トランスフォーマーはどのようにトークンを関連付けるのか:勾配の主要項がもたらす機械論的解釈可能性
本研究は、自己注意機構を持つトランスフォーマーが訓練を通じてトークン間の意味的関連性を獲得するプロセスを、勾配の主要項近似という手法を用いて理論的に解明した。重み行列は「バイグラム」「トークン互換性」「文脈」という3つの基底関数の単純な合成として閉形式で表現可能であり、これがモデルの内部構造を決定づけていることを明らかにした。実世界のデータを用いた検証により、この理論的な重みの特徴付けが実際の大規模言語モデルの挙動や学習された重みと密接に一致することが確認され、ブラックボックスとされるモデルの機械論的な基礎を提示した。
TL;DR(結論)
本研究は、自己注意機構を持つトランスフォーマーが訓練を通じてトークン間の意味的関連性を獲得するプロセスを、勾配の主要項近似という手法を用いて理論的に解明した。重み行列は「バイグラム」「トークン互換性」「文脈」という3つの基底関数の単純な合成として閉形式で表現可能であり、これがモデルの内部構造を決定づけていることを明らかにした。実世界のデータを用いた検証により、この理論的な重みの特徴付けが実際の大規模言語モデルの挙動や学習された重みと密接に一致することが確認され、ブラックボックスとされるモデルの機械論的な基礎を提示した。
なぜこの問題か
自己注意機構を基盤とする大規模言語モデルは、事実に関する知識や人間世界の質的な側面を捉える驚異的な能力を示しているが、その内部でどのような構造が学習されているのかを理解することは依然として困難である。特に「鳥」と「飛ぶ」といったトークン間の意味的な関連性は、言語モデルが単なる配列の暗記を超えて、未知の文脈への汎化や一貫したテキスト生成を行うための基礎となる要素である。言語学の分野では、分布意味論の観点からこれらの関連性が古くから議論されてきたが、現代のトランスフォーマーにおいて、これらの構造が勾配ベースの最適化を通じて膨大なコーパスからどのように結晶化していくのかについては、原理的な説明が不足していた。 先行研究の多くは、この問題を分析するために、現実とはかけ離れた設定を採用せざるを得なかった。例えば、合成された構造化データを用いたり、位置エンコーディングや残差接続を排除した簡略化されたモデルアーキテクチャを用いたり、あるいは一部の重みを凍結するなどの非標準的な訓練手法を用いたりしていた。このような制約は、理論的な洞察を実用的な大規模言語モデルへ適用する際の大きな障壁となっていた。…
核心:何を提案したのか
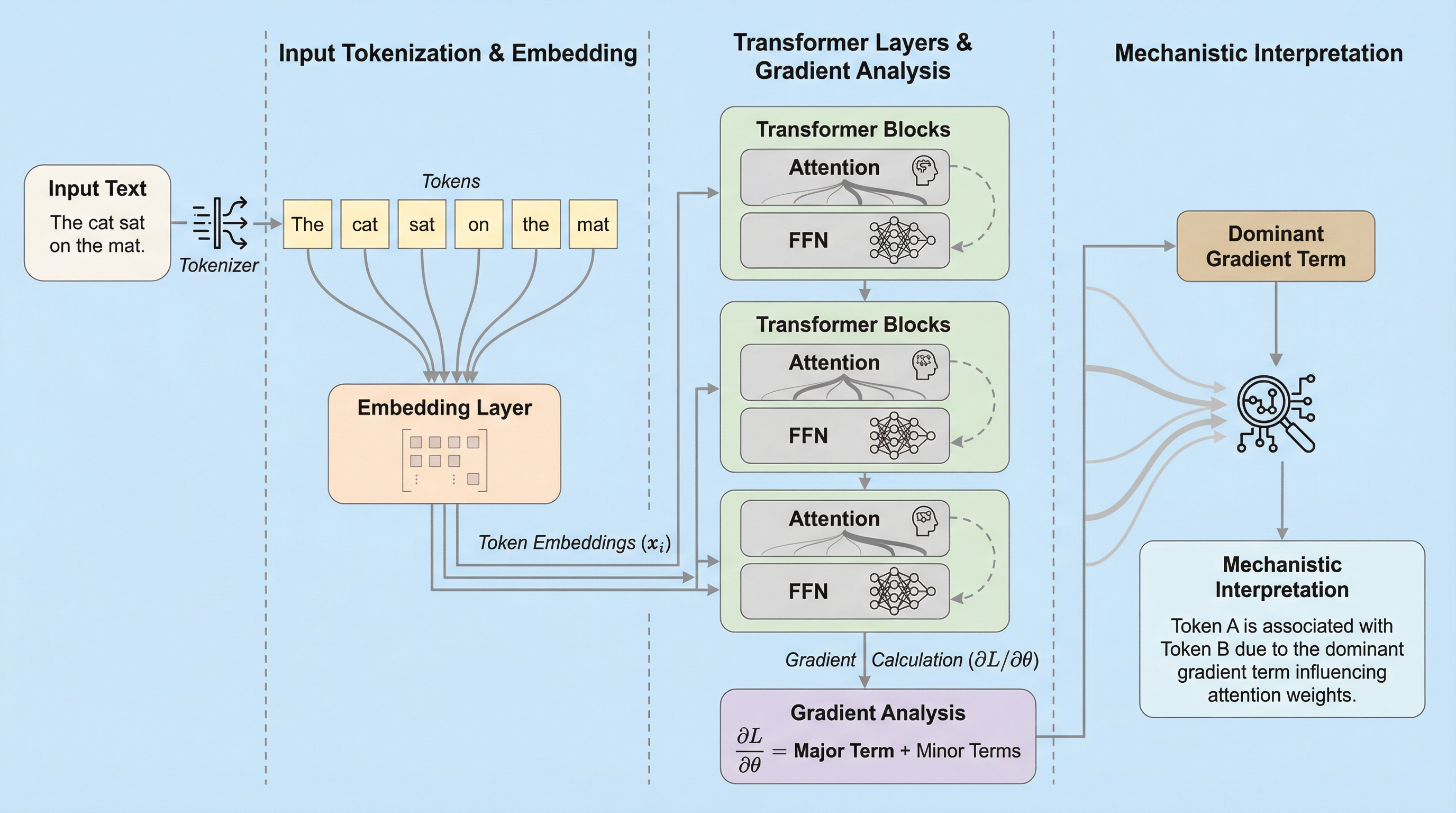
本研究の核心的な提案は、トランスフォーマーの訓練ダイナミクスを「勾配の主要項」の展開を通じて分析し、重み行列を解釈可能な数式として導出したことである。トランスフォーマーは訓練の非常に早い段階で、意味関係の把握や推論能力の基礎となる構造を獲得することが知られている。この初期段階においては、勾配の更新が閉形式で近似可能であり、高次の補正項が蓄積する前のパラメータ更新を支配的に説明できるという特性がある。この分析により、学習された重み行列(出力行列、値行列、クエリ・キー行列、位置エンコーディング)が、コーパスの統計を反映した3つの基底関数の単純な組み合わせとして表現できることが明らかになった。 第一の基底関数は「バイグラム・マッピング」であり、これは次トークンの直接的な依存関係を捉える。第二は「トークン互換性マッピング」であり、類義語や共通の文法役割を持つトークン間の機能的な類似性を反映する。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related