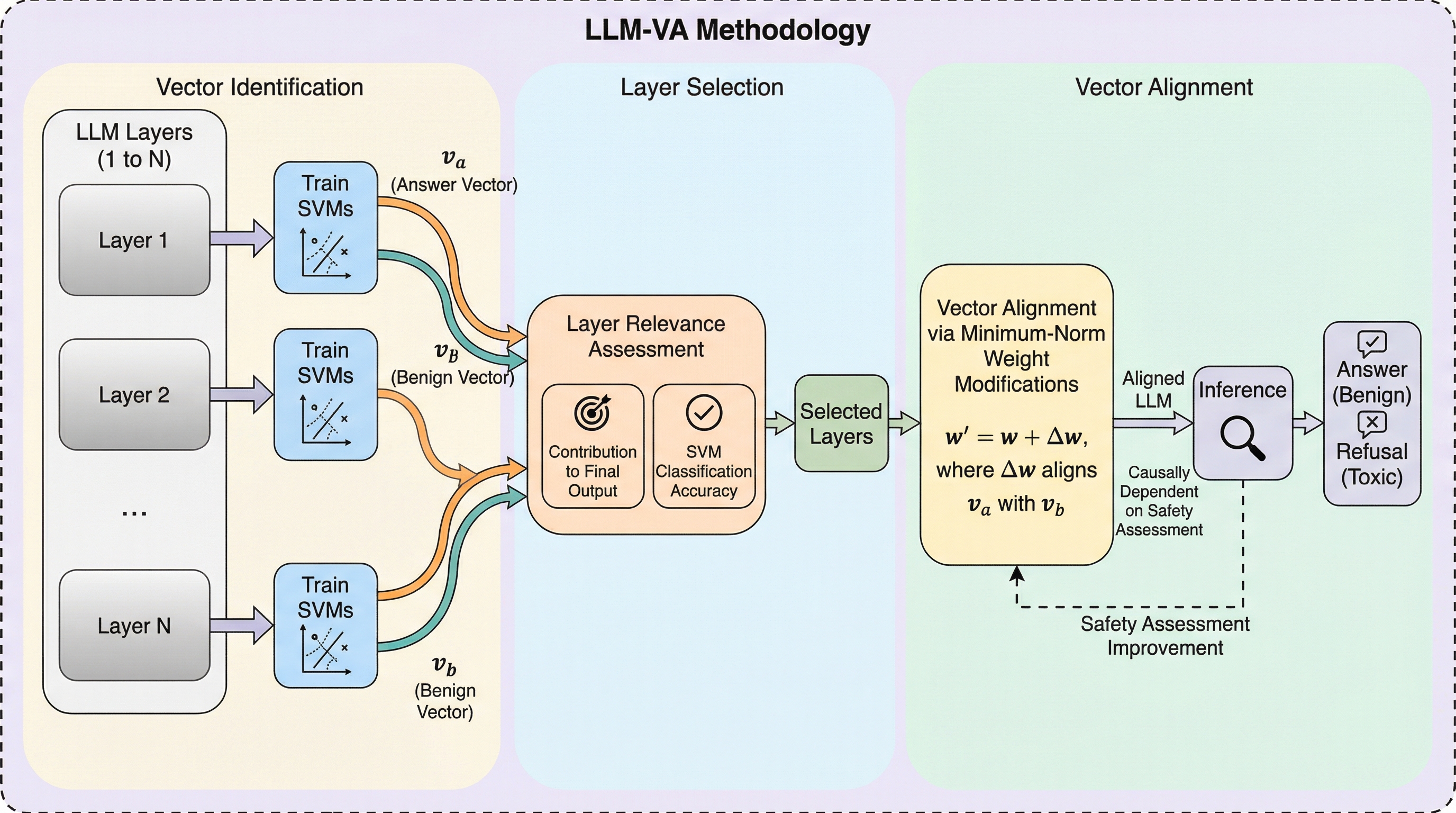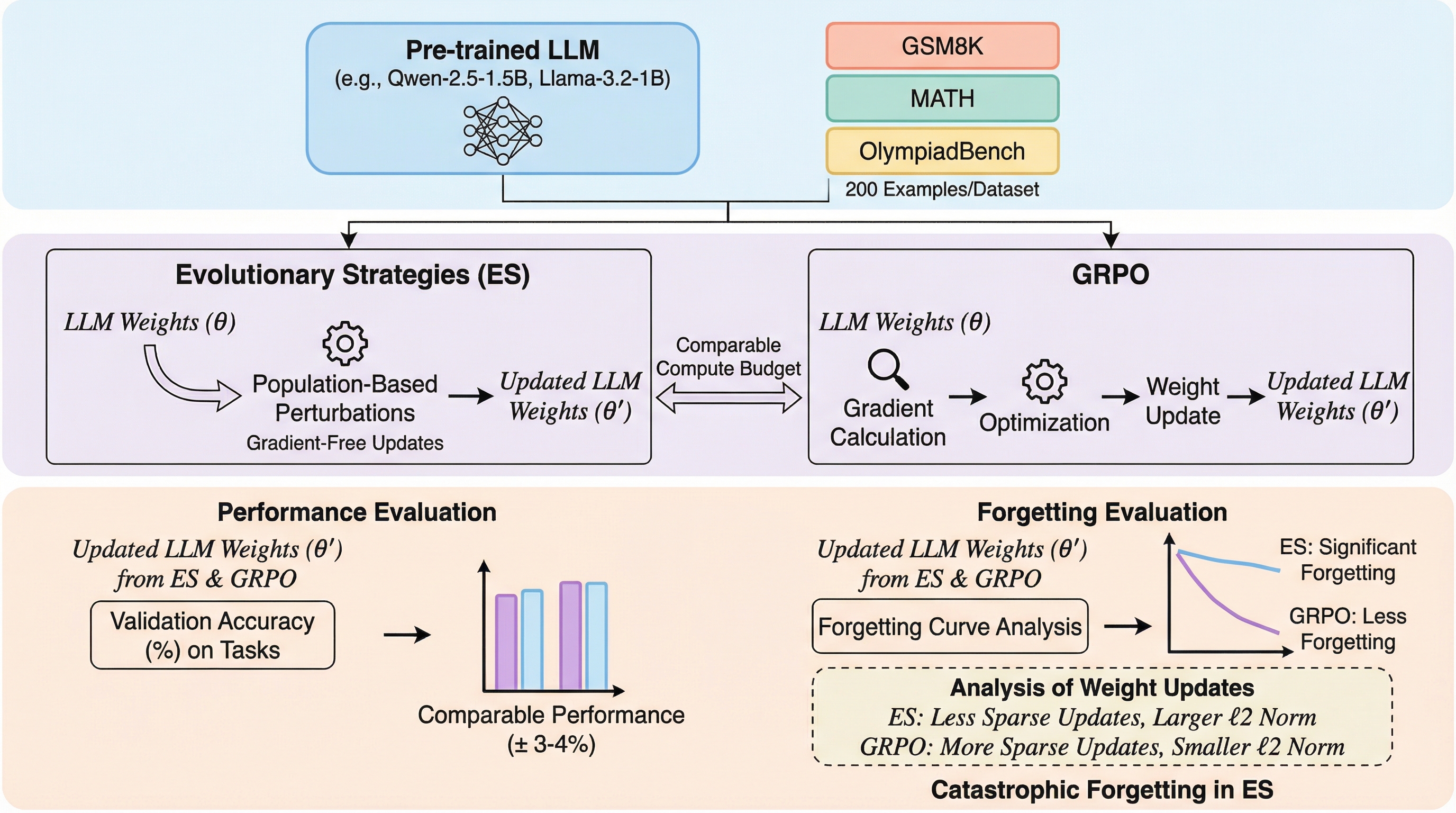
進化戦略はLLMにおける破滅的忘却を引き起こす
進化戦略(ES)は、従来の勾配ベースの手法であるGRPOと比較して、数学や推論タスクにおいて同等の性能を達成しつつ、メモリ消費を大幅に抑えられる可能性を秘めています。 しかし、本研究の分析により、ESを用いた学習はモデルが既に持っていた既存の知識を急速に失わせる「破滅的忘却」を引き起こし、特定のタスクに特化する一方で汎用性が著しく低下することが判明しました。 この忘却の原因は、ESによるパラメータ更新がGRPOに比べて1000倍も大きなノルムを持ち、かつモデル全体にわたる高密度な変更を加えることで、既存の知識構造を破壊してしまう点にあると結論付けられています。